項目演示地址
項目演示地址
項目代碼結構
前言
React 框架的優雅不言而喻,組件化的編程思想使得React框架開發的項目代碼簡潔,易懂,但早期 React 類組件的寫法略顯繁瑣。React Hooks 是 React 16.8 發布以來最吸引人的特性之一,她簡化了原有代碼的編寫,是未來 React 應用的主流寫法。
本文通過一個實戰小項目,手把手從零開始帶領大家快速入門React Hooks。
在本項目中,會用到以下知識點:
- React 組件化設計思想
- React State 和 Props
- React 函數式組件的使用
- React Hooks useState 的使用
- React Hooks useEffect 的使用
- React 使用 Axios 請求遠程接口獲取問題及答案
- React 使用Bootstrap美化界面
Hello React
(1)安裝node.js 官網鏈接
(2)安裝vscode 官網鏈接
(3)安裝 creat-react-app 功能組件,該組件可以用來初始化一個項目, 即按照一定的目錄結構,生成一個新項目。
打開cmd 窗口 輸入:
npm install --g create-react-app
npm install --g yarn
(-g 代表全局安裝)
如果安裝失敗或較慢。需要換源,可以使用淘寶NPM鏡像,設置方法為:
npm config set registry https://registry.npm.taobao.org
設置完成后,重新執行
npm install --g create-react-app
npm install --g yarn
(4)在你想創建項目的目錄下 例如 D:/project/ 打開cmd命令 輸入
create-react-app react-exam
去使用creat-react-app命令創建名字是react-exam的項目
安裝完成后,移至新創建的目錄並啟動項目
cd react-exam
yarn start
一旦運行此命令,localhost:3000新的React應用程序將彈出一個新窗口。
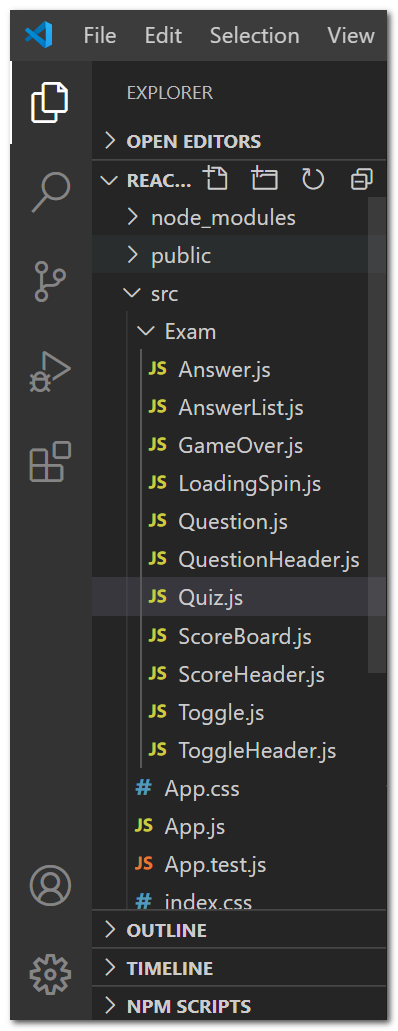
項目目錄結構
右鍵react-exam目錄,使用vscode打開該目錄。
react-exam項目目錄中有一個/public和/src目錄,以及node_modules,.gitignore,README.md,和package.json。
在目錄/public中,重要文件是index.html,其中一行代碼最重要
<div id="root"></div>
該div做為我們整個應用的掛載點
/src目錄將包含我們所有的React代碼。
要查看環境如何自動編譯和更新您的React代碼,請找到文件/src/App.js:
將其中的
<a
className="App-link"
href="https://reactjs.org"
target="_blank"
rel="noopener noreferrer"
>
Learn React
</a>
修改為
<a
className="App-link"
href="https://reactjs.org"
target="_blank"
rel="noopener noreferrer"
>
和豆約翰 Learn React
</a>
保存文件后,您會注意到localhost:3000編譯並刷新了新數據。
React-Exam項目實戰
1. 首頁製作
1.安裝項目依賴,在package.json中添加:
"dependencies": {
"@testing-library/jest-dom": "^4.2.4",
"@testing-library/react": "^9.3.2",
"@testing-library/user-event": "^7.1.2",
"react": "^16.13.1",
"react-dom": "^16.13.1",
"react-scripts": "3.4.1",
"axios": "^0.19.2",
"bootstrap": "^4.5.0",
"he": "^1.2.0",
"react-loading": "^2.0.3",
"reactstrap": "^8.4.1"
},
執行命令:
yarn install
修改index.js,導入bootstrap樣式
import "bootstrap/dist/css/bootstrap.min.css";
修改App.css代碼
html {
width: 80%;
margin-left: 10%;
margin-top: 2%;
}
.ansButton {
margin-right: 4%;
margin-top: 4%;
}
修改App.js,引入Quiz組件
import React from 'react';
import './App.css'
import { Quiz } from './Exam/Quiz';
function App() {
return (
<div className = 'layout'>
<Quiz></Quiz>
</div>
);
}
export default App;
在項目src目錄下新增Exam目錄,Exam目錄中新建Quiz.js
Quiz組件的定義如下:
Quiz.js,引入開始頁面組件Toggle。
import React, { useState } from "react";
import { Toggle } from "./Toggle";
export const Quiz = () => {
const [questionData, setQuestionData] = useState([]);
const questions = questionData.map(({ question }) => [question]);
const answers = questionData.map(({ incorrect_answers, correct_answer }) =>
[correct_answer, incorrect_answers].flat()
);
return (
<>
<Toggle
setQuestionData={setQuestionData}
/>
</>
);
};
Toggle.js,點擊開始按鈕,通過axios訪問遠程接口,獲得題目及答案。
import React from "react";
import axios from "axios";
import ToggleHeader from "./ToggleHeader";
import {
Button,
Form,
} from "reactstrap";
export const Toggle = ({
setQuestionData,
}) => {
const getData = async () => {
try {
const incomingData = await axios.get(
`https://opentdb.com/api.php?amount=10&category=18&difficulty=easy&type=multiple`
);
setQuestionData(incomingData.data.results);
} catch (err) {
console.error(err);
}
};
return (
<>
<ToggleHeader />
<Form
onSubmit={(e) => {
e.preventDefault();
getData();
}}
>
<Button color="primary">開始</Button>
</Form>
</>
);
};
ToggleHeader.js
import React from "react";
import { Jumbotron, Container} from "reactstrap";
export default function ToggleHeader() {
return (
<Jumbotron fluid>
<Container fluid>
<h1 className="display-4">計算機知識小測驗</h1>
</Container>
</Jumbotron>
);
}
https://opentdb.com/api.php接口返回的json數據格式為
{
"response_code": 0,
"results": [{
"category": "Science: Computers",
"type": "multiple",
"difficulty": "easy",
"question": "The numbering system with a radix of 16 is more commonly referred to as ",
"correct_answer": "Hexidecimal",
"incorrect_answers": ["Binary", "Duodecimal", "Octal"]
}, {
"category": "Science: Computers",
"type": "multiple",
"difficulty": "easy",
"question": "This mobile OS held the largest market share in 2012.",
"correct_answer": "iOS",
"incorrect_answers": ["Android", "BlackBerry", "Symbian"]
}, {
"category": "Science: Computers",
"type": "multiple",
"difficulty": "easy",
"question": "How many values can a single byte represent?",
"correct_answer": "256",
"incorrect_answers": ["8", "1", "1024"]
}, {
"category": "Science: Computers",
"type": "multiple",
"difficulty": "easy",
"question": "In computing, what does MIDI stand for?",
"correct_answer": "Musical Instrument Digital Interface",
"incorrect_answers": ["Musical Interface of Digital Instruments", "Modular Interface of Digital Instruments", "Musical Instrument Data Interface"]
}, {
"category": "Science: Computers",
"type": "multiple",
"difficulty": "easy",
"question": "In computing, what does LAN stand for?",
"correct_answer": "Local Area Network",
"incorrect_answers": ["Long Antenna Node", "Light Access Node", "Land Address Navigation"]
}]
}
程序運行效果:
當前項目目錄結構為:
2. 問題展示頁面
Quiz.js,新增toggleView變量用來切換視圖。
const [toggleView, setToggleView] = useState(true);
Quiz.js,其中Question和QuestionHeader 組件,參見後面。
import { Question } from "./Question";
import { Jumbotron } from "reactstrap";
import QuestionHeader from "./QuestionHeader";
...
export const Quiz = () => {
var [index, setIndex] = useState(0);
const [questionData, setQuestionData] = useState([]);
...
return (
<>
{toggleView && (
<Toggle
setIndex={setIndex}
setQuestionData={setQuestionData}
setToggleView={setToggleView}
/>
)}
{!toggleView &&
(
<Jumbotron>
<QuestionHeader
setToggleView={setToggleView}
/>
<Question question={questions[index]} />
</Jumbotron>
)}
</>
);
使用index控制題目索引
var [index, setIndex] = useState(0);
修改Toggle.js
獲取完遠程數據,通過setToggleView(false);切換視圖。
export const Toggle = ({
setQuestionData,
setToggleView,
setIndex,
}) => {
...
return (
<>
<ToggleHeader />
<Form
onSubmit={(e) => {
e.preventDefault();
getData();
setToggleView(false);
setIndex(0);
}}
>
<Button color="primary">開始</Button>
</Form>
</>
);
};
QuestionHeader.js代碼:
同樣的,點擊 返回首頁按鈕 setToggleView(true),切換視圖。
import React from "react";
import { Button } from "reactstrap";
export default function QuestionHeader({ setToggleView, category }) {
return (
<>
<Button color="link" onClick={() => setToggleView(true)}>
返回首頁
</Button>
</>
);
}
Question.js代碼
接受父組件傳過來的question對象,並显示。
其中he.decode是對字符串中的特殊字符進行轉義。
import React from "react";
import he from "he";
export const Question = ({ question }) => {
// he is a oddly named library that decodes html into string values
var decode = he.decode(String(question));
return (
<div>
<hr className="my-2" />
<h1 className="display-5">
{decode}
</h1>
<hr className="my-2" />
<br />
</div>
);
};
程序運行效果:
首頁
點擊開始后,显示問題:
當前項目目錄結構為:
3. 加載等待動畫
新增LoadingSpin.js
import React from "react";
import { Spinner } from "reactstrap";
export default function LoadingSpin() {
return (
<>
<Spinner type="grow" color="primary" />
<Spinner type="grow" color="secondary" />
<Spinner type="grow" color="success" />
<Spinner type="grow" color="danger" />
</>
);
}
修改Quiz.js
import LoadingSpin from "./LoadingSpin";
export const Quiz = () => {
const [isLoading, setLoading] = useState(false);
return (
<>
{toggleView && (
<Toggle
...
setLoading={setLoading}
/>
)}
{!toggleView &&
(isLoading ? (
<LoadingSpin />
) :
(
...
))}
</>
);
};
修改Toggle.js
export const Toggle = ({
...
setLoading,
}) => {
const getData = async () => {
try {
setLoading(true);
const incomingData = await axios.get(
`https://opentdb.com/api.php?amount=10&category=18&difficulty=easy&type=multiple`
);
setQuestionData(incomingData.data.results);
setLoading(false);
} catch (err) {
console.error(err);
}
};
...
};
運行效果:
目前代碼結構:
4. 實現下一題功能
新增Answer.js,用戶點擊下一題按鈕,修改index,觸發主界面刷新,显示下一題:
import React from "react";
import { Button } from "reactstrap";
export const Answer = ({ setIndex, index }) => {
function answerResult() {
setIndex(index + 1);
}
return (
<Button className="ansButton" onClick={answerResult}>
下一題
</Button>
);
};
修改Quiz.js,添加Answer組件:
import { Answer } from "./Answer";
...
{!toggleView &&
(isLoading ? (
<LoadingSpin />
) :
(
<Jumbotron>
...
<Answer
setIndex={setIndex}
index={index}
/>
</Jumbotron>
))}
運行效果:
點擊下一題:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案