環境篇:Kylin3.0.1集成CDH6.2.0
Kylin是什麼?
Apache Kylin™是一個開源的、分佈式的分析型數據倉庫,提供Hadoop/Spark 之上的 SQL 查詢接口及多維分析(OLAP)能力以支持超大規模數據,最初由 eBay 開發並貢獻至開源社區。它能在亞秒內查詢巨大的表。
Apache Kylin™ 令使用者僅需三步,即可實現超大數據集上的亞秒級查詢。
- 定義數據集上的一個星形或雪花形模型
- 在定義的數據表上構建cube
- 使用標準 SQL 通過 ODBC、JDBC 或 RESTFUL API 進行查詢,僅需亞秒級響應時間即可獲得查詢結果
如果沒有Kylin
大數據在數據積累后,需要計算,而數據越多,算力越差,內存需求也越高,詢時間與數據量成線性增長,而這些對於Kylin影響不大,大數據中硬盤往往比內存要更便宜,Kylin通過與計算的形式,以空間換時間,亞秒級的響應讓人們愛不釋手。
注:所謂詢時間與數據量成線性增長:假設查詢 1 億條記錄耗時 1 分鐘,那麼查詢 10 億條記錄就需 10分鐘,100 億條記錄就至少需要 1 小時 40 分鐘。
http://kylin.apache.org/cn/
1 Kylin架構
Kylin 提供與多種數據可視化工具的整合能力,如 Tableau,PowerBI 等,令用戶可以使用 BI 工具對 Hadoop 數據進行分析
- REST Server REST Server
是一套面嚮應用程序開發的入口點,旨在實現針對 Kylin 平台的應用開發 工作。 此類應用程序可以提供查詢、獲取結果、觸發 cube 構建任務、獲取元數據以及獲取 用戶權限等等。另外可以通過 Restful 接口實現 SQL 查詢。
- 查詢引擎(Query Engine)
當 cube 準備就緒后,查詢引擎就能夠獲取並解析用戶查詢。它隨後會與系統中的其它 組件進行交互,從而向用戶返回對應的結果。
- 路由器(Routing)
在最初設計時曾考慮過將 Kylin 不能執行的查詢引導去 Hive 中繼續執行,但在實踐后 發現 Hive 與 Kylin 的速度差異過大,導致用戶無法對查詢的速度有一致的期望,很可能大 多數查詢幾秒內就返回結果了,而有些查詢則要等幾分鐘到幾十分鐘,因此體驗非常糟糕。 最後這個路由功能在發行版中默認關閉。
- 元數據管理工具(Metadata)
Kylin 是一款元數據驅動型應用程序。元數據管理工具是一大關鍵性組件,用於對保存 在 Kylin 當中的所有元數據進行管理,其中包括最為重要的 cube 元數據。其它全部組件的 正常運作都需以元數據管理工具為基礎。 Kylin 的元數據存儲在 hbase 中。
- 任務引擎(Cube Build Engine)
這套引擎的設計目的在於處理所有離線任務,其中包括 shell 腳本、Java API 以及 MapReduce 任務等等。任務引擎對 Kylin 當中的全部任務加以管理與協調,從而確保每一項任務 都能得到切實執行並解決其間出現的故障。
2 Kylin軟硬件要求
- 軟件要求
- Hadoop: 2.7+, 3.1+ (since v2.5)
- Hive: 0.13 – 1.2.1+
- HBase: 1.1+, 2.0 (since v2.5)
- Spark (optional) 2.3.0+
- Kafka (optional) 1.0.0+ (since v2.5)
- JDK: 1.8+ (since v2.5)
- OS: Linux only, CentOS 6.5+ or Ubuntu 16.0.4+
- 硬件要求
- 最低配置:4 core CPU, 16 GB memory
- 高負載場景:24 core CPU, 64 GB memory
3 Kylin單機安裝
3.1 修改環境變量
vim /etc/profile
#>>>注意地址指定為自己的
#kylin
export KYLIN_HOME=/usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
export PATH=$PATH:$KYLIN_HOME/bin
#cdh
export CDH_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373
#hadoop
export HADOOP_HOME=${CDH_HOME}/lib/hadoop
export HADOOP_DIR=${HADOOP_HOME}
export HADOOP_CLASSPATH=${HADOOP_HOME}
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#hbase
export HBASE_HOME=${CDH_HOME}/lib/hbase
export PATH=$PATH:$HBASE_HOME/bin
#hive
export HIVE_HOME=${CDH_HOME}/lib/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=${CDH_HOME}/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
#kafka
export KAFKA_HOME=${CDH_HOME}/lib/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#<<<
source /etc/profile
3.2 修改hdfs用戶權限
usermod -s /bin/bash hdfs
su hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -chmod a+rwx /kylin
su
3.3 上傳安裝包解壓
mkdir /usr/local/src/kylin
cd /usr/local/src/kylin
tar -zxvf apache-kylin-3.0.1-bin-cdh60.tar.gz
cd /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
3.4 Java兼容hbase
- hbase 所有節點
在CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar后添加
>>---
:/opt/cloudera/parcels/CDH/lib/hbase/lib/*
<<---
- Kylin節點添加jar包
cp /opt/cloudera/cm/common_jars/commons-configuration-1.9.cf57559743f64f0b3a504aba449c9649.jar /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60/tomcat/lib
這2步不做會引起 Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
3.5 啟動停止
./bin/kylin.sh start
#停止 ./bin/kylin.sh stop
3.6 web頁面
訪問端口7070
賬號密碼:ADMIN / KYLIN
4 Kylin集群安裝
4.1 修改環境變量
vim /etc/profile
#>>>注意地址指定為自己的
#kylin
export KYLIN_HOME=/usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
export PATH=$PATH:$KYLIN_HOME/bin
#cdh
export CDH_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373
#hadoop
export HADOOP_HOME=${CDH_HOME}/lib/hadoop
export HADOOP_DIR=${HADOOP_HOME}
export HADOOP_CLASSPATH=${HADOOP_HOME}
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#hbase
export HBASE_HOME=${CDH_HOME}/lib/hbase
export PATH=$PATH:$HBASE_HOME/bin
#hive
export HIVE_HOME=${CDH_HOME}/lib/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=${CDH_HOME}/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
#kafka
export KAFKA_HOME=${CDH_HOME}/lib/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#<<<
source /etc/profile
4.2 修改hdfs用戶權限
usermod -s /bin/bash hdfs
su hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -chmod a+rwx /kylin
su
4.3 上傳安裝包解壓
mkdir /usr/local/src/kylin
cd /usr/local/src/kylin
tar -zxvf apache-kylin-3.0.1-bin-cdh60.tar.gz
cd /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
4.4 Java兼容hbase
- hbase 所有節點
在CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar后添加
vim /opt/cloudera/parcels/CDH/lib/hbase/bin/hbase
>>---
:/opt/cloudera/parcels/CDH/lib/hbase/lib/*
<<---
- Kylin節點添加jar包
cp /opt/cloudera/cm/common_jars/commons-configuration-1.9.cf57559743f64f0b3a504aba449c9649.jar /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60/tomcat/lib
這2步不做會引起 Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
4.5 修改kylin配置文件
Kylin根據自己的運行職責狀態,可以劃分為以下三大類角色
- Job節點:僅用於任務調度,不用於查詢
- Query節點:僅用於查詢,不用於構建任務的調度
- All節點:模式代表該服務同時用於任務調度和 SQL 查詢
- 2.0以前同一個集群只能有一個節點(Kylin實例)用於job調度(all或者job模式的只能有一個實例)
- 2.0開始可以多個job或者all節點實現HA
vim conf/kylin.properties
>>----
#指定元數據庫路徑,默認值為 kylin_metadata@hbase,確保kylin集群使用一致
kylin.metadata.url=kylin_metadata@hbase
#指定 Kylin 服務所用的 HDFS 路徑,默認值為 /kylin,請確保啟動 Kylin 實例的用戶有讀寫該目錄的權限
kylin.env.hdfs-working-dir=/kylin
kylin.server.mode=all
kylin.server.cluster-servers=cdh01.cm:7070,cdh02.cm:7070,cdh03.cm:7070
kylin.storage.url=hbase
#構建任務失敗后的重試次數,默認值為 0
kylin.job.retry=2
#最大構建併發數,默認值為 10
kylin.job.max-concurrent-jobs=10
#構建引擎間隔多久檢查 Hadoop 任務的狀態,默認值為 10(s)
kylin.engine.mr.yarn-check-interval-seconds=10
#MapReduce 任務啟動前會依據輸入預估 Reducer 接收數據的總量,再除以該參數得出 Reducer 的數目,默認值為 500(MB)
kylin.engine.mr.reduce-input-mb=500
#MapReduce 任務中 Reducer 數目的最大值,默認值為 500
kylin.engine.mr.max-reducer-number=500
#每個 Mapper 可以處理的行數,默認值為 1000000,如果將這個值調小,會起更多的 Mapper
kylin.engine.mr.mapper-input-rows=1000000
#啟用分佈式任務鎖
kylin.job.scheduler.default=2
kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock
<<----
4.6 啟動停止
所有Kylin節點
./bin/kylin.sh start
#停止 ./bin/kylin.sh stop
4.7 nginx負載均衡
yum -y install nginx
vim /etc/nginx/nginx.conf
>>---http中添加替換內容
upstream kylin {
least_conn;
server 192.168.37.10:7070 weight=8;
server 192.168.37.11:7070 weight=7;
server 192.168.37.12:7070 weight=7;
}
server {
listen 9090;
server_name localhost;
location / {
proxy_pass http://kylin;
}
}
<<---
#重啟 nginx 服務
systemctl restart nginx
4.8 訪問web頁面
訪問任何節點的7070端口都可以進入kylin
訪問nginx所在機器9090端口/kylin負載均衡進入kylin
賬號密碼:ADMIN / KYLIN
4 大規模并行處理@列式存儲
自從 10 年前 Hadoop 誕生以來,大數據的存儲和批處理問題均得到了妥善解決,而如何高速地分析數據也就成為了下一個挑戰。於是各式各樣的“SQL on Hadoop”技術應運而生,其中以 Hive 為代表,Impala、Presto、Phoenix、Drill、 SparkSQL 等緊隨其後(何以解憂–唯有CV SQL BOY)。它們的主要技術是“大規模并行處理”(Massive Parallel Processing,MPP)和“列式存儲”(Columnar Storage)。
大規模并行處理可以調動多台機器一起進行并行計算,用線性增加的資源來換取計算時間的線性下降。
列式存儲則將記錄按列存放,這樣做不僅可以在訪問時只讀取需要的列,還可以利用存儲設備擅長連續讀取的特點,大大提高讀取的速率。
這兩項關鍵技術使得 Hadoop 上的 SQL 查詢速度從小時提高到了分鐘。 然而分鐘級別的查詢響應仍然離交互式分析的現實需求還很遠。分析師敲入 查詢指令,按下回車,還需要去倒杯咖啡,靜靜地等待查詢結果。得到結果之後才能根據情況調整查詢,再做下一輪分析。如此反覆,一個具體的場景分析常常需要幾小時甚至幾天才能完成,效率低下。 這是因為大規模并行處理和列式存儲雖然提高了計算和存儲的速度,但並沒有改變查詢問題本身的時間複雜度,也沒有改變查詢時間與數據量成線性增長的關係這一事實。
假設查詢 1 億條記錄耗時 1 分鐘,那麼查詢 10 億條記錄就需 10分鐘,100 億條記錄就至少需要 1 小時 40 分鐘。 當然,可以用很多的優化技術縮短查詢的時間,比如更快的存儲、更高效的壓縮算法,等等,但總體來說,查詢性能與數據量呈線性相關這一點是無法改變的。雖然大規模并行處理允許十倍或百倍地擴張計算集群,以期望保持分鐘級別的查詢速度,但購買和部署十倍或百倍的計算集群又怎能輕易做到,更何況還有 高昂的硬件運維成本。 另外,對於分析師來說,完備的、經過驗證的數據模型比分析性能更加重要, 直接訪問紛繁複雜的原始數據並進行相關分析其實並不是很友好的體驗,特別是在超大規模的數據集上,分析師將更多的精力花在了等待查詢結果上,而不是在更加重要的建立領域模型上。
5 Kylin如何解決海量數據的查詢問題
**Apache Kylin 的初衷就是要解決千億條、萬億條記錄的秒級查詢問題,其中的關鍵就是要打破查詢時間隨着數據量成線性增長的這個規律。根據OLAP分析,可以注意到兩個結論: **
-
大數據查詢要的一般是統計結果,是多條記錄經過聚合函數計算后的統計值。原始的記錄則不是必需的,或者訪問頻率和概率都極低。
-
聚合是按維度進行的,由於業務範圍和分析需求是有限的,有意義的維度聚合組合也是相對有限的,一般不會隨着數據的膨脹而增長。
**基於以上兩點,我們可以得到一個新的思路——“預計算”。應盡量多地預先計算聚合結果,在查詢時刻應盡量使用預算的結果得出查詢結果,從而避免直 接掃描可能無限增長的原始記錄。 **
舉例來說,使用如下的 SQL 來查詢 11月 11日 那天銷量最高的商品:
select item,sum(sell_amount)
from sell_details
where sell_date='2020-11-11'
group by item
order by sum(sell_amount) desc
用傳統的方法時需要掃描所有的記錄,再找到 11月 11日 的銷售記錄,然後按商品聚合銷售額,最後排序返回。
假如 11月 11日 有 1 億條交易,那麼查詢必須讀取並累計至少 1 億條記錄,且這個查詢速度會隨將來銷量的增加而逐步下降。如果日交易量提高一倍到 2 億,那麼查詢執行的時間可能也會增加一倍。
而使用預 計算的方法則會事先按維度 [sell_date , item] 計 算 sum(sell_amount)並存儲下來,在查詢時找到 11月 11日 的銷售商品就可以直接排序返回了。讀取的記錄數最大不會超過維度[sell_date,item]的組合數。
顯然這個数字將遠遠小於實際的銷售記錄,比如 11月 11日 的 1 億條交易包含了 100萬條商品,那麼預計算后就只有 100 萬條記錄了,是原來的百分之一。並且這些 記錄已經是按商品聚合的結果,因此又省去了運行時的聚合運算。從未來的發展來看,查詢速度只會隨日期和商品數目(時間,商品維度)的增長而變化,與銷售記錄的總數不再有直接聯繫。假如日交易量提高一倍到 2 億,但只要商品的總數不變,那麼預計算的結果記錄總數就不會變,查詢的速度也不會變。
預計算就是 Kylin 在“大規模并行處理”和“列式存儲”之外,提供給大數據分析的第三個關鍵技術。
6 Kylin 入門案例
6.1 hive數據準備
--創建數據庫kylin_hive
create database kylin_hive;
--創建表部門表dept
create external table if not exists kylin_hive.dept(
deptno int,
dname string,
loc int )
row format delimited fields terminated by '\t';
--添加數據
INSERT INTO TABLE kylin_hive.dept VALUES(10,"ACCOUNTING",1700),(20,"RESEARCH",1800),(30,"SALES",1900),(40,"OPERATIONS",1700)
--查看數據
SELECT * FROM kylin_hive.dept
--創建員工表emp
create external table if not exists kylin_hive.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
--添加數據
INSERT INTO TABLE kylin_hive.emp VALUES(7369,"SMITHC","LERK",7902,"1980-12-17",800.00,0.00,20),(7499,"ALLENS","ALESMAN",7698,"1981-2-20",1600.00,300.00,30),(7521,"WARDSA","LESMAN",7698,"1981-2-22",1250.00,500.00,30),(7566,"JONESM","ANAGER",7839,"1981-4-2",2975.00,0.00,20),(7654,"MARTIN","SALESMAN",7698,"1981-9-28",1250.00,1400.00,30),(7698,"BLAKEM","ANAGER",7839,"1981-5-1",2850.00,0.00,30),(7782,"CLARKM","ANAGER",7839,"1981-6-9",2450.00,0.00,10),(7788,"SCOTTA","NALYST",7566,"1987-4-19",3000.00,0.00,20),(7839,"KINGPR","ESIDENT",7533,"1981-11-17",5000.00,0.00,10),(7844,"TURNER","SALESMAN",7698,"1981-9-8",1500.00,0.00,30),(7876,"ADAMSC","LERK",7788,"1987-5-23",1100.00,0.00,20),(7900,"JAMESC","LERK",7698,"1981-12-3",950.00,0.00,30),(7902,"FORDAN","ALYST",7566,"1981-12-3",3000.00,0.00,20),(7934,"MILLER","CLERK",7782,"1982-1-23",1300.00,0.00,10)
--查看數據
SELECT * FROM kylin_hive.emp
6.2 創建工程
- 輸入工程名稱以及工程描述
6.3 Kylin加載Hive表
雖然 Kylin 使用 SQL 作為查詢接口並利用 Hive 元數據,Kylin 不會讓用戶查詢所有的 hive 表,因為到目前為止它是一個預構建 OLAP(MOLAP) 系統。為了使表在 Kylin 中可用,使用 “Sync” 方法能夠方便地從 Hive 中同步表。
- 選擇項目添加hive數據源
- 添加數據源表–>hive庫名稱.表名稱(以逗號分隔)
- 這裏只添加了表的Schema元信息,如果需要加載數據,還需要點擊Reload Table
6.4 Kylin添加Models(模型)
- 填寫模型名字
- 選擇事實表,這裏選擇員工EMP表為事實表
- 添加維度表,這裏選擇部門DEPT表為維度表,並選擇我們的join方式,以及join連接字段
- 選擇聚合維度信息
- 選擇度量信息
- 添加分區信息及過濾條件之後“Save”
6.5 Kylin構建Cube
Kylin 的 OLAP Cube 是從星型模式的 Hive 表中獲取的預計算數據集,這是供用戶探索、管理所有 cube 的網頁管理頁面。由菜單欄進入Model 頁面,系統中所有可用的 cube 將被列出。
- 創建一個new cube
- 選擇我們的model以及指定cube name
- 添加我們的自定義維度,這裡是在創建Models模型時指定的事實表和維度表中取
- LookUpTable可選擇normal或derived(一般列、衍生列)
- normal緯度作為普通獨立的緯度,而derived 維度不會計算入cube,將由事實表的外鍵推算出
- 添加統計維度,勾選相應列作為度量,kylin提供8種度量:SUM、MAX、MIN、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE
- DISTINCT_COUNT有兩個實現:
- 近似實現 HyperLogLog,選擇可接受的錯誤率,低錯誤率需要更多存儲;
- 精確實現 bitmap
- TopN 度量在每個維度結合時預計算,需要兩個參數:
- 一是被用來作為 Top 記錄的度量列,Kylin 將計算它的 SUM 值並做倒序排列,如sum(price)
- 二是 literal ID,代表最 Top 的記錄,如seller_id
- EXTENDED_COLUMN
- Extended_Column 作為度量比作為維度更節省空間。一列和零一列可以生成新的列
- PERCENTILE
- Percentile 代表了百分比。值越大,錯誤就越少。100為最合適的值
- DISTINCT_COUNT有兩個實現:
- 設置多個分區cube合併信息
如果是分區統計,需要關於歷史cube的合併,
這裡是全量統計,不涉及多個分區cube進行合併,所以不用設置歷史多個cube進行合併
Auto Merge Thresholds:
- 自動合併小的 segments 到中等甚至更大的 segment。如果不想自動合併,刪除默認2個選項
Volatile Range:
- 默認為0,會自動合併所有可能的cube segments,或者用 ‘Auto Merge’ 將不會合併最新的 [Volatile Range] 天的 cube segments
Retention Threshold:
- 默認為0,只會保存 cube 過去幾天的 segment,舊的 segment 將會自動從頭部刪除
Partition Start Date:
- cube 的開始日期
- 高級設置
暫時也不做任何設
置高級設定關係到立方體是否足夠優化,可根據實際情況將維度列定義為強制維度、層級維度、聯合維度
- Mandatory維度指的是總會存在於group by或where中的維度
- Hierarchy是一組有層級關係的維度,如國家、省份、城市
- Joint是將多個維度組合成一個維度
- 額外的其他的配置屬性
這裏也暫時不做配置
Kylin 允許在 Cube 級別覆蓋部分 kylin.properties 中的配置
- 完成保存配置
通過Planner計劃者,可以看到4個維度,得到Cuboid Conut=15,為2的4次方-1,因為全部沒有的指標不會使用,所以結果等於15。
- 構建Cube
6.6 數據查詢
- 根據部門查詢,部門工資總和
SELECT DEPT.DNAME,SUM(EMP.SAL)
FROM EMP
LEFT JOIN DEPT
ON DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DEPT.DNAME
7 入門案例構建流程
- 動畫演示
8 Kylin的工作原理
就是對數據模型做 Cube 預計算,並利用計算的結果加速查詢,具體工作過程如下:
-
指定數據模型,定義維度和度量。
-
預計算 Cube,計算所有 Cuboid 並保存為物化視圖。
-
執行查詢時,讀取 Cuboid,運算,產生查詢結果。
由於 Kylin 的查詢過程不會掃描原始記錄,而是通過預計算預先完成表的關聯、聚合等複雜運算,並利用預計算的結果來執行查詢,因此相比非預計算的查詢技術,其速度一般要快一到兩個數量級,並且這點在超大的數據集上優勢更明顯。當數據集達到千億乃至萬億級別時,Kylin 的速度甚至可以超越其他非預計算技術 1000 倍以上。
9 Cube 和 Cuboid
Cube(或 Data Cube),即數據立方體,是一種常用於數據分析與索引的技術;它可以對原始數據建立多維度索引。通過 Cube 對數據進行分析,可以大大加快數據的查詢效率。
Cuboid 特指在某一種維度組合下所計算的數據。 給定一個數據模型,我們可以對其上的所有維度進行組合。對於 N 個維度來說,組合的所有可能性共有 2 的 N 次方種。對於每一種維度的組合,將度量做 聚合運算,然後將運算的結果保存為一個物化視圖,稱為 Cuboid。
所有維度組合的 Cuboid 作為一個整體,被稱為 Cube。所以簡單來說,一個 Cube 就是許多按維度聚合的物化視圖的集合。
下面來列舉一個具體的例子:
假定有一個電商的銷售數據集,其中維度包括 時間(Time)、商品(Item)、地點(Location)和供應商(Supplier),度量為銷售額(GMV)。
- 那麼所有維度的組合就有 2 的 4 次方 =16 種
- 一維度(1D) 的組合有[Time]、[Item]、[Location]、[Supplier]4 種
- 二維度(2D)的組合 有[Time,Item]、[Time,Location]、[Time、Supplier]、[Item,Location]、 [Item,Supplier]、[Location,Supplier]6 種
- 三維度(3D)的組合也有 4 種
- 零維度(0D)的組合有 1 種
- 四維度(4D)的組合有 1 種
10 cube構建算法
10.1 逐層構建算法
我們知道,一個N維的Cube,是由1個N維子立方體、N個(N-1)維子立方體、N*(N-1)/2個(N-2)維子立方體、……、N個1維子立方體和1個0維子立方體構成,總共有2^N個子立方體組成。
在逐層算法中,按維度數逐層減少來計算,每個層級的計算(除了第一層,它是從原始數據聚合而來),是基於它上一層級的結果來計算的。比如,[Group by A, B]的結果,可以基於[Group by A, B, C]的結果,通過去掉C后聚合得來的;這樣可以減少重複計算;當 0維度Cuboid計算出來的時候,整個Cube的計算也就完成了。
每一輪的計算都是一個MapReduce任務,且串行執行;一個N維的Cube,至少需要N次MapReduce Job。
算法優點:
-
此算法充分利用了MapReduce的優點,處理了中間複雜的排序和shuffle工作,故而算法代碼清晰簡單,易於維護;
-
受益於Hadoop的日趨成熟,此算法非常穩定,即便是集群資源緊張時,也能保證最終能夠完成。
算法缺點:
-
當Cube有比較多維度的時候,所需要的MapReduce任務也相應增加;由於Hadoop的任務調度需要耗費額外資源,特別是集群較龐大的時候,反覆遞交任務造成的額外開銷會相當可觀;
-
由於Mapper邏輯中並未進行聚合操作,所以每輪MR的shuffle工作量都很大,導致效率低下。
-
對HDFS的讀寫操作較多:由於每一層計算的輸出會用做下一層計算的輸入,這些Key-Value需要寫到HDFS上;當所有計算都完成后,Kylin還需要額外的一輪任務將這些文件轉成HBase的HFile格式,以導入到HBase中去;
總體而言,該算法的效率較低,尤其是當Cube維度數較大的時候。
10.2 快速構建算法
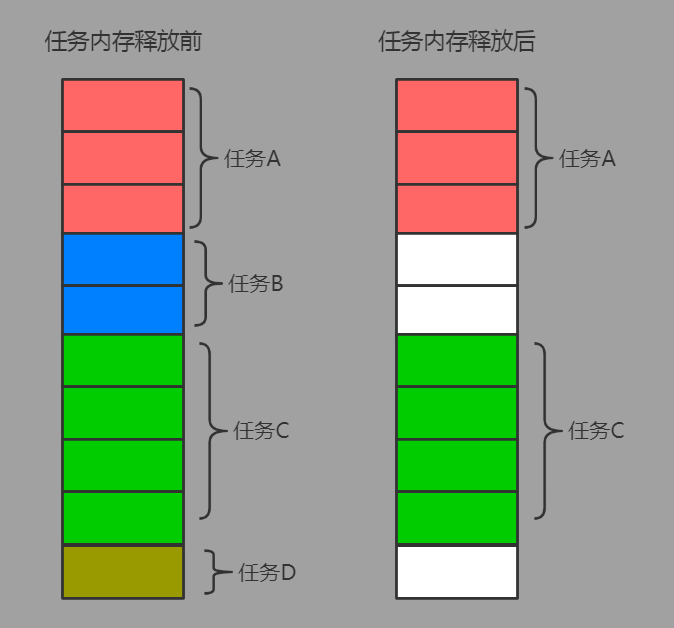
也被稱作“逐段”(By Segment) 或“逐塊”(By Split) 算法,從1.5.x開始引入該算法,該算法的主要思想是,每個Mapper將其所分配到的數據塊,計算成一個完整的小Cube 段(包含所有Cuboid)。每個Mapper將計算完的Cube段輸出給Reducer做合併,生成大Cube,也就是最終結果。如圖所示解釋了此流程。
與舊的逐層構建算法相比,快速算法主要有兩點不同:
-
Mapper會利用內存做預聚合,算出所有組合;Mapper輸出的每個Key都是不同的,這樣會減少輸出到Hadoop MapReduce的數據量,Combiner也不再需要;
-
一輪MapReduce便會完成所有層次的計算,減少Hadoop任務的調配。
11 備份及恢復
Kylin將它全部的元數據(包括cube描述和實例、項目、倒排索引描述和實例、任務、表和字典)組織成層級文件系統的形式。然而,Kylin使用hbase來存儲元數據,而不是一個普通的文件系統。如果你查看過Kylin的配置文件(kylin.properties),你會發現這樣一行:
## The metadata store in hbase
kylin.metadata.url=kylin_metadata@hbase
這表明元數據會被保存在一個叫作“kylin_metadata”的htable里。你可以在hbase shell里scan該htbale來獲取它。
11.1 使用二進制包來備份Metadata Store
有時你需要將Kylin的Metadata Store從hbase備份到磁盤文件系統。在這種情況下,假設你在部署Kylin的hadoop命令行(或沙盒)里,你可以到KYLIN_HOME並運行:
./bin/metastore.sh backup
來將你的元數據導出到本地目錄,這個目錄在KYLIN_HOME/metadata_backps下,它的命名規則使用了當前時間作為參數:KYLIN_HOME/meta_backups/meta_year_month_day_hour_minute_second,如:meta_backups/meta_2020_06_18_19_37_49/
11.2 使用二進制包來恢復Metatdara Store
萬一你發現你的元數據被搞得一團糟,想要恢復先前的備份:
- 首先,重置Metatdara Store(這個會清理Kylin在hbase的Metadata Store的所有信息,請確保先備份):
./bin/metastore.sh reset
- 然後上傳備份的元數據到Kylin的Metadata Store:
./bin/metastore.sh restore $KYLIN_HOME/meta_backups/meta_xxxx_xx_xx_xx_xx_xx
- 等恢復操作完成,可以在“Web UI”的“System”頁面單擊“Reload Metadata”按鈕對元數據緩存進行刷新,即可看到最新的元數據
做完備份,刪除一些文件,然後進行恢複測試,完美恢復,叮叮叮!
12 kylin的垃圾清理
Kylin在構建cube期間會在HDFS上生成中間文件;除此之外,當清理/刪除/合併cube時,一些HBase表可能被遺留在HBase卻以後再也不會被查詢;雖然Kylin已經開始做自動化的垃圾回收,但不一定能覆蓋到所有的情況;你可以定期做離線的存儲清理:
- 檢查哪些資源可以清理,這一步不會刪除任何東西:
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
- 你可以抽查一兩個資源來檢查它們是否已經沒有被引用了;然後加上“–delete true”選項進行清理。
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
完成后,中間HDFS上的中間文件和HTable會被移除。
13 Kylin優化
13.1 維度優化
如果不進行任何維度優化,直接將所有的維度放在一個聚集組裡,Kylin就會計算所有的維度組合(cuboid)。
比如,有12個維度,Kylin就會計算2的12次方即4096個cuboid,實際上查詢可能用到的cuboid不到1000個,甚至更少。 如果對維度不進行優化,會造成集群計算和存儲資源的浪費,也會影響cube的build時間和查詢性能,所以我們需要進行cube的維度優化。
當你在保存cube時遇到下面的異常信息時,意味1個聚集組的維度組合數已經大於 4096 ,你就必須進行維度優化了。
或者發現cube的膨脹率過大。
但在現實情況中,用戶的維度數量一般遠遠大於4個。假設用戶有10 個維度,那麼沒有經過任何優化的Cube就會存在 2的10次方 = 1024個Cuboid;雖然每個Cuboid的大小存在很大的差異,但是單單想到Cuboid的數量就足以讓人想象到這樣的Cube對構建引擎、存儲引擎來說壓力有多麼巨大。因此,在構建維度數量較多的Cube時,尤其要注意Cube的剪枝優化(即減少Cuboid的生成)。
13.2 使用衍生維度
-
衍生維度:維表中可以由主鍵推導出值的列可以作為衍⽣維度。
-
使用場景:以星型模型接入時。例如用戶維表可以從userid推導出用戶的姓名,年齡,性別。
-
優化效果:維度表的N個維度組合成的cuboid個數會從2的N次方降為2。
衍生維度用於在有效維度內將維度表上的非主鍵維度排除掉,並使用維度表的主鍵(其實是事實表上相應的外鍵)來替代它們。Kylin會在底層記錄維度表主鍵與維度表其他維度之間的映射關係,以便在查詢時能夠動態地將維度表的主鍵“翻譯”成這些非主鍵維度,並進行實時聚合。
雖然衍生維度具有非常大的吸引力,但這也並不是說所有維度表上的維度都得變成衍生維度,如果從維度表主鍵到某個維度表維度所需要的聚合工作量非常大,則不建議使用衍生維度。
13.3 使用聚合組(Aggregation group)
聚合組(Aggregation Group)是一種強大的剪枝工具。聚合組假設一個Cube的所有維度均可以根據業務需求劃分成若干組(當然也可以是一個組),由於同一個組內的維度更可能同時被同一個查詢用到,因此會表現出更加緊密的內在關聯。每個分組的維度集合均是Cube所有維度的一個子集,不同的分組各自擁有一套維度集合,它們可能與其他分組有相同的維度,也可能沒有相同的維度。每個分組各自獨立地根據自身的規則貢獻出一批需要被物化的Cuboid,所有分組貢獻的Cuboid的並集就成為了當前Cube中所有需要物化的Cuboid的集合。不同的分組有可能會貢獻出相同的Cuboid,構建引擎會察覺到這點,並且保證每一個Cuboid無論在多少個分組中出現,它都只會被物化一次。
對於每個分組內部的維度,用戶可以使用如下三種可選的方式定義,它們之間的關係,具體如下。
-
強制維度(Mandatory)
-
強制維度:所有cuboid必須包含的維度,不會計算不包含強制維度的cuboid。
-
適用場景:可以將確定在查詢時一定會使用的維度設為強制維度。例如,時間維度。
-
優化效果:將一個維度設為強制維度,則cuboid個數直接減半。
-
如果一個維度被定義為強制維度,那麼這個分組產生的所有Cuboid中每一個Cuboid都會包含該維度。每個分組中都可以有0個、1個或多個強制維度。如果根據這個分組的業務邏輯,則相關的查詢一定會在過濾條件或分組條件中,因此可以在該分組中把該維度設置為強制維度。
-
層級維度(Hierarchy),
-
層級維度:具有一定層次關係的維度。
-
使用場景:像年,月,日;國家,省份,城市這類具有層次關係的維度。
-
優化效果:將N個維度設置為層次維度,則這N個維度組合成的cuboid個數會從2的N次方減少到N+1。
-
每個層級包含兩個或更多個維度。假設一個層級中包含D1,D2…Dn這n個維度,那麼在該分組產生的任何Cuboid中, 這n個維度只會以(),(D1),(D1,D2)…(D1,D2…Dn)這n+1種形式中的一種出現。每個分組中可以有0個、1個或多個層級,不同的層級之間不應當有共享的維度。如果根據這個分組的業務邏輯,則多個維度直接存在層級關係,因此可以在該分組中把這些維度設置為層級維度。
-
聯合維度(Joint),
-
聯合維度:將幾個維度視為一個維度。
-
適用場景:
- 可以將確定在查詢時一定會同時使用的幾個維度設為一個聯合維度。
- 可以將基數很小的幾個維度設為一個聯合維度。
- 可以將查詢時很少使用的幾個維度設為一個聯合維度。
-
優化效果:將N個維度設置為聯合維度,則這N個維度組合成的cuboid個數會從2的N次方減少到1。
-
每個聯合中包含兩個或更多個維度,如果某些列形成一個聯合,那麼在該分組產生的任何Cuboid中,這些聯合維度要麼一起出現,要麼都不出現。每個分組中可以有0個或多個聯合,但是不同的聯合之間不應當有共享的維度(否則它們可以合併成一個聯合)。如果根據這個分組的業務邏輯,多個維度在查詢中總是同時出現,則可以在該分組中把這些維度設置為聯合維度。
這些操作可以在Cube Designer的Advanced Setting中的Aggregation Groups區域完成,如下圖所示。
聚合組的設計非常靈活,甚至可以用來描述一些極端的設計。假設我們的業務需求非常單一,只需要某些特定的Cuboid,那麼可以創建多個聚合組,每個聚合組代表一個Cuboid。具體的方法是在聚合組中先包含某個Cuboid所需的所有維度,然後把這些維度都設置為強制維度。這樣當前的聚合組就只能產生我們想要的那一個Cuboid了。
再比如,有的時候我們的Cube中有一些基數非常大的維度,如果不做特殊處理,它就會和其他的維度進行各種組合,從而產生一大堆包含它的Cuboid。包含高基數維度的Cuboid在行數和體積上往往非常龐大,這會導致整個Cube的膨脹率變大。如果根據業務需求知道這個高基數的維度只會與若干個維度(而不是所有維度)同時被查詢到,那麼就可以通過聚合組對這個高基數維度做一定的“隔離”。我們把這個高基數的維度放入一個單獨的聚合組,再把所有可能會與這個高基數維度一起被查詢到的其他維度也放進來。這樣,這個高基數的維度就被“隔離”在一個聚合組中了,所有不會與它一起被查詢到的維度都沒有和它一起出現在任何一個分組中,因此也就不會有多餘的Cuboid產生。這點也大大減少了包含該高基數維度的Cuboid的數量,可以有效地控制Cube的膨脹率。
13.4 併發粒度優化
當Segment中某一個Cuboid的大小超出一定的閾值時,系統會將該Cuboid的數據分片到多個分區中,以實現Cuboid數據讀取的并行化,從而優化Cube的查詢速度。具體的實現方式如下:構建引擎根據Segment估計的大小,以及參數“kylin.hbase.region.cut”的設置決定Segment在存儲引擎中總共需要幾個分區來存儲,如果存儲引擎是HBase,那麼分區的數量就對應於HBase中的Region數量。kylin.hbase.region.cut的默認值是5.0,單位是GB,也就是說對於一個大小估計是50GB的Segment,構建引擎會給它分配10個分區。用戶還可以通過設置kylin.hbase.region.count.min(默認為1)和kylin.hbase.region.count.max(默認為500)兩個配置來決定每個Segment最少或最多被劃分成多少個分區。
由於每個Cube的併發粒度控制不盡相同,因此建議在Cube Designer 的Configuration Overwrites(上圖所示)中為每個Cube量身定製控制併發粒度的參數。假設將把當前Cube的kylin.hbase.region.count.min設置為2,kylin.hbase.region.count.max設置為100。這樣無論Segment的大小如何變化,它的分區數量最小都不會低於2,最大都不會超過100。相應地,這個Segment背後的存儲引擎(HBase)為了存儲這個Segment,也不會使用小於兩個或超過100個的分區。我們還調整了默認的kylin.hbase.region.cut,這樣50GB的Segment基本上會被分配到50個分區,相比默認設置,我們的Cuboid可能最多會獲得5倍的併發量。
13.5 Row Key優化
Kylin會把所有的維度按照順序組合成一個完整的Rowkey,並且按照這個Rowkey升序排列Cuboid中所有的行。
設計良好的Rowkey將更有效地完成數據的查詢過濾和定位,減少IO次數,提高查詢速度,維度在rowkey中的次序,對查詢性能有顯著的影響。
Row key的設計原則如下:
- 被用作where過濾的維度放在前邊。
- 基數大的維度放在基數小的維度前邊。
13.6 增量cube構建
構建全量cube,也可以實現增量cube的構建,就是通過分區表的分區時間字段來進行增量構建
- 更改model
- 更改cube
14 Kafka 流構建 Cube(Kylin實時案例)
Kylin v1.6 發布了可擴展的 streaming cubing 功能,它利用 Hadoop 消費 Kafka 數據的方式構建 cube。
參考:http://kylin.apache.org/blog/2016/10/18/new-nrt-streaming/
前期準備:kylin v1.6.0 或以上版本 和 可運行的 Kafka(v0.10.0 或以上版本)的 Hadoop 環境
14.1 Kafka創建Topic
- 創建樣例名為 “kylin_streaming_topic” 具有一個副本三個分區的 topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kylin_streaming_topic
- 將樣例數據放入 topic,Kylin 有一個實用類可以做這項工作;
cd $KYLIN_HOME
./bin/kylin.sh org.apache.kylin.source.kafka.util.KafkaSampleProducer --topic kylin_streaming_topic --broker cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092
工具每一秒會向 Kafka 發送 100 條記錄。直至本案例結束請讓其一直運行。
14.2 用streaming定義一張表
登陸 Kylin Web GUI,選擇一個已存在的 project 或創建一個新的 project;點擊 “Model” -> “Data Source”,點擊 “Add Streaming Table” 圖標
- 在彈出的對話框中,輸入您從 kafka-console-consumer 中獲得的樣例記錄,點擊 “»” 按鈕,Kylin 會解析 JSON 消息並列出所有的消息
{"country":"CHINA","amount":41.53789973661185,"qty":6,"currency":"USD","order_time":1592485535129,"category":"TOY","device":"iOS","user":{"gender":"Male","id":"12d127ab-707e-592f-2e4c-69ad654afa48","first_name":"unknown","age":25}}
-
您需要為這個 streaming 數據源起一個邏輯表名;該名字會在後續用於 SQL 查詢;這裡是在 “Table Name” 字段輸入 “STREAMING_SALES_TABLE” 作為樣例。
-
您需要選擇一個時間戳字段用來標識消息的時間;Kylin 可以從這列值中獲得其他時間值,如 “year_start”,”quarter_start”,這為您構建和查詢 cube 提供了更高的靈活性。這裏可以查看 “order_time”。您可以取消選擇那些 cube 不需要的屬性。這裏我們保留了所有字段。
-
注意 Kylin 從 1.6 版本開始支持結構化 (或稱為 “嵌入”) 消息,會將其轉換成一個 flat table structure。默認使用 “_” 作為結構化屬性的分隔符。
- 點擊 “Next”。在這個頁面,提供了 Kafka 集群信息;輸入 “kylin_streaming_topic” 作為 “Topic” 名;集群有 3 個 broker,其主機名為”cdh01.cm,cdh02.cm,cdh03.cm“,端口為 “9092”,點擊 “Save”。
-
在 “Advanced setting” 部分,”timeout” 和 “buffer size” 是和 Kafka 進行連接的配置,保留它們。
-
在 “Parser Setting”,Kylin 默認您的消息為 JSON 格式,每一個記錄的時間戳列 (由 “tsColName” 指定) 是 bigint (新紀元時間) 類型值;在這個例子中,您只需設置 “tsColumn” 為 “order_time”;
- 在現實情況中如果時間戳值為 string 如 “Jul 20,2016 9:59:17 AM”,您需要用 “tsParser” 指定解析類和時間模式例如:
- 點擊 “Submit” 保存設置。現在 “Streaming” 表就創建好了。
14.3 定義數據模型
-
有了上一步創建的表,現在我們可以創建數據模型了。步驟和您創建普通數據模型是一樣的,但有兩個要求:
- Streaming Cube 不支持與 lookup 表進行 join;當定義數據模型時,只選擇 fact 表,不選 lookup 表;
- Streaming Cube 必須進行分區;如果您想要在分鐘級別增量的構建 Cube,選擇 “MINUTE_START” 作為 cube 的分區日期列。如果是在小時級別,選擇 “HOUR_START”。
-
這裏我們選擇 13 個 dimension 和 2 個 measure 列:
保存數據模型。
14.4 創建 Cube
Streaming Cube 和普通的 cube 大致上一樣. 有以下幾點需要您注意:
- 分區時間列應該是 Cube 的一個 dimension。在 Streaming OLAP 中時間總是一個查詢條件,Kylin 利用它來縮小掃描分區的範圍。
- 不要使用 “order_time” 作為 dimension 因為它非常的精細;建議使用 “mintue_start”,”hour_start” 或其他,取決於您如何檢查數據。
- 定義 “year_start”,”quarter_start”,”month_start”,”day_start”,”hour_start”,”minute_start” 作為層級以減少組合計算。
- 在 “refersh setting” 這一步,創建更多合併的範圍,如 0.5 小時,4 小時,1 天,然後是 7 天;這將會幫助您控制 cube segment 的數量。
- 在 “rowkeys” 部分,拖拽 “minute_start” 到最上面的位置,對於 streaming 查詢,時間條件會一直显示;將其放到前面將會幫助您縮小掃描範圍。
保存 cube。
14.5 運行Cube
可以在 web GUI 觸發 build,通過點擊 “Actions” -> “Build”,或用 ‘curl’ 命令發送一個請求到 Kylin RESTful API:
curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://localhost:7070/kylin/api/cubes/{your_cube_name}/build2
請注意 API 終端和普通 cube 不一樣 (這個 URL 以 “build2” 結尾)。
這裏的 0 表示從最後一個位置開始,9223372036854775807 (Long 類型的最大值) 表示到 Kafka topic 的結束位置。如果這是第一次 build (沒有以前的 segment),Kylin 將會尋找 topics 的開頭作為開始位置。
在 “Monitor” 頁面,一個新的 job 生成了;等待其直到 100% 完成。
14.6 查看結果
點擊 “Insight” 標籤,編寫 SQL 運行,例如:
select minute_start, count(*), sum(amount), sum(qty) from streaming_sales_table group by minute_start order by minute_start
14.7 自動 build
一旦第一個 build 和查詢成功了,您可以按照一定的頻率調度增量 build。Kylin 將會記錄每一個 build 的 offsets;當收到一個 build 請求,它將會從上一個結束的位置開始,然後從 Kafka 獲取最新的 offsets。有了 REST API 您可以使用任何像 Linux cron 調度工具觸發它:
crontab -e
*/5 * * * * curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://localhost:7070/kylin/api/cubes/{your_cube_name}/build2
現在您可以觀看 cube 從 streaming 中自動 built。當 cube segments 累積到更大的時間範圍,Kylin 將會自動的將其合併到一個更大的 segment 中。
15 JDBC查詢kylin
- maven依賴
<dependencies>
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 限制jdk版本插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
- java類
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class KylinJdbc {
public static void main(String[] args) throws Exception {
//Kylin_JDBC 驅動
String KYLIN_DRIVER = "org.apache.kylin.jdbc.Driver";
//Kylin_URL
String KYLIN_URL = "jdbc:kylin://localhost:9090/kylin_hive";
//Kylin的用戶名
String KYLIN_USER = "ADMIN";
//Kylin的密碼
String KYLIN_PASSWD = "KYLIN";
//添加驅動信息
Class.forName(KYLIN_DRIVER);
//獲取連接
Connection connection = DriverManager.getConnection(KYLIN_URL, KYLIN_USER, KYLIN_PASSWD);
//預編譯SQL
PreparedStatement ps = connection.prepareStatement("SELECT sum(sal) FROM emp group by deptno");
//執行查詢
ResultSet resultSet = ps.executeQuery();
//遍歷打印
while (resultSet.next()) {
System.out.println(resultSet.getInt(1));
}
}
}
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※聚甘新