校招在即,準備準備一些面試可能會用到的東西吧。希望這次面試不會被掛。
基本概念
說到機器學習模型的誤差,主要就是bias和variance。
-
Bias:如果一個模型的訓練錯誤大,然後驗證錯誤和訓練錯誤都很大,那麼這個模型就是高bias。可能是因為欠擬合,也可能是因為模型是弱分類器。
-
Variance:模型的訓練錯誤小,但是驗證錯誤遠大於訓練錯誤,那麼這個模型就是高Variance,或者說它是過擬合。
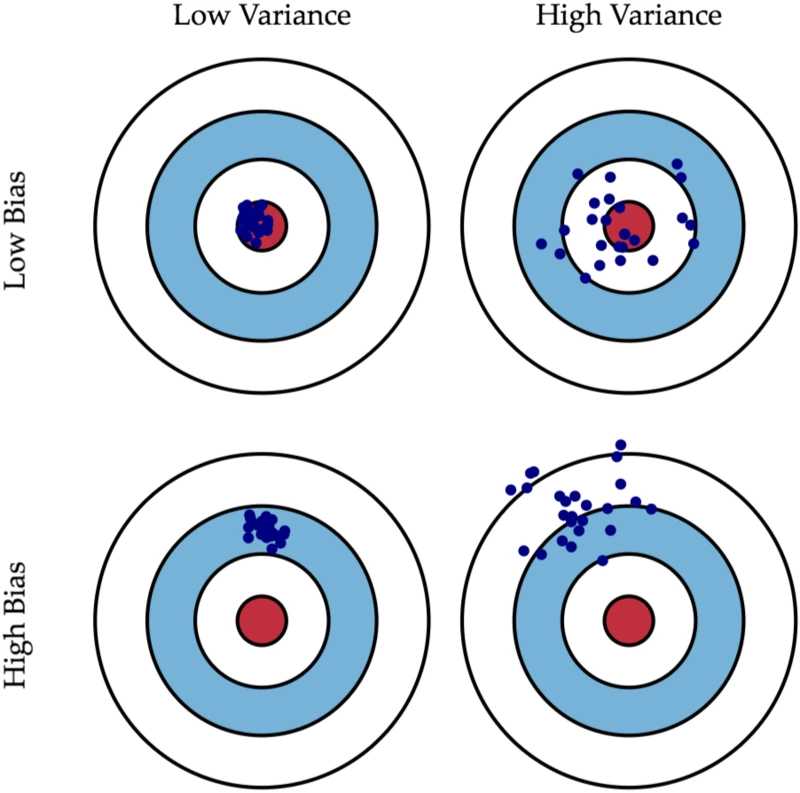
這個圖中,左上角是低偏差低方差的,可以看到所有的預測值,都會落在靶心,完美模型;
右上角是高偏差,可以看到,雖然整體數據預測的好像都在中心,但是波動很大。
【高偏差vs高方差】
在機器學習中,因為偏差和方差不能兼顧,所以我們一般會選擇高偏差、低方差的左下角的模型。穩定性是最重要的,寧可所有的樣本都80%正確率,也不要部分樣本100%、部分50%的正確率。個人感覺,穩定性是學習到東西的體現,高方差模型與隨機蒙的有什麼區別?
隨機森林為例
上面的可能有些抽象,這裏用RandomForest(RF)來作為例子:
隨機森林是bagging的集成模型,這裏:
\(RF(x)=\frac{1}{B}\sum^B_{i=1}{T_{i,z_i}(x)}\)
- RF(x)表示隨機森林對樣本x的預測值;
- B表示總共有B棵樹;
- \(z_i\)表示第i棵樹所使用的訓練集,是使用bagging的方法,從所有訓練集中進行行採樣和列採樣得到的子數據集。
這裏所有的\(z\),都是從所有數據集中隨機採樣的,所以可以理解為都是服從相同分佈的。所以不斷增加B的數量,增加隨機森林中樹的數量,是不會減小模型的偏差的。
【個人感覺,是因為不管訓練再多的樹,其實就那麼多數據,怎麼訓練都不會減少,這一點比較好理解】
【RF是如何降低偏差的?】
直觀上,使用多棵樹和bagging,是可以增加模型的穩定性的。怎麼證明的?
我們需要計算\(Var(T(x))\)
假設不同樹的\(z_i\)之間的相關係數為\(\rho\),然後每棵樹的方差都是\(\sigma^2\).
先複習一下兩個隨機變量相加的方差如何表示:
\(Var(aX+bY)=a^2 Var(X)+b^2 Var(Y) + 2ab cov(X,Y)\)
- Cov(X,Y)表示X和Y的協方差。協方差和相關係數不一樣哦,要除以X和Y的標準差:
\(\rho=\frac{cov(X,Y)}{\sigma_X \sigma_Y}\)
下面轉成B個相關變量的方差計算,是矩陣的形式:
很好推導的,可以試一試。
這樣可以看出來了,RF的樹的數量越多,RF方差的第二項會不斷減小,但是第一項不變。也就是說,第一項就是RF模型偏差的下極限了。
【總結】
- 增加決策樹的數量B,偏差不變;方差減小;
- 增加決策樹深度,偏差減小;\(\rho\)減小,\(\sigma^2\)增加;
- 增加bagging採樣比例,偏差減小;\(\rho\)增加,\(\sigma^2\)增加;
【bagging vs boost】
之前也提到過了boost算法:
一文讀懂:GBDT梯度提升
GBDT中,在某種情況下,是不斷訓練之前模型的殘差,來達到降低bias的效果。雖然也是集成模型,但是可以想到,每一個GBDT中的樹,所學習的數據的分佈都是不同的,這意味着在GBDT模型的方差會隨着決策樹的數量增多,不斷地增加。
- bagging的目的:降低方差;
- boost的目的:降低偏差
喜歡的話請關注我們的微信公眾號~【你好世界煉丹師】。
- 公眾號主要講統計學,數據科學,機器學習,深度學習,以及一些參加Kaggle競賽的經驗。
- 公眾號內容建議作為課後的一些相關知識的補充,飯後甜點。
- 此外,為了不過多打擾,公眾號每周推送一次,每次4~6篇精選文章。
微信搜索公眾號:你好世界煉丹師。期待您的關注。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※教你寫出一流的銷售文案?