目錄
- 概念
- 強迫鄰居(Forced Neighbour)
- 跳點(Jump Point)
- JPS 尋路算法(Jump Point Search)
- 實現原理
- 示例過程
- JPS+(Jump Point Search Plus)
- 預處理
- 示例過程
- 總結
- 參考
概念
JPS(jump point search)算法實際上是對A* 尋路算法的一個改進,因此在閱讀本文之前需要先了解A*算法。A* 算法在擴展節點時會把節點所有鄰居都考慮進去,這樣openlist中點的數量會很多,搜索效率較慢。
若不了解A*算法,可以參考博主以前寫的一篇文章 A* 尋路算法 – KillerAery – 博客園
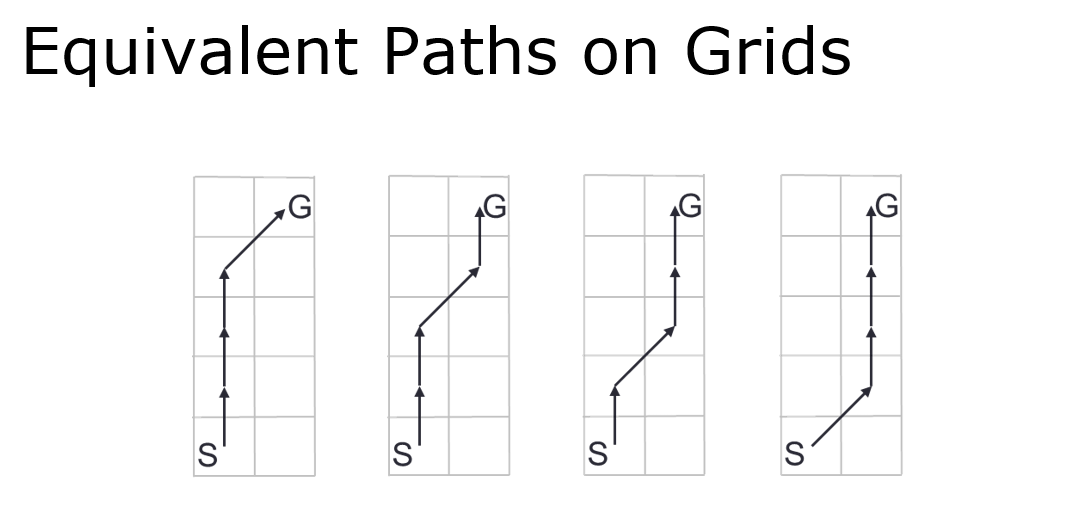
例如在無遮擋情況下(往往會有多條等價路徑),而我們希望起點到終點實際只取其中一條路徑,而該路徑外其它節點可以沒必要放入openlist(不希望加入沒必要的鄰居)。
其次我們還希望直線方向上中途的點不用放入openlist,如果只放入每段直線子路徑的起點和終點,那openlist又可以少放很多沒必要的節點:
可以看到 JPS 算法搜到的節點總是“跳躍性”的,這是因為這些關鍵性的節點都是需要改變行走方向的拐點,因此這也是 Jump Point 命名的來歷。
在介紹JPS等算法具體實現前,我們必須先掌握下面的概念。
強迫鄰居(Forced Neighbour)
強迫鄰居:節點 x 的8個鄰居中有障礙,且 x 的父節點 p 經過x 到達 n 的距離代價比不經過 x 到達的 n 的任意路徑的距離代價小,則稱 n 是 x 的強迫鄰居。
看定義也許十分晦澀難懂。直觀來說,實際就是因為前進方向(父節點到 x 節點的方向為前進方向)的某一邊的靠後位置有障礙物,因此想要到該邊靠前的空位有最短的路徑,就必須得經過過 x 節點。
可能的情況見圖示,黑色為障礙,紅圈即為強迫鄰居:
(左圖為直線方向情況下的強迫鄰居,右圖為斜方向情況下的強迫鄰居)
跳點(Jump Point)
跳點:當前點 x 滿足以下三個條件之一:
- 節點 x 是起點/終點。
- 節點 x 至少有一個強迫鄰居。
- 如果父節點在斜方向(意味着這是斜向搜索),節點x的水平或垂直方向上有滿足條件a,b的點。
節點y的水平或垂直方向是斜向向量的拆解,比如向量d=(1,1),那麼水平方向則是(1,0),並不會往左搜索,只會看右邊,如果向量d=(-1,-1),那麼水平方向是(-1,0),只會搜索左邊,不看右邊,其他同理。
下圖舉個例子,由於黃色節點的父節點是在斜方向,其對應分解成向上和向右兩個方向,因為在右方向發現一個藍色跳點,因此黃色節點也應被判斷為跳點:
JPS 尋路算法(Jump Point Search)
實現原理
JPS 算法和A* 算法非常相似,步驟大概如下:
- openlist取一個權值最低的節點,然後開始搜索。(這些和A*是一樣的)
- 搜索時,先進行 直線搜索(4/8個方向,跳躍搜索),然後再 斜向搜索(4個方向,只搜索一步)。如果期間某個方向搜索到跳點或者碰到障礙(或邊界),則當前方向完成搜索,若有搜到跳點就添加進openlist。
跳躍搜索是指沿直線方向一直搜下去(可能會搜到很多格),直到搜到跳點或者障礙(邊界)。一開始從起點搜索,會有4個直線方向(上下左右),要是4個斜方向都前進了一步,此時直線方向會有8個。
- 若斜方向沒完成搜索,則斜方向前進一步,重複上述過程。
因為直線方向是跳躍式搜索,所以總是能完成搜索。
- 若所有方向已完成搜索,則認為當前節點搜索完畢,將當前節點移除於openlist,加入closelist。
- 重複取openlist權值最低節點搜索,直到openlist為空或者找到終點。
下面結合圖片更好說明過程2和3:首先我們從openlist取出綠色的節點,作為搜索的開始,先進行直線搜索,再斜向搜索,沒有找到任何跳點。
斜方向前進一步后,重複直線搜索和斜向搜索過程,仍沒發現跳點。
斜方向前進兩步后,重複直線搜索和斜向搜索過程,仍沒發現跳點。
斜方向前進了三步后(假設當前位置為 x),在水平直線搜索上發現了一個跳點(紫色節點為強迫鄰居)。
於是 x 也被判斷為跳點,添加進openlist。斜方向結束,綠色節點的搜索過程也就此結束,被移除於openlist,放入closelist。
示例過程
下面展示JPS算法更加完整的過程:
假設起點為綠色節點,終點為紅色節點。
重複直線搜索和斜向搜索過程,斜方向前進了3步。在第3步判斷出黃色節點為跳點(依據是水平方向有其它跳點),將黃色跳點放入openlist,然後斜方向搜索完成,綠色節點移除於openlist,放入closelist。
對openlist下一個權值最低的節點(即黃色節點)開啟搜索,在直線方向上發現了藍色節點為跳點(依據是紫色節點為強迫鄰居),類似地,放入openlist。
由於斜方向還沒結束,繼續前進一步。最後一次直線搜索和斜向搜索都碰到了邊界,因此黃色節點搜索完成,移除於openlist,放入closelist。
對openlist下一個權值最低的節點(原為藍色節點,下圖變為黃色節點)開啟搜索,直線搜索碰到邊界,斜向搜索無果。斜方繼續前進一步,仍然直線搜索碰到邊界,斜向搜索無果。
由於斜方向還沒結束,繼續前進一步。
最終在直線方向上發現了紅色節點為跳點,因此藍色節點先被判斷為跳點,只添加藍色節點進openlist。斜方向完成,黃色節點搜索完成。
最後openlist取出的藍色節點開啟搜索,在水平方向上發現紅色節點,判斷為終點,算法完成。
回憶起跳點的第三個判斷條件(如果父節點在斜方向,節點x的水平或垂直方向上有滿足條件a,b的點),會發現這個條件判斷是最複雜的。在尋路過程中,它使尋路多次在水平節點上搜到跳點,也只能先添加它本身。其次,這也是算法中需要使用到遞歸的地方,是JPS算法性能瓶頸所在。
JPS+(Jump Point Search Plus)
JPS+ 本質上也是 JPS尋路,只是加上了預處理來改進,從而使尋路更加快速。
預處理
我們首先對地圖每個節點進行跳點判斷,找出所有主要跳點:
然後對每個節點進行跳點的直線可達性判斷,並記錄好跳點直線可達性:
若可達還需記錄號跳點直線距離:
類似地,我們對每個節點進行跳點斜向距離的記錄:
剩餘各個方向如果不可到達跳點的數據記為0或負數距離。如果在對應的方向上移動1步后碰到障礙(或邊界)則記為0,如果移動n+1步後會碰到障礙(或邊界)的數據記為負數距離-n
最後每個節點的8個方向都記錄完畢,我們便完成了JPS+的預處理過程:
以上預處理過程需要有一個數據結構存儲地圖上每個格子8個方向距離碰撞或跳點的距離。
示例過程
做好了地圖的預處理之後,我們就可以使用JPS+算法了。大致思路與JPS算法相同,不過這次有了預處理的數據,我們可以更快的進行直線搜索和斜向搜索。
在某個搜索方向上有:
- 對於正數距離 n(意味着距離跳點 n 格),我們可以直接將n步遠的節點作為跳點添加進openlist
- 對於0距離(意味着一步都不可移動),我們無需在該方向搜索;
- 對於負數距離 -n(意味着距離邊界或障礙 n 格),我們直接將n步遠的節點進行一次跳點判斷(有可能滿足跳點的第三條件,不過得益於預處理的數據,這步也可以很快完成)。
如下圖示,起始節點通過已記錄的向上距離,直接將3步遠的跳點添加進openlist,而不再像以前需要迭代三步(還每步都要判斷是否跳點):
其它過程也是類似的:
總結
可以看到 JPS/JPS+ 算法里只有跳點才會被加入openlist里,排除了大量不必要的點,最後找出來的最短路徑也是由跳點組成。這也是 JPS/JPS+ 高效的主要原因。
JPS :
- 絕大部分地圖,使用 JPS 算法都會比 A* 算法更快,內存佔用也更小(openlist里節點少了很多)。
- JPS 在跳點判斷上,要盡可能避免遞歸的深度過大(或者期待一下以後出現避免遞歸的算法),否則在超大型的地圖裡遞歸判斷跳點可能會造成災難。
- JPS 也可以用於動態變化的地圖,只是每次地圖改變都需要再進行一次 JPS 搜索。
- JPS 天生擁有合併節點(亦或者說是在一條直線里移除中間不必要節點)的功能,但是仍存在一些可以繼續合併的地方。
- JPS 只適用於 網格(grid)節點類型,不支持 Navmesh 或者路徑點(Way Point)。
JPS+ :
- JPS+ 相比 JPS 算法又是更快上一個檔次(特別是避免了過多層遞歸判斷跳點),內存佔用則是每個格子需要額外記錄8個方向的距離數據。
- JPS+ 算法由於包含預處理過程,這讓它面對動態變化的地圖有天生的劣勢(幾乎是不可以接受動態地圖的),因此更適合用於靜態地圖。
- JPS+ 預處理的複雜度為 \(O(n)\) ,n 代表地圖格子數。
| 算法 | 性能 | 內存佔用 | 支持動態地圖 | 預處理 | 支持節點類型 |
|---|---|---|---|---|---|
| A* | 中等 | 大 | 支持 | 無 | 網格、Navmesh、路徑點 |
| JPS | 快 | 偏小 | 支持 | 無 | 網格 |
| JPS+ | 非常快 | 中等 | 不支持 | 有,\(O(n)\) | 網格 |
綜上,JPS/JPS+ 是A*算法的優秀替代者,絕大部分情況下更快和更小的內存佔用已經足夠誘人。在GDC 2015 關於 JPS+ 算法的演講中,Steve Rabin 給出的數據甚至是比A* 算法快70~350倍。
參考
[1] 從頭理解JPS尋路算法 – 簡書 by ElephantKing
[2] JPS+: Over 100x Faster than A* | GDC 2015
[3] JPS+ with GoalBounding C++實現,和上面GDC2015的演講人是同一個人 Steve Rabin。
[4] 一個在線可視化的JPS實現附說明 A Visual Explanation Of Jump Point Search
[5] JPS 算法原作者論文 github Harabor, Daniel Damir, and Alban Grastien. “Online Graph Pruning for Pathfinding On Grid Maps.” AAAI. 2011.
博主其它相關文章:
遊戲AI 系列文章 – KillerAery – 博客園
遊戲AI之路徑規劃 – KillerAery – 博客園
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧