WebSSH終端錄像的實現終於來了
前邊寫了兩篇文章和深入介紹了終端錄製工具Asciinema,我們已經可以實現在終端下對操作過程的錄製,那麼在WebSSH中的操作該如何記錄並提供後續的回放審計呢?
一種方式是文章最後介紹的自動錄製審計日誌的方法,在主機上添加個腳本,每次連接自動進行錄製,但這樣不僅要在每台遠程主機添加腳本,會很繁瑣,而且錄製的腳本文件都是放在遠程主機上的,後續播放也很麻煩
那該如何更好處理呢?下文介紹一種優雅的方式來實現,核心思想是不通過錄製命令進行錄製,而在Webssh交互執行的過程中直接生成可播放的錄像文件
設計思路
通過上邊兩篇文章的閱讀,我們已經知道了Asciinema錄像文件主要由兩部分組成:header頭和IO流數據
header頭位於文件的第一行,定義了這個錄像的版本、寬高、開始時間、環境變量等參數,我們可以在websocket連接創建時將這些參數按照需要的格式寫入到文件
header頭數據如下,只有開頭一行,是一個字典形式
{"version": 2, "width": 213, "height": 55, "timestamp": 1574155029.1815443, "env": {"SHELL": "/bin/bash", "TERM": "xterm-256color"}, "title": "ops-coffee"}整個錄像文件除了第一行的header頭部分,剩下的就都是輸入輸出的IO流數據,從websocket連接建立開始,隨着操作的進行,IO流數據是不斷增加的,直到整個websocket長連接的結束,那就需要在整個WebSSH交互的過程中不斷的往錄像文件追加輸入輸出的內容
IO流數據如下,每一行一條,列表形式,分別表示操作時間,輸入或輸出(這裏我們為了方便就寫固定字符串輸出),IO數據
[0.2341010570526123, "o", "Last login: Tue Nov 19 17:11:30 2019 from 192.168.105.91\r\r\n"]似乎很完美,按照上邊的思路錄像文件就應該沒有問題了,但還有一些細節需要處理
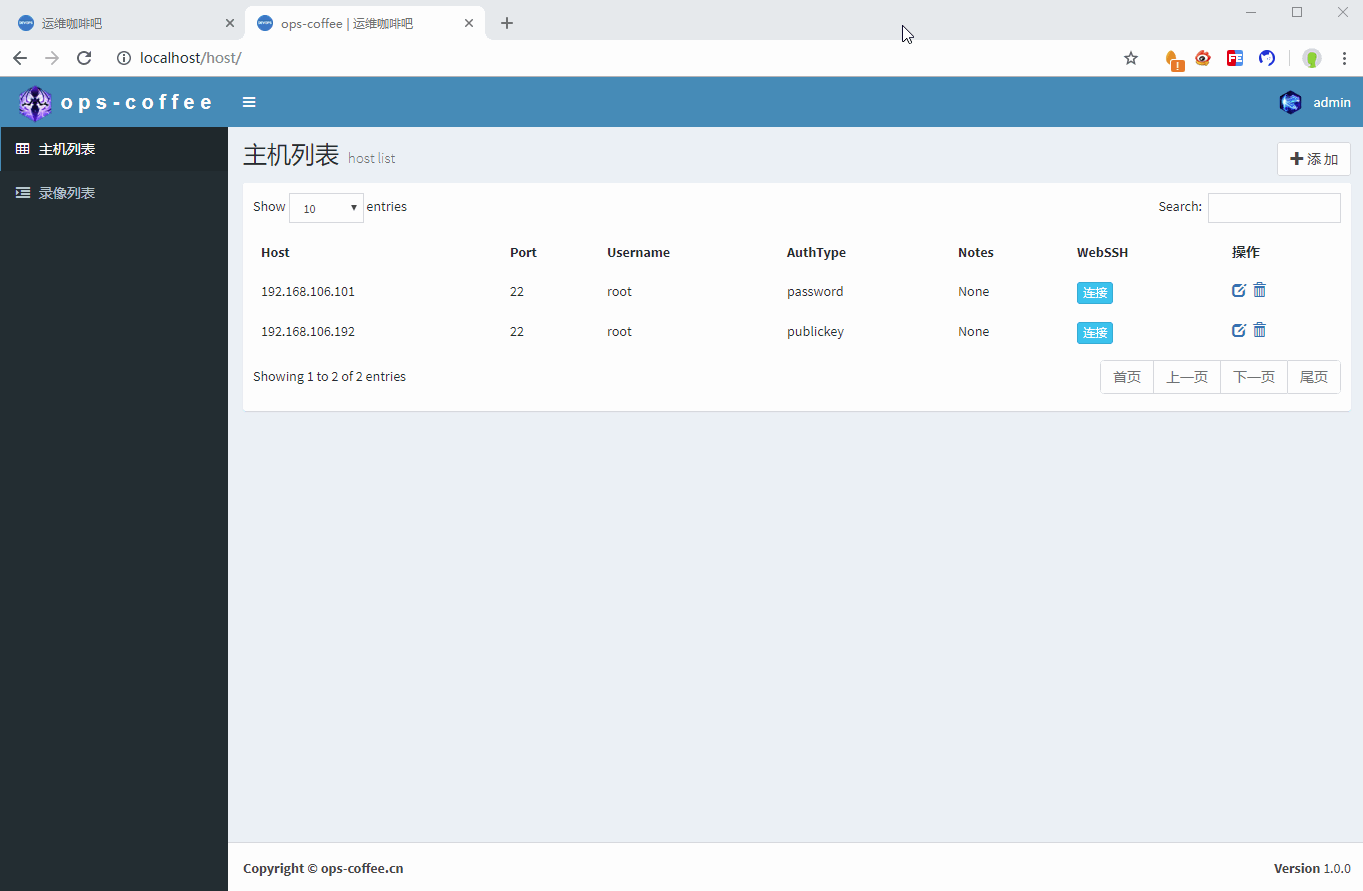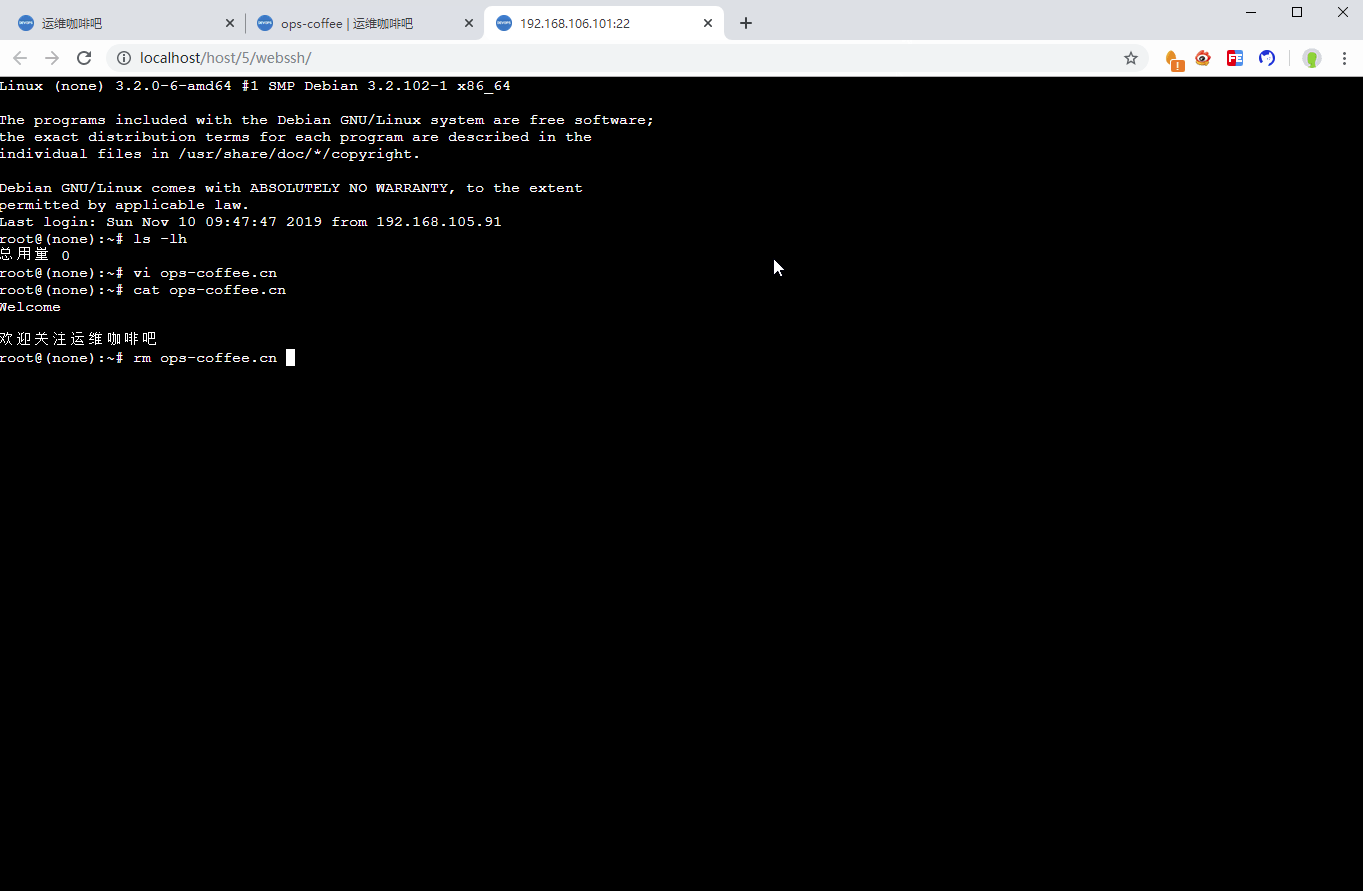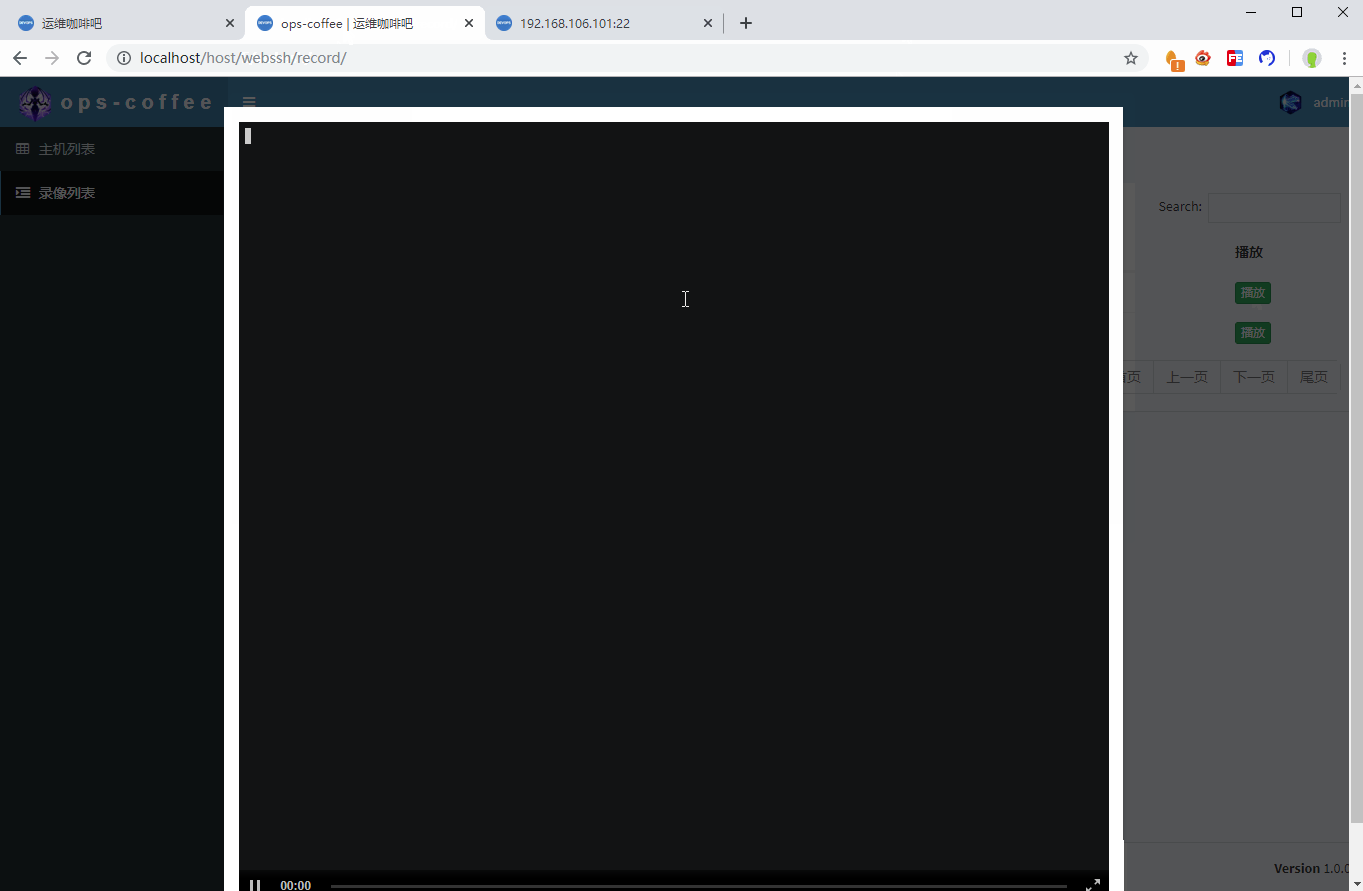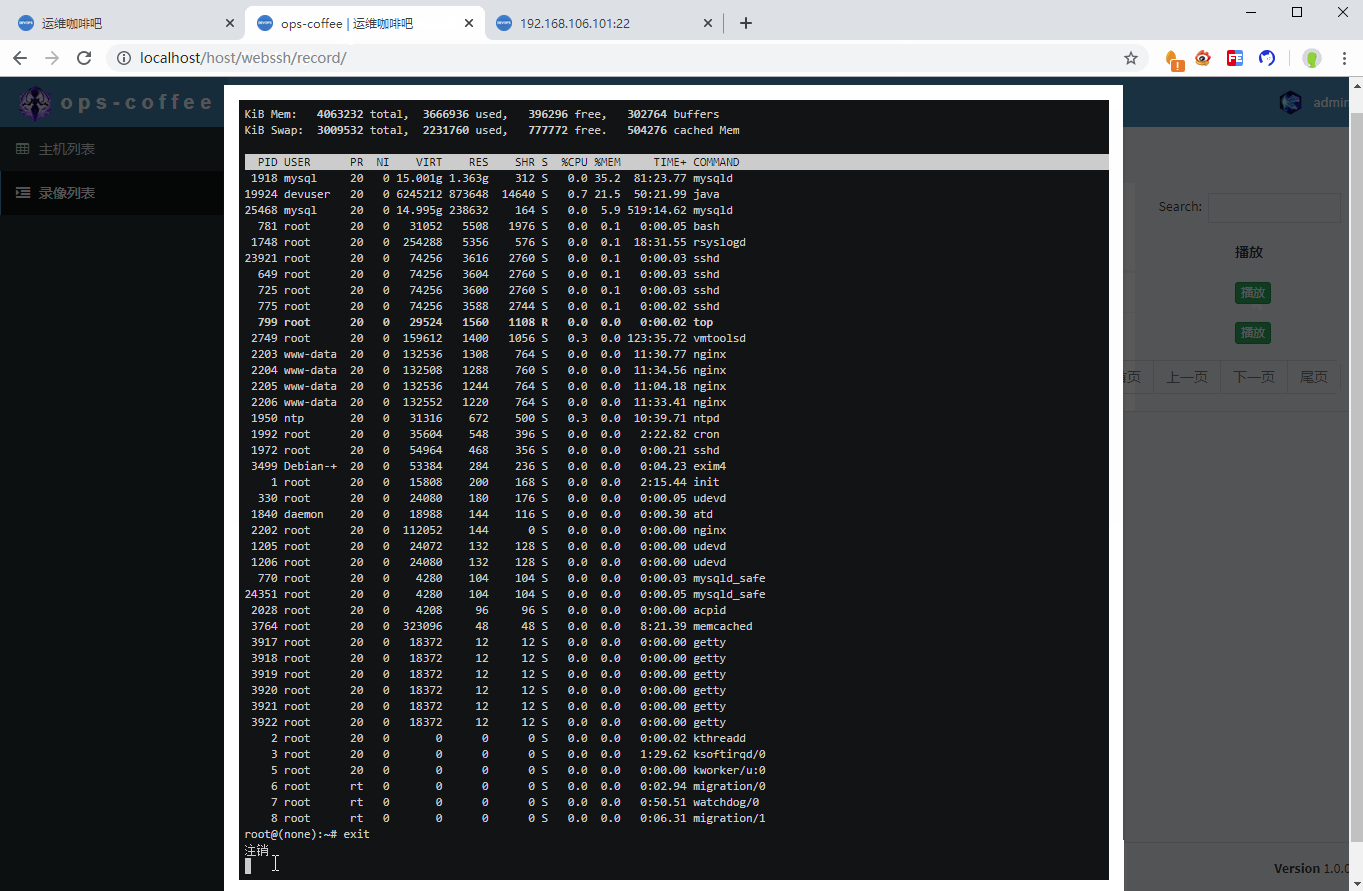
首先是需要歷史連接列表,在這個列表裡可以看到什麼時間,哪個用戶連接了哪台主機,當然也需要提供回放功能,新建一張表來記錄這些信息
class Record(models.Model):
create_time = models.DateTimeField(auto_now_add=True, verbose_name='創建時間')
host = models.ForeignKey(Host, on_delete=models.CASCADE, verbose_name='主機')
user = models.ForeignKey(User, on_delete=models.CASCADE, verbose_name='用戶')
filename = models.CharField(max_length=128, verbose_name='錄像文件名稱')
def __str__(self):
return self.host其次還需要考慮的一個問題是header和後續IO數據流要寫入同一個文件,這就需要在整個websocket的連接過程中有一個固定的文件名可被讀取,這裏我使用了主機+用戶+當前時間作為文件名,同一用戶在同一時間不能多次連接同一主機,這樣可保證文件名不重複,同時避免操作寫入錯誤的錄像文件,文件名在websocket建立時初始化
def __init__(self, host, user, websocket):
self.host = host
self.user = user
self.time = time.time()
self.filename = '%s.%s.%d.cast' % (host, user, self.time)IO流數據會持續不斷的寫入文件,這裏以一個獨立的方法來處理寫入
def record(self, type, data):
RECORD_DIR = settings.BASE_DIR + '/static/record/'
if not os.path.isdir(RECORD_DIR):
os.makedirs(RECORD_DIR)
if type == 'header':
Record.objects.create(
host=Host.objects.get(id=self.host),
user=self.user,
filename=self.filename
)
with open(RECORD_DIR + self.filename, 'w') as f:
f.write(json.dumps(data) + '\n')
else:
iodata = [time.time() - self.time, 'o', data]
with open(RECORD_DIR + self.filename, 'a', buffering=1) as f:
f.write((json.dumps(iodata) + '\n'))record接收兩個參數type和data,type標識本次寫入的是header頭還是IO流,data則是具體的數據
header只需要執行一次寫入,所以將其放在ssh的connect方法中,只在ssh連接建立時執行一次,在執行header寫入時同時往數據庫插入新的歷史記錄數據
調用record方法寫入header
def connect(self, host, port, username, authtype, password=None, pkey=None,
term='xterm-256color', cols=80, rows=24):
...
# 構建錄像文件header
self.record('header', {
"version": 2,
"width": cols,
"height": rows,
"timestamp": self.time,
"env": {
"SHELL": "/bin/bash",
"TERM": term
},
"title": "ops-coffee"
})IO流數據則需要與返回給前端的數據保持一致,這樣就能保證前端显示什麼錄像就播放什麼了,所以所有需要返回前端數據的地方都同時寫入錄像文件即可
調用record方法寫入io流數據
def connect(self, host, port, username, authtype, password=None, pkey=None,
term='xterm-256color', cols=80, rows=24):
...
# 連接建立一次,之後交互數據不會再進入該方法
for i in range(2):
recv = self.ssh_channel.recv(65535).decode('utf-8', 'ignore')
message = json.dumps({'flag': 'success', 'message': recv})
self.websocket.send(message)
self.record('iodata', recv)
...
def _ssh_to_ws(self):
try:
with self.lock:
while not self.ssh_channel.exit_status_ready():
data = self.ssh_channel.recv(1024).decode('utf-8', 'ignore')
if len(data) != 0:
message = {'flag': 'success', 'message': data}
self.websocket.send(json.dumps(message))
self.record('iodata', data)
else:
break
except Exception as e:
message = {'flag': 'error', 'message': str(e)}
self.websocket.send(json.dumps(message))
self.record('iodata', str(e))
self.close()由於命令執行與返回都是多線程的操作,這就會導致在寫入文件時出現文件亂序影響播放的問題,典型的操作有vim、top等,通過加鎖self.lock可以順利解決
最後歷史記錄頁面,當用戶點擊播放按鈕時,調用js彈出播放窗口
<div class="modal fade" id="modalForm">
<div class="modal-dialog modal-lg">
<div class="modal-content">
<div class="modal-body" id="play">
</div>
</div>
</div>
</div>
// 播放錄像
function play(host,user,time,file) {
$('#play').html(
'<asciinema-player id="play" title="WebSSH Record" author="ops-coffee.cn" author-url="https://ops-coffee.cn" author-img-url="/static/img/logo.png" src="/static/record/'+file+'" speed="3" '+
'idle-time-limit="2" poster="data:text/plain,\x1b[1;32m'+time+
'\x1b[1;0m用戶\x1b[1;32m'+user+
'\x1b[1;0m連接主機\x1b[1;32m'+host+
'\x1b[1;0m的錄像記錄"></asciinema-player>'
)
$('#modalForm').modal('show');
}asciinema-player標籤的詳細參數介紹可以看這篇文章
演示與總結
在寫入文件的方案中,考慮了實時寫入和一次性寫入,實時寫入就像上邊這樣,所有的操作都會實時寫入錄像文件,好處是錄像不丟失,且能在操作的過程中進行實時的播放,缺點也很明顯,就是會頻繁的寫文件,造成IO開銷
一次性寫入可以在用戶操作的過程中將錄像數據寫入內存,在websocket關閉時一次性異步寫入到文件中,這種方案在最終寫入文件時可能因為種種原因而失敗,從而導致錄像丟失,還有個缺點是當你WebSSH操作時間過長時,會導致內存的持續增加
兩種方案一種是對磁盤的消耗另一種是對內存的消耗,各有利弊,當然你也可以考慮批量寫入,例如每分鐘寫一次文件,一分鐘之內的保存在內存中,平衡內存和磁盤的消耗,期待你的實現
相關文章推薦閱讀:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益