環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
如何商品強力曝光吸引人們的目光,想了解身邊生活上的大小事物。
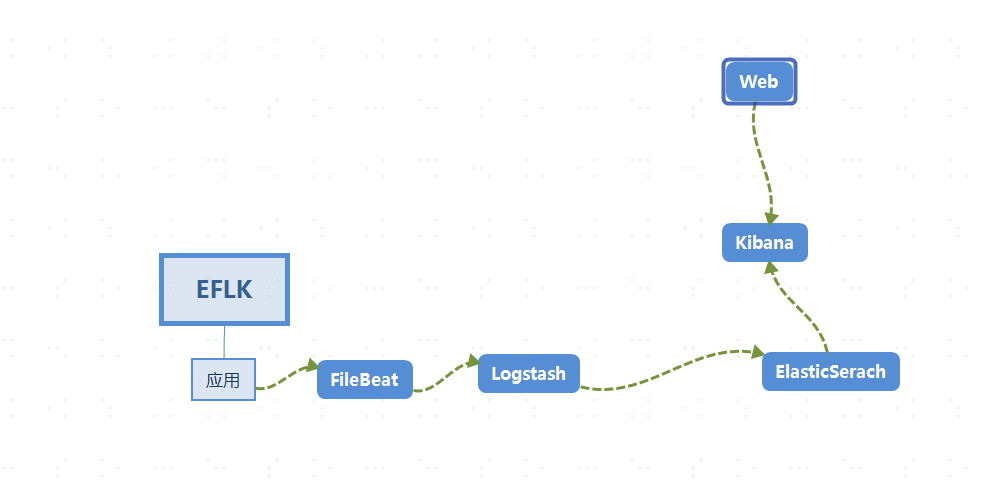
經過上周的技術預研,在本周一通過開會研究,根據公司的現有業務流量和技術棧,決定選擇的日誌系統方案為:elasticsearch(es)+logstash(lo)+filebeat(fi)+kibana(ki)組合。es選擇使用aliyun提供的es,lo&fi選擇自己部署,ki是阿里雲送的。因為申請ecs需要一定的時間,暫時選擇部署在測試&生產環境(吐槽一下,我司測試和生產公用一套k8s並且託管與aliyun……)。用時一天(前期有部署的差不多過)完成在kubernetes上部署完成elfk(先部署起來再說,優化什麼的後期根據需要再搞)。
es 是一個實時的、分佈式的可擴展的搜索引擎,允許進行全文、結構化搜索,它通常用於索引和搜索大量日誌數據,也可用於搜索許多不同類型的文。
lo 主要的有點就是它的靈活性,主要因為它有很多插件,詳細的文檔以及直白的配置格式讓它可以在多種場景下應用。我們基本上可以在網上找到很多資源,幾乎可以處理任何問題。
作為 Beats 家族的一員,fi 是一個輕量級的日誌傳輸工具,它的存在正彌補了 lo 的缺點fi作為一個輕量級的日誌傳輸工具可以將日誌推送到中心lo。
ki是一個分析和可視化平台,它可以瀏覽、可視化存儲在es集群上排名靠前的日誌數據,並構建儀錶盤。ki結合es操作簡單集成了絕大多數es的API,是專業的日誌展示應用。
日誌流向:logs_data—> fi —> lo —> es—> ki。
logs_data通過fi收集日誌,輸出到lo,通過lo做一些過濾和修改之後傳送到es數據庫,ki讀取es數據庫做分析。
根據我司的實際集群狀況,此文檔部署將完全還原日誌系統的部署情況。
在客戶端(隨便本地一台虛機上)安裝和託管的k8s一樣版本的kubectl
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.14.8/bin/linux/amd64/kubectl
chmod +x ./kubectl
mv ./kubectl /usr/local/bin/kubectl
將阿里雲託管的k8s的kubeconfig 複製到$HOME/.kube/config 目錄下,注意用戶權限的問題
申請一個名稱空間(一般一個項目一個名稱空間)。
# cat kube-logging.yaml
apiVersion: v1
kind: Namespace
metadata:
name: loging
部署es。網上找個差不多的資源清單,根據自己的需求進行適當的修改,運行,出錯就根據日誌進行再修改。
# cat elasticsearch.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-class
namespace: loging
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
# Supported policies: Delete, Retain
reclaimPolicy: Delete
---
kind: PersistentVolume
apiVersion: v1
metadata:
name: datadir1
namespace: logging
labels:
type: local
spec:
storageClassName: local-class
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/data1"
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: loging
spec:
serviceName: elasticsearch
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.3.1
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: "discovery.type"
value: "single-node"
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "local-class"
resources:
requests:
storage: 5Gi
---
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: loging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
部署ki。因為根據數據採集流程圖,ki是和es結合的,配置相對簡單。
# cat kibana.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kibana
namespace: loging
labels:
k8s-app: kibana
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana
template:
metadata:
labels:
k8s-app: kibana
spec:
containers:
- name: kibana
image: kibana:7.3.1
resources:
limits:
cpu: 1
memory: 500Mi
requests:
cpu: 0.5
memory: 200Mi
env:
- name: ELASTICSEARCH_HOSTS
#注意value是es的services,因為es是有狀態,用的無頭服務,所以連接的就不僅僅是pod的名字了
value: http://elasticsearch:9200
ports:
- containerPort: 5601
name: ui
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: loging
spec:
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana
配置ingress-controller。因為我司用的是阿里雲託管的k8s自帶的nginx-ingress,並且配置了強制轉換https。所以kibana-ingress也要配成https。
# openssl genrsa -out tls.key 2048
# openssl req -new -x509 -key tls.key -out tls.crt -subj /C=CN/ST=Beijing/L=Beijing/O=DevOps/CN=kibana.test.realibox.com
# kubectl create secret tls kibana-ingress-secret --cert=tls.crt --key=tls.key
kibana-ingress配置如下。提供兩種,一種是https,一種是http。
https:
# cat kibana-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: loging
spec:
tls:
- hosts:
- kibana.test.realibox.com
secretName: kibana-ingress-secret
rules:
- host: kibana.test.realibox.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
http:
# cat kibana-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: loging
spec:
rules:
- host: kibana.test.realibox.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
部署lo。因為lo的作用是對fi收集到的日誌進行過濾,需要根據不同的日誌做不同的處理,所以可能要經常性的進行改動,要進行解耦。所以選擇以configmap的形式進行掛載。
# cat logstash.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: logstash
namespace: loging
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: elastic/logstash:7.3.1
volumeMounts:
- name: config
mountPath: /opt/logstash/config/containers.conf
subPath: containers.conf
command:
- "/bin/sh"
- "-c"
- "/opt/logstash/bin/logstash -f /opt/logstash/config/containers.conf"
volumes:
- name: config
configMap:
name: logstash-k8s-config
---
apiVersion: v1
kind: Service
metadata:
labels:
app: logstash
name: logstash
namespace: loging
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: logstash
type: ClusterIP
# cat logstash-config.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: logstash
name: logstash
namespace: loging
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: logstash
type: ClusterIP
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-k8s-config
namespace: loging
data:
containers.conf: |
input {
beats {
port => 8080 #filebeat連接端口
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"] #es的service
index => "logstash-%{+YYYY.MM.dd}"
}
}
注意:修改configmap 相當於修改鏡像。必須重新apply 應用資源清單才能生效。根據數據採集流程圖,lo的數據由fi流入,流向es。
部署fi。fi的主要作用是進行日誌的採集,然後將數據交給lo。
# cat filebeat.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: loging
labels:
app: filebeat
data:
filebeat.yml: |-
filebeat.config:
inputs:
# Mounted `filebeat-inputs` configmap:
path: ${path.config}/inputs.d/*.yml
# Reload inputs configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
# To enable hints based autodiscover, remove `filebeat.config.inputs` configuration and uncomment this:
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# hints.enabled: true
output.logstash:
hosts: ['${LOGSTASH_HOST:logstash}:${LOGSTASH_PORT:8080}'] #流向lo
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-inputs
namespace: loging
labels:
app: filebeat
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: loging
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: elastic/filebeat:7.3.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env: #注入變量
- name: LOGSTASH_HOST
value: logstash
- name: LOGSTASH_PORT
value: "8080"
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: inputs
mountPath: /usr/share/filebeat/inputs.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: loging
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: loging
labels:
app: filebeat
---
至此完成在k8s上部署es+lo+fi+ki ,進行簡單驗證。
查看svc、pod、ingress信息
# kubectl get svc,pods,ingress -n loging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 151m
service/kibana ClusterIP xxx.168.239.2xx <none> 5601/TCP 20h
service/logstash ClusterIP xxx.168.38.1xx <none> 8080/TCP 122m
NAME READY STATUS RESTARTS AGE
pod/elasticsearch-0 1/1 Running 0 151m
pod/filebeat-24zl7 1/1 Running 0 118m
pod/filebeat-4w7b6 1/1 Running 0 118m
pod/filebeat-m5kv4 1/1 Running 0 118m
pod/filebeat-t6x4t 1/1 Running 0 118m
pod/kibana-689f4bd647-7jrqd 1/1 Running 0 20h
pod/logstash-76bc9b5f95-qtngp 1/1 Running 0 122m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/kibana kibana.test.realibox.com xxx.xx.xx.xxx 80, 443 19h
配置索引
發現
至此算是簡單完成。後續需要不斷優化,不過那是後事了。
這應該算是第一次親自在測試&生產環境部署應用了,而且是自己很不熟悉的日子系統,遇到了很多問題,需要總結。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
上一篇說了mysql的架構圖,很多同學反饋說不過癮,畢竟還是聽我講故事,那這篇就來說一說怎麼利用visual studio 對 mysql進行源碼級調試,畢竟源碼面前,不談隱私,聖人面前,皆為螻蟻。
mysql是C++寫的,要想在windows上編譯,還需要下載幾個必備小工具。
這裏簡單說一下:可以用 cmake 將源碼生成 *.sln 可打開的解決方案,比如可以通過它最終生成 MySQL.sln。boost 是C++中非常強大的基礎庫,bison 一個流行的語法分析器程序,用於給mysql提供語法分析,最後就是下載正確的mysql版本5.7.12。
我會寫的比較細,畢竟我也花了一下午時間,寒酸(┬_┬)
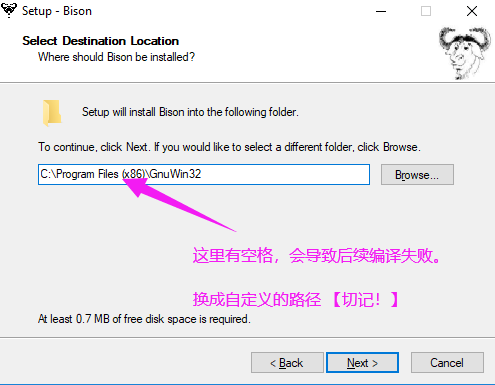
cmake 和 bison 安裝起來比較方便,一鍵安裝就可以了,不過這裡有一個大坑注意了,在安裝Bison的時候,千萬不要使用默認路徑,因為默認路徑有空格,會導致你後面vs編譯的時候卡住,又不显示什麼原因,可氣!!! 所以我換成自定義的: C:\2\GnuWin32。
最後確保 cmake 和 bison 的bin文件都在 環境變量中即可。
這裏我用 C:\2作為根文件夾,所有的小工具都在這裏,如圖:
接下來將 mysql-5.7.12.zip 解壓一下,然後進入解壓后的文件夾,新建一個boost文件夾,將boost_1_59_0.tar.gz放入其中,然後再新建一個 brelease 文件夾可用於存放最終生成的MySql.sln。。
都準備好了之後,可以開始cmake編譯了。
PS C:\2\mysql-5.7.12\brelease> cmake .. -DDOWNLOAD_BOOST=1 -DWITH_BOOST="C:\2\mysql-5.7.12\boost\boost_1_59_0.tar.gz"
-- Building for: Visual Studio 16 2019
CMake Deprecation Warning at CMakeLists.txt:26 (CMAKE_POLICY):
The OLD behavior for policy CMP0018 will be removed from a future version
of CMake.
-- Cannot find wix 3, installer project will not be generated
-- COMPILE_DEFINITIONS: _WIN32_WINNT=0x0601;WIN32_LEAN_AND_MEAN;NOGDI;NOMINMAX;HAVE_CONFIG_H
-- CMAKE_C_FLAGS: /DWIN32 /D_WINDOWS /W3 /MP /wd4800 /wd4805 /wd4996
-- CMAKE_CXX_FLAGS: /DWIN32 /D_WINDOWS /W3 /GR /EHsc /MP /wd4800 /wd4805 /wd4996 /we4099
-- CMAKE_C_FLAGS_DEBUG: /MTd /Z7 /Ob1 /Od /RTC1 /EHsc -DENABLED_DEBUG_SYNC -DSAFE_MUTEX
-- CMAKE_CXX_FLAGS_DEBUG: /MTd /Z7 /Ob1 /Od /RTC1 /EHsc -DENABLED_DEBUG_SYNC -DSAFE_MUTEX
-- CMAKE_C_FLAGS_RELWITHDEBINFO: /MT /Z7 /O2 /Ob1 /DNDEBUG /EHsc -DDBUG_OFF
-- CMAKE_CXX_FLAGS_RELWITHDEBINFO: /MT /Z7 /O2 /Ob1 /DNDEBUG /EHsc -DDBUG_OFF
-- Configuring done
-- Generating done
-- Build files have been written to: C:/2/mysql-5.7.12/brelease
當看到最後一句 Build files have been written to: C:/2/mysql-5.7.12/brelease,恭喜你,MySQL.sln生成好了。
我的電腦安裝的是visual studio 2019,接下來打開MySql.Sln整體編譯,需要等個十幾分鐘,看到下面的輸出就算安裝成功。
這裏要做兩件事情,第一件事是將mysql的調試模式打開,第二件事就是附加 --initialize 啟動參數。
修改C:\2\mysql-5.7.12\sql\mysqld.cc中的 test_lc_time_sz方法中的 DBUG_ASSERT(0); 改成 DBUG_ASSERT(1); 如下圖:
上一篇大家都知道了,mysqld項目是mysql的啟動項目,main函數也在其中,在F5調試之前增加初始化參數 --console --initialize,如下圖:
啟動之後,有103個報錯,氣人呀。。。看錯誤信息應該是編碼問題,如下圖:
修改起來也很簡單,將 C:\2\mysql-5.7.12\sqlsql_locale.cc 用 [utf-8 + BOM] 格式保存一下,然後對mysqld項目Rebuild再Ctrl+F5直接運行,終於謝天謝地,從輸出可以看到,搞定啦。。。太不容易啦。
從上圖中可以看到,默認密碼是:zJDE>IC5o+ya,先記錄下這個密碼,然後再把CommandLine Arguments 中的–initialize去掉再重啟Console。
可以看到,3306端口已開啟,然後用剛才的 zJDE>IC5o+ya 連接即可,這裏我使用navicat。
連接上去後會提示修改默認密碼,設置我就設置為:123456 ,嘿嘿,一切搞定~~~
上一篇我們追蹤到了 write_row 就斷掉了,我當時說它是一個虛方法,由底層具體的存儲引擎去調用,代碼如下:
int handler::ha_write_row(uchar *buf)
{
MYSQL_TABLE_IO_WAIT(m_psi, PSI_TABLE_WRITE_ROW, MAX_KEY, 0,{ error= write_row(buf); })
}
//這是一個虛方法
virtual int write_row(uchar *buf __attribute__((unused)))
{
return HA_ERR_WRONG_COMMAND;
}
到底這話虛不虛,這次我親自調試一下給大家看看,證據先行哈。。。為了方便,我生成一條創表sql。
drop database if exists `datamip`;
create database `datamip`;
drop table if exists `datamip`.`customer`;
create table `datamip`.`customer` (
`customerID` int NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
`customerName` varchar(50) COMMENT '用戶姓名',
`email` varchar(50) COMMENT '郵箱地址',
`desc` varchar(50) COMMENT '描述',
primary key (`customerID`)
) ENGINE=InnoDB charset=utf8 collate=utf8_bin;
接下來,大家看仔細了,在源碼 int handler::ha_write_row(uchar *buf) 方法處下一個斷點,然後F5調試應用程序。
接下來可以執行insert操作,這地方會命中斷點的。
insert into `datamip`.`customer`(customerName,email,`desc`) values('mary','123456789@qq.com','vip');
可以看到,斷點命中了,然後進行單步調試,最終你會看到代碼會進入到 C:\2\mysql-5.7.12\storage\innobase\handler\ha_innodb.cc中的 int ha_innobase::write_row 方法,如下圖:
然後找幾個局部變量和調用堆棧看看。。。
這就是我花了一下午的時間總結出的進坑出坑指南,希望能幫助大家節省時間,還是那句話,源碼面前,不談隱私,若還能進行調試,那一切皆為螻蟻!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
作者:
Ram Rai,性能、可擴展性以及軟件架構的愛好者原文鏈接:
https://medium.com/better-programming/debug-your-kubernetes-service-in-5-easy-steps-1457974f024c
在Kubernetes中,服務是一個核心概念。在本文中,將介紹如何調試K8S服務,這些服務是由多個Pod組成的工作負載的抽象接口(主機+端口)。
在我們深入探索debug方法之前,我們先簡單回顧一下網絡,這是Kubernetes服務的基礎。
在一個pod中的容器共享相同的網絡空間和IP。
所有的pod都能通過IP彼此通信。
每個節點都能看到所有的Pod,反之亦然。
Pod可以看到所有的服務。
那麼,在實踐中這些意味着什麼呢?
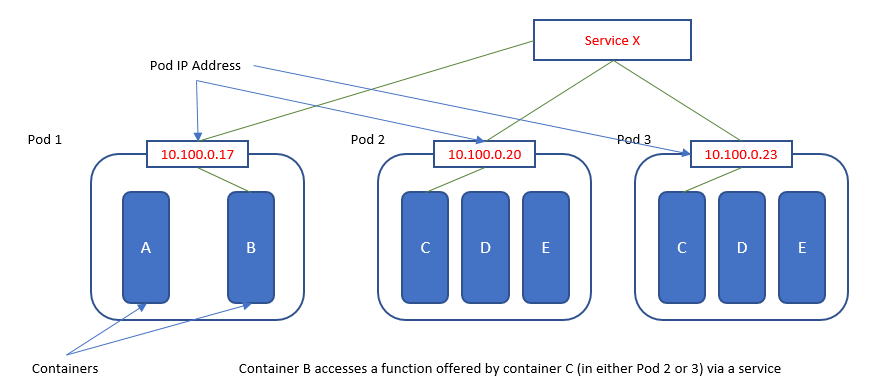
在圖中:
位於Pod1中的容器B可以直接作為localhost尋址容器A
容器B可以通過其IP直接尋址Pod2(kubectl get pod -o wide)。我們知道當pod2出現故障時着不是一個可靠的通信渠道,並且一個新的pod可以出現在其位置中。但是我們無法追逐不斷變化的目標。
接下來,容器B可以通過Service x訪問pod 2和pod 3,後者將它們的IP與負載均衡捆綁在一起;因此,在K8S上支持基於微服務的應用程序起着至關重要的作用
儘管對Kubernetes的內部網絡結構的檢查不在本文的討論範圍內,但我稍後會發布一些參考資料以供大家進一步研究。
對於當下,我還是鼓勵你花費一點時間在實踐中經歷和理解Kubernetes中的網絡。例如,你可以啟動一個Kubernetes測試pod並且嘗試從該pod中訪問其他pod、節點和服務。此處显示的命令將在Pod內彈出一個Linux shell。
kubectl run -it networktest --image=alpine bin/ash --restart=Never --rm
現在你在Kubernetes網絡空間內並且你可以隨意使用wegt、ping、nslookup之類的命令進行實驗。例如,測試你的Kubernetes集群中先前列出的網絡要求,nslookup <servicename>, ping <PodIP>。
現在讓我們回到我們的話題,troubleshooting Kubernetes服務,這實際上是一種網絡結構。
kubectl get svc
如果服務不存在,應該是服務創建出現了故障,因此要去檢查你的服務定義。
請記住,一個內部的Kubernetes ClusterIP服務是無法在集群外部訪問的。因此,有兩種方法可以對其進行測試。方法一,你可以啟動一個測試Pod,通過SSH進入該pod,然後嘗試像這樣訪問你的服務:
kubectl run -it testpod --image=alpine bin/ash --restart=Never --rm
在本文中我們啟動一個alpine Docker鏡像作為pod來從其內部測試服務:
#works for http services
wget <servicename>:<httpport>
#Confirm there is a DNS entry for the service!
nslookup <servicename>
或者,你可以轉發到本地計算機並在本地進行測試。
kubectl port-forward <service_name> 8000:8080
現在,你可以通過localhost:8000訪問服務。
Kubernetes服務會根據標籤selector將入站流量路由到其中一個pod,流量通過其IP路由到目標Pod。所以,請檢查服務是否綁定到那些pod。
kubectl describe service <service-name> | grep Endpoints
執行上述命令之後,你應該看到與列出的工作負載相關的所有Pod的IP。如果沒有看到,請執行Step4。
確保在Kubernetes服務中的selector與pod的標籤相匹配。
kubectl get pods --show-labels
kubectl describe svc <service_name>
從下面的截圖的中可以看到,pod的標籤在右邊。四個pod被標記為app=tinywebsite和tier=frontend,這些標籤與下面“described”的服務selector相匹配。
在這四個匹配的Pod中,只有三個正在運行,其IP在突出显示的行中被列為服務的端點(endpoint)。你還可以在IP列中看到相同的IP。
最後,確保在你的pod中的代碼能夠監聽到你為服務指定的targetPort(例如,你在上方截圖中看到的port8001)!
這十分簡單,為了讓你更進一步深入了解和研究Kubernetes的網絡世界,歡迎你閱讀以下文章。
在Kubernetes中部署一個應用程序
Debug服務
Kubernetes網絡
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
折騰了好長時間才寫這篇文章,順序消費,看上去挺好理解的,就是消費的時候按照隊列中的順序一個一個消費;而併發消費,則是消費者同時從隊列中取消息,同時消費,沒有先後順序。RocketMQ也有這兩種方式的實現,但是在實踐的過程中,就是不能順序消費,好不容易能夠實現順序消費了,發現採用併發消費的方式,消費的結果也是順序的,頓時就蒙圈了,到底怎麼回事?哪裡出了問題?百思不得其解。
經過多次調試,查看資料,debug跟蹤程序,最後終於搞清楚了,但是又不知道怎麼去寫這篇文章,是按部就班的講原理,講如何配置到最後實現,還是按照我的調試過程去寫呢?我覺得還是按照我的調試過程去寫這篇文章吧,因為我的調成過程應該和大多數人的理解思路是一致的,大家也更容易重視。
我們先來回顧一下前面搭建的RocketMQ的環境,這對於我們理解RocketMQ的順序消費是至關重要的。我們的RocketMQ環境是一個兩主兩從的異步集群,其中有兩個broker,broker-a和broker-b,另外,我們創建了兩個Topic,“cluster-topic”,這個Topic我們在創建的時候指定的是集群,也就是說我們發送消息的時候,如果Topic指定為“cluster-topic”,那麼這個消息應該在broker-a和broker-b之間負載;另外創建的一個Topic是“broker-a-topic”,這個Topic我們在創建的時候指定的是broker-a,當我們發送這個Topic的消息時,這個消息只會在broker-a當中,不會出現在broker-b中。
和大家羅嗦了這麼多,大家只要記住,我們的環境中有兩個broker,“broker-a”和“broker-b”,有兩個Topic,“cluster-topic”和“broker-a-topic”就可以了。
我們發送的消息,如果指定Topic為“cluster-topic”,那麼這種消息將在broker-a和broker-b直接負載,這種情況能夠做到順序消費嗎?我們試驗一下,
消費端的代碼如下:
@Bean(name = "pushConsumerOrderly", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer pushConsumerOrderly() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("pushConsumerOrderly");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("cluster-topic","*");
consumer.registerMessageListener((MessageListenerOrderly) (msgs, context) -> {
Random random = new Random();
try {
Thread.sleep(random.nextInt(5) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeOrderlyStatus.SUCCESS;
});
return consumer;
}
生產端我們採用同步發送的方式,代碼如下:
@Test
public void producerTest() throws Exception {
for (int i = 0;i<5;i++) {
Message message = new Message();
message.setTopic("cluster-topic");
message.setKeys("key-"+i);
message.setBody(("this is simpleMQ,my NO is "+i+"---"+new Date()).getBytes());
SendResult sendResult = defaultMQProducer.send(message);
System.out.println("i=" + i);
System.out.println("BrokerName:" + sendResult.getMessageQueue().getBrokerName());
}
}
和前面一樣,我們發送5個消息,並且打印出i的值和broker的名稱,發送消息的順序是0,1,2,3,4,發送完成后,我們觀察一下消費端的日誌,如果順序也是0,1,2,3,4,那麼就是順序消費。我們運行一下,看看結果吧。
生產者的發送日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-b
發送5個消息,其中4個在broker-a,1個在broker-b。再來看看消費端的日誌:
this is simpleMQ,my NO is 3---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 0---Wed Jun 10 13:48:56 CST 2020
順序是亂的?怎麼回事?說明消費者在並不是一個消費完再去消費另一個,而是拉取了一個消息以後,並沒有消費完就去拉取下一個消息了,那這不是併發消費嗎?可是我們程序中設置的是順序消費啊。這裏我們就開始懷疑是broker的問題,難道是因為兩個broker引起的?順序消費只能在一個broker里才能實現嗎?那我們使用broker-a-topic這個試一下吧。
我們把上面的程序稍作修改,只把訂閱的Topic和發送消息時消息的Topic改為broker-a-topic即可。代碼在這裏就不給大家重複寫了,重啟一下程序,發送消息看看日誌吧。
生產者端的日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
我們看到5個消息都發送到了broker-a中,再來看看消費端的日誌,
this is simpleMQ,my NO is 0---Wed Jun 10 14:00:28 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 14:00:29 CST 2020
消費的順序還是亂的,這是怎麼回事?消息都在broker-a中了,為什麼消費時順序還是亂的?程序有問題嗎?review了好幾遍沒有發現問題。
問題卡在這個地方,卡了好長時間,最後在官網的示例中發現,它在發送消息時,使用了一個MessageQueueSelector,我們也實現一下試試吧,改造一下發送端的程序,如下:
SendResult sendResult = defaultMQProducer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
return mqs.get(0);
}
},i);
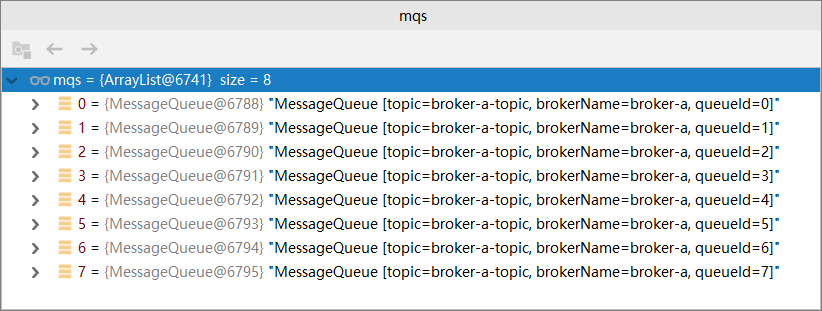
在發送的方法中,我們實現了MessageQueueSelector接口中的select方法,這個方法有3個參數,mq的集合,發送的消息msg,和我們傳入的參數,這個參數就是最後的那個變量i,大家不要漏了。這個select方法需要返回的是MessageQueue,也就是mqs變量中的一個,那麼mqs中有多少個MessageQueue呢?我們猜測是2個,因為我們只有broker-a和broker-b,到底是不是呢?我們打斷點看一下,
MessageQueue有8個,並且brokerName都是broker-a,原來Broker和MessageQueue不是相同的概念,之前我們都理解錯了。我們可以用下面的方式理解,
集群 ——–》 Broker ————》 MessageQueue
一個RocketMQ集群里可以有多個Broker,一個Broker里可以有多個MessageQueue,默認是8個。
那現在對於順序消費,就有了正確的理解了,順序消費是只在一個MessageQueue內,順序消費,我們驗證一下吧,先看看發送端的日誌,
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
5個消息都發送到了broker-a中,通過前面的改造程序,這5個消息應該都是在MessageQueue-0當中,再來看看消費端的日誌,
this is simpleMQ,my NO is 0---Wed Jun 10 14:21:40 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:21:41 CST 2020
這回是順序消費了,每一個消費者都是等前面的消息消費完以後,才去消費下一個消息,這就完全解釋的通了,我們再把消費端改成併發消費看看,如下:
@Bean(name = "pushConsumerOrderly", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer pushConsumerOrderly() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("pushConsumerOrderly");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("broker-a-topic","*");
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
Random random = new Random();
try {
Thread.sleep(random.nextInt(5) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
return consumer;
}
這回使用的是併發消費,我們再看看結果,
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
5個消息都在broker-a中,並且知道它們都在同一個MessageQueue中,再看看消費端,
this is simpleMQ,my NO is 1---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 0---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:28:00 CST 2020
是亂序的,說明消費者是併發的消費這些消息的,即使它們在同一個MessageQueue中。
好了,到這裏終於把順序消費搞明白了,其中的關鍵就是Broker中還有多個MessageQueue,同一個MessageQueue中的消息才能順序消費。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
Java I/O是Java基礎之一,在面試中也比較常見,在這裏我們嘗試通過這篇文章闡述Java I/O的基礎概念,幫助大家更好的理解Java I/O。
在剛開始學習Java I/O時,我很迷惑,因為網上絕大多數的文章都是講解Linux網絡I/O模型的,那時我總是搞不明白和Java I/O的關係。後來查了看了好多,才明白Java I/O的原理是以Linux網絡I/O模型為基礎的,理解了Linux網絡I/O模型再學習Java I/O就很方便了,所以這篇文章,我們先來了解I/O的基本概念,再學習Linux網絡I/O模型,最後再看Java中的幾種I/O。
I/O是Input、Output的縮寫,即對應計算機中的輸入輸出,以一次文件讀取為例,我們需要將磁盤上的數據讀取到用戶空間,那麼這次數據轉移操作其實就是一次I/O操作,更具體的說是一次文件I/O。我們瀏覽網頁,其中在請求一個網頁時,服務器通過網絡把數據發送給我們,此時程序將數據從TCP緩衝區複製到用戶空間,那麼這次數據轉移操作其實也是一次I/O操作,更具體的說是一次網絡I/O。I/O到處都在,十分重要,Java對I/O對底層操作系統的各種I/O模型進行了封裝,使我們可以輕鬆開發。
根據UNIX網絡編程對I/O模型的分類,UNIX提供了5種I/O模型,分別是:阻塞I/O(Blocking I/O)、非阻塞I/O(Non-Blacking I/O)、I/O多路復用模型(I/O Multiplexing)、信號驅動式I/O(Signal Driven I/O)、異步I/O(Asynchronous I/O)。我們逐步了解一下其基本原理。
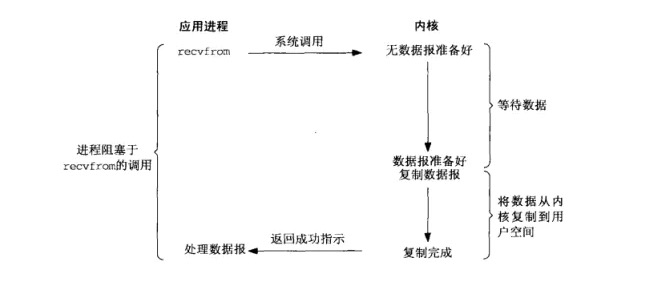
阻塞I/O是最早最基礎的I/O模型,其在讀寫數據過程中會阻塞。通過下圖我們可以看到,當用戶進程調用了recvfrom這個系統調用后,內核開始第一階段的數據準備工作,直到內核等待數據準備完成,然後開始第二階段的將數據從內核複製到用戶空間的工作,最後內核返回結果。整個過程中用戶進程都是阻塞的,直到最後返回結果后才接觸阻塞block狀態。阻塞I/O模型適用於併發量小且對時延不敏感的系統。
當用戶進程調用recvfrom這個系統調用后,如果內核尚未準備好數據,此時不再阻塞用戶進程,而是立即返回一個EWOULDBLOCK錯誤。用戶進程會不斷髮起系統調用直到內核中數據被準備好(輪詢),此時將執行第二階段的將數據從內核複製到用戶空間的工作,然後內核返回結果。非阻塞I/O模型不斷地輪詢往往需要耗費大量cpu時間。
I/O多路復用的優點在於單個進程可以同時處理多個網絡連接的I/O,其基本原理就是select/epoll函數可以不斷的輪詢其負責的所有socket,當某個socket有數據到達時,就通知用戶進程。
如下圖所示,當用戶進程調用select函數時,整個進程會被阻塞block住,但是這裏的阻塞不是被socket I/O阻塞,而是被select這個函數阻塞。同時內核會監聽改select負責的所有socket(這裏的socket一般設置為non-blocking),當任何一個socket中的數據準備好時,select就會返回給用戶進程,這時候用戶進程再此發起一個系統調用,將數據從內核複製到用戶空間,並返回結果。
對比I/O多路復用模型和阻塞I/O模型的流程,多路復用多了一個系統調用來完成select環節,除此之外沒有太大的不同。Select的優勢在於它可以同時處理多個connection,但是會多一個系統調用。多路復用本質上也不是非阻塞的。
首先我們開啟socket的信號驅動I/O功能,然後用戶進程發起sigaction系統調用給內核后立即返回並可繼續處理其他工作。收到sigaction系統調用的內核在將數據準備好後會按照要求產生一個signo信號通知給用戶進程。然後用戶進程再發起recvfrom系統調用,完成數據從內核到用戶空間的複製,並返回最終結果。其基礎原理圖示如下:
用戶進程向內核發起系統調用后,就可以開始去做其他事情了。內核收到異步I/O的系統調用后,會直接retrun,所以這裏不會對用戶進程有阻塞。之後內核等待數據準備完成後會繼續將數據從內核拷貝到用戶空間(具體動作可以由異步I/O調用定義),然後內核回給用戶進程發送一個signal,告訴用戶進程I/O操作完成了,整個過程不會導致用戶請求進程阻塞。
信號驅動I/O模型是內核通知我們可以發起I/O操作了,而異步I/O模式是內核告訴我們I/O操作已經完成了。
以上就是Linux的5種網絡I/O模型,其中前4中都是同步I/O模型,他們真正的I/O操作環節都會將進程阻塞,只有最後一種異步I/O模型是異步I/O操作。
在JDK1.4之前,基於Java的所有socket通信都是使用阻塞I/O(BIO),JDK1.4提供了了非阻塞I/O(NIO)功能,不過雖然名字叫做NIO,實際底層模型是I/O多路復用,JDK1.7提供了針對異步I/O(AIO)功能。
BIO簡化了上層開發,但是性能瓶頸問題嚴重,對高併發第時延支持差。
基於消息隊列和線程池技術優化的BIO模式雖然可以對高併發支持有一定幫助,但是還是受限於線程池大小和線程池阻塞隊列大小的制約,當併發數超過線程池的處理能力時,部分請求法務繼續處理,會導致客戶端連接超時,影響用戶體驗。
NIO彌補了BIO的不足,簡單說就是通過selector不斷輪詢註冊在自己上面的channel,如果channel上面有新的連接讀寫時間時就會被輪詢出來,一個selector上面可以註冊多個channel,一個線程就可以負責selector的輪詢,這樣就可以支持成千上萬的連接。Selector就是一個輪詢器,channel是一個通道,通過它來讀取或者寫入數據,通道是雙向的,可以用於讀、寫、讀和寫。Buffer用來和channel交互,數據通過channel進出buffer。
NIO的優點是可以可靠性好以及高併發低時延,但是使用NIO的代碼開發較為複雜。
AIO,或者說叫做NIO2.0,引入了異步channel的概念,提供了異步文件channel和異步socket channel的實現,開發者可以通過Future類來表示異步操作的結果,也可以在執行異步操作時傳入一個channels,實現CompletionHandler接口作為回調。AIO不用開發者單獨開發獨立線程的selector,異步回調操作有JDK地城思安城池負責驅動,開發起來比NIO簡單一些,同時保持了高可靠高併發低時延的優點。
參考:
https://blog.csdn.net/historyasamirror/article/details/5778378
https://juejin.im/post/5cce5019e51d453a506b0ebf
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
上個月,我寫了兩篇微服務的文章:《.Net微服務實戰之技術架構分層篇》與《.Net微服務實戰之技術選型篇》,微服務系列原有三篇,當我憋第三篇的內容時候一直沒有靈感,因此先打算放一放。
本篇文章與源碼原本打算實在去年的時候完成併發布的,然而我一直忙於公司項目的微服務的實施,所以該篇文章一拖再拖。如今我花了點時間整理了下代碼,並以此篇文章描述整個實現思路,並開放了源碼給予需要的人一些參考。
源碼:https://github.com/SkyChenSky/Sikiro.RBAC
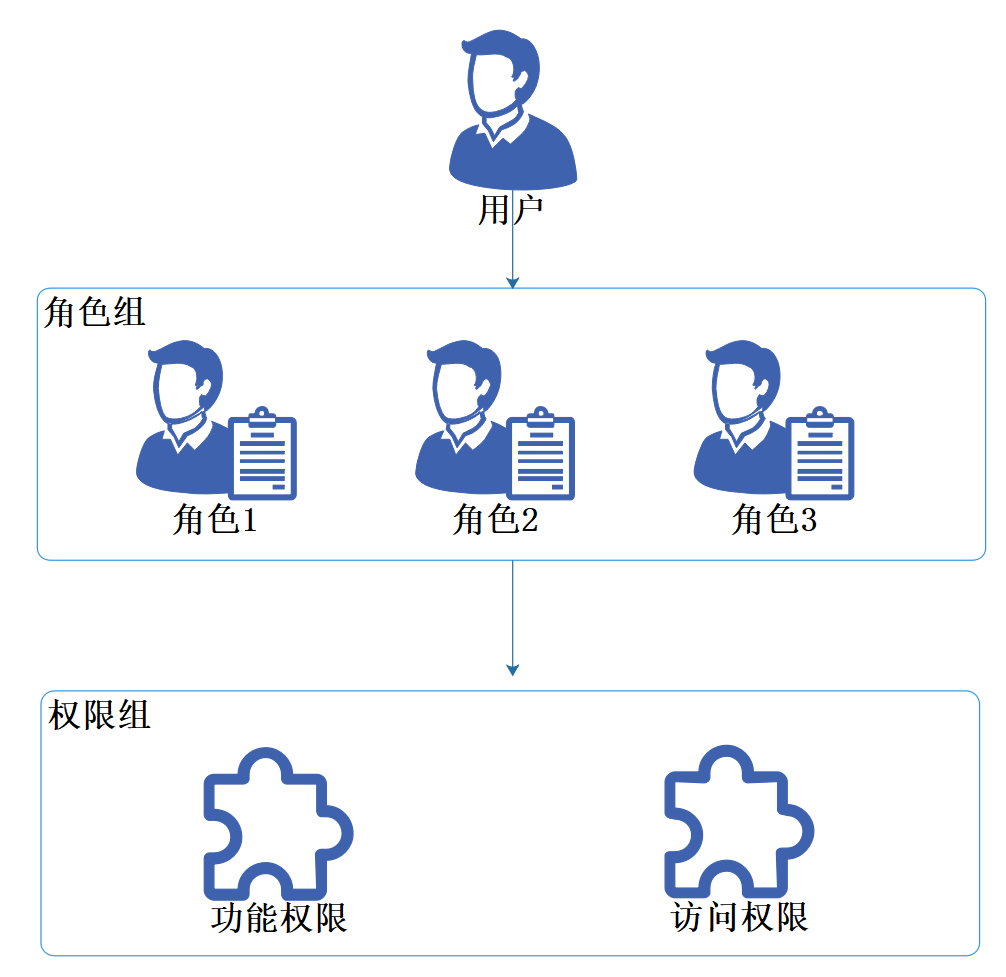
Role-Based Access Contro翻譯成中文就是基於角色的訪問控制,文章以下我都用他的簡稱RBAC來描述。
現信息系統的權限控制大多數採取RBAC的思想進行實現,其本質思想是對系統各種的操作權限不是直接授予具體的某個用戶,而是在用戶集合與權限集合之間建立一個角色,作為間接關聯。每一種角色對應一組相應的權限。一旦用戶被分配了適當的角色后,該用戶就擁有此角色的所有操作權限。
通過以上的描述,我們可以分析出以下信息:
這樣做的好處在於,不必在每次創建用戶時都進行分配權限的操作,只要分配用戶相應的角色即可,而且角色的權限變更比用戶的權限變更要少得多,這樣將簡化用戶的權限管理,減少系統的開銷。
從權限的作用可以分為三種,功能權限、訪問權限、數據權限:
數據權限的實現可大可小,大可大到對條件進行動態配置,小可小到只針對某個維度進行硬編碼。不納入這次的討論範圍。
時效性,直接影響到安全性,既然是權限控制,那麼理應一修改權限后就立刻生效。曾經有同行問過我,是不是每一個請求都得去查一次數據庫是否滿足權限,如果是,數據庫壓力豈不是很大?
安全性,每一個頁面跳轉,每一個讀寫請求都的進行一次權限驗證,不滿足的權限的功能按鈕就不需要渲染,避免樣式display:none的情況。
開發效率,權限控制理應是框架層面的,因此盡可能作為非業務的侵入性,讓開發人員保持原有的數據善增改查與頁面渲染。
學習門檻極低,開箱即用。其外在極簡,卻又不失飽滿的內在,體積輕盈,組件豐盈,從核心代碼到 API 的每一處細節都經過精心雕琢,非常適合界面的快速開發,它更多是為服務端程序員量身定做,無需涉足各種前端工具的複雜配置,只需面對瀏覽器本身,讓一切你所需要的元素與交互,從這裏信手拈來。作為國人的開源項目,完整的接口文檔與Demo示例讓入門者非常友好的上手,開箱即用的Api讓學習成本盡可能的低,其易用性成為快速開發框架的基礎。
主要兩大優勢,無模式與橫向擴展。對於權限模塊來說,無需SQL來寫複雜查詢和報表,也不需要使用到多表的強事務,上面提到的時效性的數據庫壓力問題也可以通過分片解決。無模式使得開發人員無需預定義存儲結構,結合MongoDB官方提供的驅動可以做到快速的開發。
一個管理員可以擁有多個角色,因此管理員與角色是一對多的關聯;角色作為權限組的存在,又可以選擇多個功能權限值與菜單,所以角色與菜單、功能權限值也是一對多的關係。
Deparment與Position屬於非核心,可以按照自己的實際業務進行擴展。
隨着業務發展,需求功能是千奇百怪的,根本無法抽象出來,那麼功能按鈕就要隨着業務進行定義。在我的項目里使用了枚舉值進行定義每個功能權限,通過自定義的PermissionAttribute與響應的action進行綁定,在系統啟動時,通過反射把功能權限的枚舉值與相應的controller、action映射到MenuAction表,枚舉值對應code字段,controller與action拼接后對應url字段。
已初始化到數據庫的權限值可以到菜單頁把相對應的菜單與權限通過用戶界面關聯起來。
1 [HttpPost] 2 [Permission(PermCode.Administrator_Edit)] 3 public IActionResult Edit(EditModel edit) 4 { 5 //do something 6 7 return Json(result); 8 }
1 /// <summary> 2 /// 功能權限 3 /// </summary> 4 public static class PermissionUtil 5 { 6 public static readonly Dictionary<string, IEnumerable<int>> PermissionUrls = new Dictionary<string, IEnumerable<int>>(); 7 private static MongoRepository _mongoRepository; 8 9 /// <summary> 10 /// 判斷權限值是否被重複使用 11 /// </summary> 12 public static void ValidPermissions() 13 { 14 var codes = Enum.GetValues(typeof(PermCode)).Cast<int>(); 15 var dic = new Dictionary<int, int>(); 16 foreach (var code in codes) 17 { 18 if (!dic.ContainsKey(code)) 19 dic.Add(code, 1); 20 else 21 throw new Exception($"權限值 {code} 被重複使用,請檢查 PermCode 的定義"); 22 } 23 } 24 25 /// <summary> 26 /// 初始化添加預定義權限值 27 /// </summary> 28 /// <param name="app"></param> 29 public static void InitPermission(IApplicationBuilder app) 30 { 31 //驗證權限值是否重複 32 ValidPermissions(); 33 34 //反射被標記的Controller和Action 35 _mongoRepository = (MongoRepository)app.ApplicationServices.GetService(typeof(MongoRepository)); 36 37 var permList = new List<MenuAction>(); 38 var actions = typeof(PermissionUtil).Assembly.GetTypes() 39 .Where(t => typeof(Controller).IsAssignableFrom(t) && !t.IsAbstract) 40 .SelectMany(t => t.GetMethods(BindingFlags.Instance | BindingFlags.Public | BindingFlags.DeclaredOnly)); 41 42 //遍歷集合整理信息 43 foreach (var action in actions) 44 { 45 var permissionAttribute = 46 action.GetCustomAttributes(typeof(PermissionAttribute), false).ToList(); 47 if (!permissionAttribute.Any()) 48 continue; 49 50 var codes = permissionAttribute.Select(a => ((PermissionAttribute)a).Code).ToArray(); 51 var controllerName = action?.ReflectedType?.Name.Replace("Controller", "").ToLower(); 52 var actionName = action.Name.ToLower(); 53 54 foreach (var item in codes) 55 { 56 if (permList.Exists(c => c.Code == item)) 57 { 58 var menuAction = permList.FirstOrDefault(a => a.Code == item); 59 menuAction?.Url.Add($"{controllerName}/{actionName}".ToLower()); 60 } 61 else 62 { 63 var perm = new MenuAction 64 { 65 Id = item.ToString().EncodeMd5String().ToObjectId(), 66 CreateDateTime = DateTime.Now, 67 Url = new List<string> { $"{controllerName}/{actionName}".ToLower() }, 68 Code = item, 69 Name = ((PermCode)item).GetDisplayName() ?? ((PermCode)item).ToString() 70 }; 71 permList.Add(perm); 72 } 73 } 74 PermissionUrls.TryAdd($"{controllerName}/{actionName}".ToLower(), codes); 75 } 76 77 //業務功能持久化 78 _mongoRepository.Delete<MenuAction>(a => true); 79 _mongoRepository.BatchAdd(permList); 80 } 81 82 /// <summary> 83 /// 獲取當前路徑 84 /// </summary> 85 /// <param name="filterContext"></param> 86 /// <returns></returns> 87 public static string CurrentUrl(HttpContext filterContext) 88 { 89 var url = filterContext.Request.Path.ToString().ToLower().Trim('/'); 90 return url; 91 } 92 }
當所有權限關係關聯上后,用戶訪問系統時,需要對其所有操作進行攔截與實時的權限判斷,我們註冊一個全局的GlobalAuthorizeAttribute,其主要攔截所有已經標識PermissionAttribute的action,查詢該用戶所關聯所有角色的權限是否滿足允許通過。
我的實現有個細節,給判斷用戶IsSuper==true,也就是超級管理員,如果是超級管理員則繞過所有判斷,可能有人會問為什麼不在角色添加一個名叫超級管理員進行判斷,因為名稱是不可控的,在代碼邏輯里並不知道用戶起的所謂的超級管理員,就是我們需要繞過驗證的超級管理員,假如他叫無敵管理員呢?
1 /// <summary> 2 /// 全局的訪問權限控制 3 /// </summary> 4 public class GlobalAuthorizeAttribute : System.Attribute, IAuthorizationFilter 5 { 6 #region 初始化 7 private string _currentUrl; 8 private string _unauthorizedMessage; 9 private readonly List<string> _noCheckPage = new List<string> { "home/index", "home/indexpage", "/" }; 10 11 private readonly AdministratorService _administratorService; 12 private readonly MenuService _menuService; 13 14 public GlobalAuthorizeAttribute(AdministratorService administratorService, MenuService menuService) 15 { 16 _administratorService = administratorService; 17 _menuService = menuService; 18 } 19 #endregion 20 21 public void OnAuthorization(AuthorizationFilterContext context) 22 { 23 context.ThrowIfNull(); 24 25 _currentUrl = PermissionUtil.CurrentUrl(context.HttpContext); 26 27 //不需要驗證登錄的直接跳過 28 if (context.Filters.Count(a => a is AllowAnonymousFilter) > 0) 29 return; 30 31 var user = GetCurrentUser(context); 32 if (user == null) 33 { 34 if (_noCheckPage.Contains(_currentUrl)) 35 return; 36 37 _unauthorizedMessage = "登錄失效"; 38 39 if (context.HttpContext.Request.IsAjax()) 40 NoUserResult(context); 41 else 42 LogoutResult(context); 43 return; 44 } 45 46 //超級管理員跳過 47 if (user.IsSuper) 48 return; 49 50 //賬號狀態判斷 51 var administrator = _administratorService.GetById(user.UserId); 52 if (administrator != null && administrator.Status != EAdministratorStatus.Normal) 53 { 54 if (_noCheckPage.Contains(_currentUrl)) 55 return; 56 57 _unauthorizedMessage = "親~您的賬號已被停用,如有需要請您聯繫系統管理員"; 58 59 if (context.HttpContext.Request.IsAjax()) 60 AjaxResult(context); 61 else 62 AuthResult(context, 403, GoErrorPage(true)); 63 64 return; 65 } 66 67 if (_noCheckPage.Contains(_currentUrl)) 68 return; 69 70 var userUrl = _administratorService.GetUserCanPassUrl(user.UserId); 71 72 // 判斷菜單訪問權限與菜單訪問權限 73 if (IsMenuPass(userUrl) && IsActionPass(userUrl)) 74 return; 75 76 if (context.HttpContext.Request.IsAjax()) 77 AuthResult(context, 200, GetJsonResult()); 78 else 79 AuthResult(context, 403, GoErrorPage()); 80 } 81 }
在權限驗證通過後,返回view之前,還是利用了Filter進行一個實時的權限查詢,主要把該用戶所擁有功能權限值查詢出來通過ViewData[“PermCodes”]傳到頁面,然後通過razor進行按鈕的渲染判斷。
然而我在項目中封裝了大部分常用的LayUI控件,主要利用.Net Core的TagHelper進行了封裝,TagHelper內部與ViewData[“PermCodes”]進行判斷是否輸出HTML。
1 /// <summary> 2 /// 全局用戶權限值查詢 3 /// </summary> 4 public class GobalPermCodeAttribute : IActionFilter 5 { 6 private readonly AdministratorService _administratorService; 7 8 public GobalPermCodeAttribute(AdministratorService administratorService) 9 { 10 _administratorService = administratorService; 11 } 12 13 private static AdministratorData GetCurrentUser(HttpContext context) 14 { 15 return context.User.Claims.FirstOrDefault(c => c.Type == ClaimTypes.UserData)?.Value.FromJson<AdministratorData>(); 16 } 17 18 19 public void OnActionExecuting(ActionExecutingContext context) 20 { 21 ((Controller)context.Controller).ViewData["PermCodes"] = new List<int>(); 22 23 if (context.HttpContext.Request.IsAjax()) 24 return; 25 26 var user = GetCurrentUser(context.HttpContext); 27 if (user == null) 28 return; 29 30 if (user.IsSuper) 31 return; 32 33 ((Controller)context.Controller).ViewData["PermCodes"] = _administratorService.GetActionCode(user.UserId).ToList(); 34 } 35 36 public void OnActionExecuted(ActionExecutedContext context) 37 { 38 } 39 }
1 [HtmlTargetElement("LayuiButton")] 2 public class LayuiButtonTag : TagHelper 3 { 4 #region 初始化 5 private const string PermCodeAttributeName = "PermCode"; 6 private const string ClasstAttributeName = "class"; 7 private const string LayEventAttributeName = "lay-event"; 8 private const string LaySubmitAttributeName = "LaySubmit"; 9 private const string LayIdAttributeName = "id"; 10 private const string StyleAttributeName = "style"; 11 12 [HtmlAttributeName(StyleAttributeName)] 13 public string Style { get; set; } 14 15 [HtmlAttributeName(LayIdAttributeName)] 16 public string Id { get; set; } 17 18 [HtmlAttributeName(LaySubmitAttributeName)] 19 public string LaySubmit { get; set; } 20 21 [HtmlAttributeName(LayEventAttributeName)] 22 public string LayEvent { get; set; } 23 24 [HtmlAttributeName(ClasstAttributeName)] 25 public string Class { get; set; } 26 27 [HtmlAttributeName(PermCodeAttributeName)] 28 public int PermCode { get; set; } 29 30 [HtmlAttributeNotBound] 31 [ViewContext] 32 public ViewContext ViewContext { get; set; } 33 34 #endregion 35 public override async void Process(TagHelperContext context, TagHelperOutput output) 36 { 37 context.ThrowIfNull(); 38 output.ThrowIfNull(); 39 40 var administrator = ViewContext.HttpContext.GetCurrentUser(); 41 if (administrator == null) 42 return; 43 44 var childContent = await output.GetChildContentAsync(); 45 46 if (((List<int>)ViewContext.ViewData["PermCodes"]).Contains(PermCode) || administrator.IsSuper) 47 { 48 foreach (var item in context.AllAttributes) 49 { 50 output.Attributes.Add(item.Name, item.Value); 51 } 52 53 output.TagName = "a"; 54 output.TagMode = TagMode.StartTagAndEndTag; 55 output.Content.SetHtmlContent(childContent.GetContent()); 56 } 57 else 58 { 59 output.TagName = ""; 60 output.TagMode = TagMode.StartTagAndEndTag; 61 output.Content.SetHtmlContent(""); 62 } 63 } 64 }
以上就是我本篇分享的內容,項目是以單體應用提供的,方案思路也適用於前後端分離。最後附上幾個系統效果圖
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
今天我們繼續來分析用友系列的第二個產品–U8Cloud2.5 ,apilink方式的API.官網的API文檔地址如下:U8API文檔 因為我們主要是憑證對接,所以使用到的模塊有總賬、基礎檔案這兩個模塊。
Ps:2.5的財務系統如果不是最新補丁的話,要記得打補丁,不然後續的科目接口會有問題。
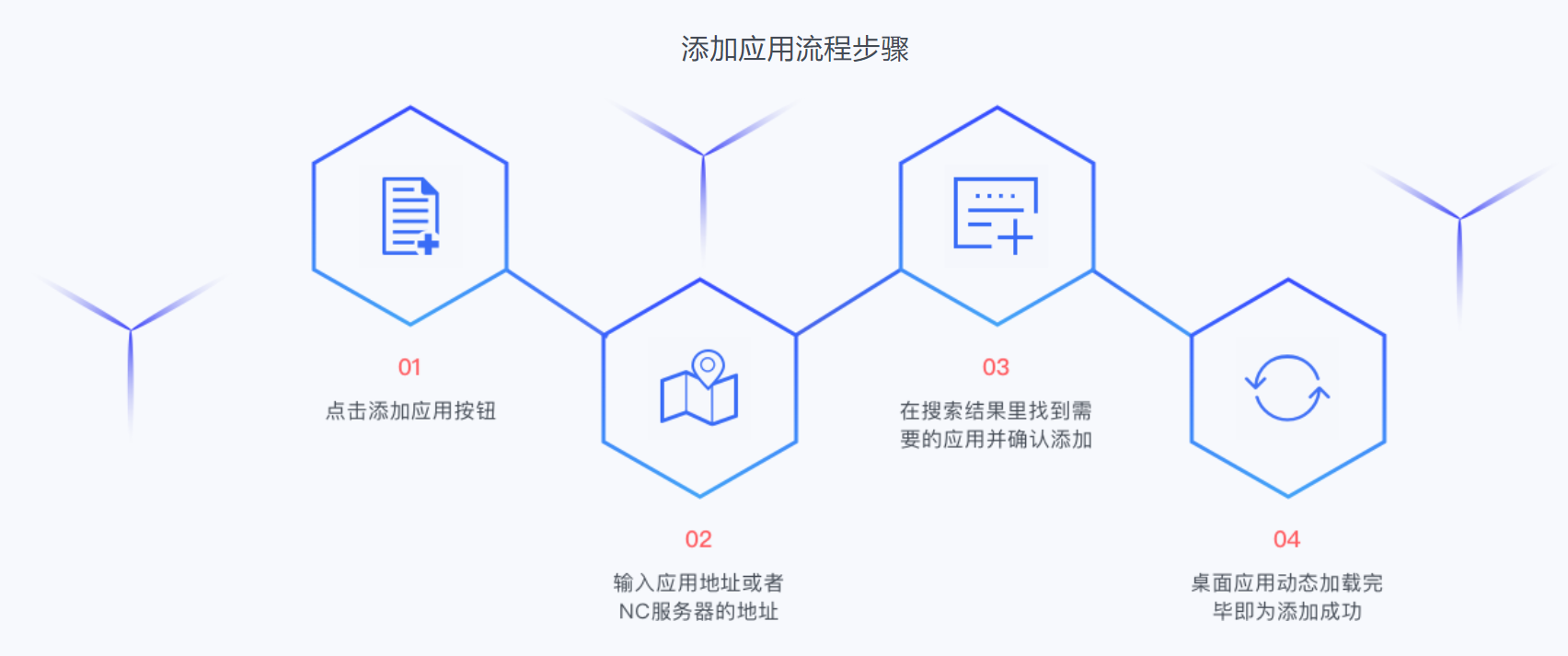
如果我們對接的財務系統是公有雲的U8C的話,你會得到一個遠程的財務系統的地址,接着使用UClient工具,即 通過集成友戶通,為企業應用提供了統一的單點登陸支持,支持CA登陸、短信登陸、用戶名/密碼登陸,支持企業用戶系統與友戶通進行綁定,實現統一的用戶登陸服務 的這麼一個工具。
具體的添加應用的步驟為
首先,我們必須要在網站內註冊賬號,API集市上有各個接口的詳細說明,我們需要獲取一個apicode參數,每個API模塊在點擊購買后系統會自動分配該模塊的apicode,所以這也就是我們需要兩個不同的apicode.
基本上U8cloud2.5的版本接口,需要涉及到的請求參數就是這個了,接着我們就可以愉快的進行開發工作了。
如圖,固定的全局請求頭參數有以下幾個:
1.authoration–驗證方式;默認是apicode
2.apicode—模塊的apicode.也就是我們上文中購買模塊后得到的參數.
3.system—系統類型. 1—測試. 2—正式.
4.trantype–翻譯類型; 默認為code.即採用編碼模式.
基礎檔案,我們主要使用到的API接口有科目查詢.
會計主體賬簿編碼–我們可以從財務系統里獲取,具體的獲取方式如下
打開U8Client,使用正確的用戶名和密碼登錄財務系統.在企業建模平台–》基礎檔案–》組織機構–》會計主體 一欄,可以看到我們使用的會計主體賬簿編碼.如我們要使用的就是40001-9999
其中40001為公司編碼,9999為會計方案.可以看到是採用分頁形式來訪問的,所以如果我們要一次性獲取到所有的會計科目,可以採用以下方法。
public AccountQueryResponse QueryAccount(string pk_subjscheme, string pageIndex, string glorgBookCode)
{
var request = new AccountQueryRequest();
var pms = new Dictionary<string, object>();
pms.Add("pk_subjscheme", pk_subjscheme);
pms.Add("glorgbookcode", glorgBookCode);
pms.Add("page_now", pageIndex);
pms.Add("page_size", "100");
request.SetPostParameters(pms);
return _Client.Excute(request);
}
public List<U8AccountResult> GetAccountQueryResult(string pk_subjscheme, string pageIndex, string glorgBookCode)
{
var list = new List<U8AccountResult>();
var response = QueryAccount(pk_subjscheme, pageIndex, glorgBookCode);
if (response != null && response.status == "success" && response.data != null)
{
var result = JsonConvert.DeserializeObject<AccountQueryResult>(response.data);
list = result.datas == null ? new List<U8AccountResult>() : result.datas.ToList().Select(x => new U8AccountResult
{
balanorient = x.accsubjParentVO.balanorient,
subjcode = x.accsubjParentVO.subjcode,
subjname = x.accsubjParentVO.subjname,
dispname = x.accsubjParentVO.dispname,
remcode = x.accsubjParentVO.remcode,
subjId = x.accsubjParentVO.pk_accsubj,
endflag = x.accsubjParentVO.endflag,
subjectAssInfos = x.subjass == null ? new List<AccSubjectAssInfo>() : x.subjass.ToList().Select(t => new AccSubjectAssInfo
{
bdcode = t.bdcode,
bddispname = t.bddispname,
bdname = t.bdname
}).ToList()
}).ToList();
}
return list;
}
///獲取所有的會計科目
public List<U8AccountResult> GetAllAccount(string pk_subjescheme, string glorgBookCode)
{
var pageNo = "1";
var list = new List<U8AccountResult>();
var response = QueryAccount(pk_subjescheme, pageNo, glorgBookCode);
if (response != null && response.status == "success" && response.data != null)
{
var result = JsonConvert.DeserializeObject<AccountQueryResult>(response.data);
var allCount = Math.Ceiling(Convert.ToDouble(result.allcount) / result.retcount);
if (allCount >= 1)
{
for (int i = 1; i <= allCount; i++)
{
var resultList = GetAccountQueryResult(pk_subjescheme, i.ToString(), glorgBookCode);
list.AddRange(resultList);
}
}
}
return list;
}
allCount為總條數,retCount為當次請求的分頁條數,默認最大值為100,即接口每次只能返回100條數據,超過100條的數據量,我們就要採用分頁的形式來獲取了。
這裏,有兩個隱藏的坑需要注意一下
1.如果沒有打過類似“patch_會計科目查詢api查詢條件增加會計主體賬簿編碼”這樣的補丁,我們無法傳入會計主體賬簿編碼,就默認返回該集團下所有公司的會計科目,這樣顯然達不到我們的目的。
2.返回的會計科目中沒有輔助核算明細,這對於我們傳輸憑證也是有影響的。所以這兩個補丁,如果我們在對接的過程中發現有接口有問題,那麼就要聯繫總部的老師幫忙打相應的補丁了.
總賬模塊,主要是我們的憑證傳輸了.
我們先來看憑證的保存,憑證保存要傳入相應的憑證json串.
public GL_VoucherInsertResponse InsertVoucher(List<object> models)
{
var request = new GL_VoucherInsertRequest();
var pms = new Dictionary<string, object>();
pms.Add("voucher", models);
request.SetPostParameters(pms);
return _Client.Excute(request);
}
///憑證新增結果
public List<U8GLVoucherResult> GetVoucherInsertResult(List<object> models)
{
var list = new List<U8GLVoucherResult>();
var response = InsertVoucher(models);
if (response != null && response.status == "success")
{
if (response.data != null && !response.data.IsNullOrEmpty())
{
var result = JsonConvert.DeserializeObject<List<VoucherResult>>(response.data);
list = result.Select(x => new U8GLVoucherResult
{
explanation = x.explanation,
glorgbook_code = x.glorgbook_code,
glorgbook_name = x.glorgbook_name,
no = x.no,
pk_glorgbook = x.pk_glorgbook,
pk_voucher = x.pk_voucher,
totalcredit = x.totalcredit,
totaldebit = x.totaldebit,
pk_vouchertype = x.pk_vouchertype,
vouchertype_code = x.vouchertype_code,
vouchertype_name = x.vouchertype_name,
prepareddate = Convert.ToDateTime(x.prepareddate),
errorMsg = ""
}).ToList();
}
}
else
{
list.Add(new U8GLVoucherResult { errorMsg = response.errormsg });
}
return list;
}
借貸方,憑證字主要用於我們新增后回執進行憑證記錄的.
接着我們來看憑證保存的實體類.
public class U8VoucherModel
{
/// <summary>
/// 是否差異憑證
/// </summary>
public bool ISDIFFLAG { get; set; }
/// <summary>
/// 附單據數
/// </summary>
public string attachment { get; set; }
public Detail[] details { get; set; }
/// <summary>
/// 憑證摘要
/// </summary>
public string explanation { get; set; }
/// <summary>
/// 憑證號
/// </summary>
public string no { get; set; }
/// <summary>
/// 公司
/// </summary>
public string pk_corp { get; set; }
/// <summary>
/// 賬簿
/// </summary>
public string pk_glorgbook { get; set; }
/// <summary>
/// 制單人編碼
/// </summary>
public string pk_prepared { get; set; }
/// <summary>
/// 憑證類別簡稱
/// </summary>
public string pk_vouchertype { get; set; }
/// <summary>
/// 制單日期
/// </summary>
public string prepareddate { get; set; }
/// <summary>
/// 憑證類型
/// </summary>
public int voucherkind { get; set; }
}
public class Detail
{
/// <summary>
/// 原幣貸方金額
/// </summary>
public string creditamount { get; set; }
/// <summary>
/// 貸方數量
/// </summary>
public string creditquantity { get; set; }
/// <summary>
/// 原幣借方金額
/// </summary>
public string debitamount { get; set; }
/// <summary>
/// 借方數量
/// </summary>
public string debitquantity { get; set; }
/// <summary>
/// 分錄號
/// </summary>
public string detailindex { get; set; }
/// <summary>
/// 匯率
/// </summary>
public string excrate1 { get; set; }
/// <summary>
/// 摘要
/// </summary>
public string explanation { get; set; }
/// <summary>
/// 本幣貸方金額
/// </summary>
public string localcreditamount { get; set; }
/// <summary>
/// 本幣借方金額
/// </summary>
public string localdebitamount { get; set; }
/// <summary>
/// 科目
/// </summary>
public string pk_accsubj { get; set; }
/// <summary>
/// 幣別編碼
/// </summary>
public string pk_currtype { get; set; }
/// <summary>
/// 單價
/// </summary>
public string price { get; set; }
public Ass[] ass { get; set; }
public Cashflow[] cashflow { get; set; }
}
public class Ass
{
/// <summary>
/// 輔助核算類型編碼
/// </summary>
public string checktypecode { get; set; }
/// <summary>
/// 輔助核算值編碼
/// </summary>
public string checkvaluecode { get; set; }
}
public class Cashflow
{
public string cashflow_code { get; set; }
public string currtype_code { get; set; }
public int money { get; set; }
}
整個憑證對接下來,其實坑不是很多,主要在於前期接口文檔的研究,參數的獲取以及測試接口連通性上面.
希望文章能在你開發API接口對接的路上一些幫助和解疑,也希望同樣做API對接的小夥伴,我們可以多多交流。祝你在開發的道路上勇往直前。
我是程序猿貝塔,一個分享自己對接過財務系統API經歷和生活感悟的程序員。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
本文收錄在個人博客:www.chengxy-nds.top,技術資源共享,一起進步
最近公司貌似融到資了!開始發了瘋似的找渠道推廣,現在終於明白為啥前一段大肆的招人了,原來是在下一盤大棋,對員工總的來看是個好事,或許是時候該跟boss提一提漲工資的話題了。
不過,漲工資還沒下文,隨之而來的卻是一車一車的需求,每天都有新渠道接入,而且每個渠道都要提供個性化支持,開發量陡增。最近都沒什麼時間更文,準點下班都成奢望了!
由於推廣渠道的激增,而每一個下單來源在下單時都做特殊的邏輯處理,可能每两天就會加一個來源,已經把之前的下單邏輯改的面目全。出於長遠的考慮,我決定對現有的邏輯進行重構,畢竟長痛不如短痛。
我們看下邊的偽代碼,大致就是重構前下單邏輯的代碼,由於來源比較少,簡單的做if-else邏輯判斷足以滿足需求。
現在每種訂單來源的處理邏輯都有幾百行代碼,看着已經比較臃腫,可我愣是遲遲沒動手重構,一方面業務方總像催命鬼一樣的讓你趕工期,想快速實現需求,這樣寫是最快;另一方面是不敢動,面對古董級代碼,還是想求個安穩。
但這次來源一下子增加幾十個,再用這種方式做已經無法維護了,想象一下那種臃腫的if-else代碼,別說開發想想都頭大!
public class OrderServiceImpl implements IOrderService {
@Override
public String handle(OrderDTO dto) {
String type = dto.getType();
if ("1".equals(type)) {
return "處理普通訂單";
} else if ("2".equals(type)) {
return "處理團購訂單";
} else if ("3".equals(type)) {
return "處理促銷訂單";
}
return null;
}
}
思來想去基於當前業務場景重構,還是用策略模式比較合適,它是oop中比較著名的設計模式之一,對方法行為的抽象。
策略模式定義了一個擁有共同行為的算法族,每個算法都被封裝起來,可以互相替換,獨立於客戶端而變化。
if-else 或者 switch-case 來選擇具體子類時。這個是用策略模式修改後代碼:
@Component
@OrderHandlerType(16)
public class DispatchModeProcessor extends AbstractHandler{
@Autowired
private OrderStencilledService orderStencilledService;
@Override
public void handle(OrderBO orderBO) {
/**
* 訂單完結廣播通知(1 - 支付完成)
*/
orderStencilledService.dispatchModeFanout(orderBO);
/**
* SCMS 出庫單
*/
orderStencilledService.createScmsDeliveryOrder(orderBO.getPayOrderInfoBO().getLocalOrderNo());
}
}
每個訂單來源都有自己單獨的邏輯實現類,而每次需要添加訂單來源,直接新建實現類,修改@OrderHandlerType(16)的數值即可,再也不用去翻又臭又長的if-lese。
不僅如此在分配任務時,每個人負責開發幾種訂單來源邏輯,都可以做到互不干擾,而且很大程度上減少了合併代碼的衝突。
定義一個標識訂單來源的註解@OrderHandlerType
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface OrderHandlerType {
int value() default 0;
}
向上抽象出來一個具體的業務處理器
public abstract class AbstractHandler {
abstract public void handle(OrderBO orderBO);
}
handler 入口@Component
@SuppressWarnings({"unused","rawtypes"})
public class HandlerProcessor implements BeanFactoryPostProcessor {
private String basePackage = "com.ecej.order.pipeline.processor";
public static final Logger log = LoggerFactory.getLogger(HandlerProcessor.class);
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
Map<Integer,Class> map = new HashMap<Integer,Class>();
ClassScaner.scan(basePackage, OrderHandlerType.class).forEach(x ->{
int type = x.getAnnotation(OrderHandlerType.class).value();
map.put(type,x);
});
beanFactory.registerSingleton(OrderHandlerType.class.getName(), map);
log.info("處理器初始化{}", JSONObject.toJSONString(beanFactory.getBean(OrderHandlerType.class.getName())));
}
}
public class ClassScaner {
private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
private final List<TypeFilter> includeFilters = new ArrayList<TypeFilter>();
private final List<TypeFilter> excludeFilters = new ArrayList<TypeFilter>();
private MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory(resourcePatternResolver);
/**
* 添加包含的Fiter
* @param includeFilter
*/
public void addIncludeFilter(TypeFilter includeFilter) {
this.includeFilters.add(includeFilter);
}
/**
* 添加排除的Fiter
* @param includeFilter
*/
public void addExcludeFilter(TypeFilter excludeFilter) {
this.excludeFilters.add(excludeFilter);
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackage 包名
* @param targetTypes 需要指定的目標類型,可以是pojo,可以是註解
* @return Set<Class<?>>
*/
public static Set<Class<?>> scan(String basePackage,
Class<?>... targetTypes) {
ClassScaner cs = new ClassScaner();
for (Class<?> targetType : targetTypes){
if(TypeUtils.isAssignable(Annotation.class, targetType)){
cs.addIncludeFilter(new AnnotationTypeFilter((Class<? extends Annotation>) targetType));
}else{
cs.addIncludeFilter(new AssignableTypeFilter(targetType));
}
}
return cs.doScan(basePackage);
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackages 包名,多個
* @param targetTypes 需要指定的目標類型,可以是pojo,可以是註解
* @return Set<Class<?>>
*/
public static Set<Class<?>> scan(String[] basePackages,
Class<?>... targetTypes) {
ClassScaner cs = new ClassScaner();
for (Class<?> targetType : targetTypes){
if(TypeUtils.isAssignable(Annotation.class, targetType)){
cs.addIncludeFilter(new AnnotationTypeFilter((Class<? extends Annotation>) targetType));
}else{
cs.addIncludeFilter(new AssignableTypeFilter(targetType));
}
}
Set<Class<?>> classes = new HashSet<Class<?>>();
for (String s : basePackages){
classes.addAll(cs.doScan(s));
}
return classes;
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackages 包名
* @return Set<Class<?>>
*/
public Set<Class<?>> doScan(String [] basePackages) {
Set<Class<?>> classes = new HashSet<Class<?>>();
for (String basePackage :basePackages) {
classes.addAll(doScan(basePackage));
}
return classes;
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackages 包名
* @return Set<Class<?>>
*/
public Set<Class<?>> doScan(String basePackage) {
Set<Class<?>> classes = new HashSet<Class<?>>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX
+ ClassUtils.convertClassNameToResourcePath(
SystemPropertyUtils.resolvePlaceholders(basePackage))+"/**/*.class";
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
for (int i = 0; i < resources.length; i++) {
Resource resource = resources[i];
if (resource.isReadable()) {
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
if ((includeFilters.size() == 0 && excludeFilters.size() == 0)|| matches(metadataReader)) {
try {
classes.add(Class.forName(metadataReader.getClassMetadata().getClassName()));
} catch (ClassNotFoundException ignore) {}
}
}
}
} catch (IOException ex) {
throw new RuntimeException("I/O failure during classpath scanning", ex);
}
return classes;
}
/**
* 處理 excludeFilters和includeFilters
* @param metadataReader
* @return boolean
* @throws IOException
*/
private boolean matches(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return true;
}
}
return false;
}
}
@Component
public class HandlerContext {
@Autowired
private ApplicationContext beanFactory;
public AbstractHandler getInstance(Integer type){
Map<Integer,Class> map = (Map<Integer, Class>) beanFactory.getBean(OrderHandlerType.class.getName());
return (AbstractHandler)beanFactory.getBean(map.get(type));
}
}
我這裡是在接受到MQ消息時,處理多個訂單來源業務,不同訂單來源路由到不同的業務處理類中。
@Component
@RabbitListener(queues = "OrderPipelineQueue")
public class PipelineSubscribe{
private final Logger LOGGER = LoggerFactory.getLogger(PipelineSubscribe.class);
@Autowired
private HandlerContext HandlerContext;
@Autowired
private OrderValidateService orderValidateService;
@RabbitHandler
public void subscribeMessage(MessageBean bean){
OrderBO orderBO = JSONObject.parseObject(bean.getOrderBO(), OrderBO.class);
if(null != orderBO &&CollectionUtils.isNotEmpty(bean.getType()))
{
for(int value:bean.getType())
{
AbstractHandler handler = HandlerContext.getInstance(value);
handler.handle(orderBO);
}
}
}
}
接收實體 MessageBean 類代碼
public class MessageBean implements Serializable {
private static final long serialVersionUID = 5454831432308782668L;
private String cachKey;
private List<Integer> type;
private String orderBO;
public MessageBean(List<Integer> type, String orderBO) {
this.type = type;
this.orderBO = orderBO;
}
}
以上設計模式方式看着略顯複雜,很些小夥伴提出質疑:“你為了個if-else,弄的如此的麻煩,又是自定義註解,又弄這麼多類不麻煩嗎?” 還有一些小夥伴糾結於性能問題,策略模式的性能可能確實不如if-else。
但我覺得吧增加一點複雜度、犧牲一丟丟性能,換代碼的整潔和可維護性還是值得的。不過,一個人一個想法,怎麼選還是看具體業務場景吧!
IOC容器和依賴注入的方式來解決。以下是訂單來源策略類的一部分,不得不說策略類確實比較多。
凡事都有他的兩面性,if-else多層嵌套和也都有其各自的優缺點:
if-else的優點就是簡單,想快速迭代功能,邏輯嵌套少且不會持續增加,if-else更好些,缺點也是顯而易見,代碼臃腫繁瑣不便於維護。
策略模式 將各個場景的邏輯剝離出來維護,同一抽象類有多個子類,需要使用if-else 或者 switch-case 來選擇具體子類時,建議選策略模式,他的缺點就是會產生比較多的策略類文件。
兩種實現方式各有利弊,如何選擇還是要依據具體業務場景,還是那句話設計模式不是為了用而用,一定要用在最合適的位置。
平常和粉絲私下聊天,好多人對於學設計模式的感受:設計模式背了一大堆,可平常開發還不是成天寫if-else業務邏輯,根本就用不到。
學設計模式也不是用不到,只是有時候沒有合適它的場景而已,像我們今天說的這種業務場景,用設計模式就可以完美的解決嘛。
學了N多技術可工作用不到是一種很常見的事情,一個穩定的項目使用一種技術會有諸多考量的,新技術會不會提升系統複雜度?它有哪些性能瓶頸?這些都必須考慮到,畢竟項目穩定才是最重要,誰也不敢輕易冒險嘗試。
而我們學習技術可不僅為了眼下項目中是否會用到,是要做一個技術積累,做長遠打算,人往高處走,沒點能力可不行。
原創不易,燃燒秀髮輸出內容,希望你能有一丟丟收穫!
整理了幾百本各類技術电子書,送給小夥伴們。關公眾號回復【666】自行領取。和一些小夥伴們建了一個技術交流群,一起探討技術、分享技術資料,旨在共同學習進步,如果感興趣就掃碼加入我們吧!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
相信絕大部分開發者都接觸過用戶註冊的流程,通常情況下大概的流程如下所示:
偽代碼如下:
public async Task<IActionResult> Reg([FromBody] User user)
{
_logger.LogInformation("持久化數據開始");
await Task.Delay(50);
_logger.LogInformation("持久化結束");
_logger.LogInformation("發送短信開始");
await Task.Delay(100);
_logger.LogInformation("發送短信結束");
_logger.LogInformation("操作日誌開始");
await _logRepository.Insert(new Log { Txt = "註冊日誌" });
_logger.LogInformation("操作日誌結束");
return Ok("註冊成功");
}
在以上的代碼中,我使用Task.Delay方法阻塞主線程,用以模擬實際場景中的執行耗時。以上流程應該是包含了絕大部分註冊流程所需要的操作。對於任何開發者來講,以上業務流程沒任何難度,無非是順序的執行各個流程的代碼即可。
稍微有點開發經驗的應該會將以上的流程進行拆分,但有些人可能就要問了,為什麼要拆分呢?拆分之後的代碼應該怎麼寫呢?下面我們就來簡單聊下如此場景的正確打開方式。
首先,註冊成功的依據應該是是否成功的將用戶信息持久化(至於是先持久化到數據庫,異或是先寫到redis不在本篇文章討論的範疇),至於發送註冊短信(郵件)以及寫日誌的操作應該不能成為影響註冊是否成功的因素,而發送短信/郵件等相關操作通常情況下也是比較耗時的,所以在對此接口做性能優化時,可優先考慮將短信/郵件以及寫日誌等相關操作與主流程(持久化數據)拆分,使其不阻塞主流程的執行,從而達到提高響應速度的目的。
知道了為什麼要拆,但具體如何拆分呢?怎樣才能用最少的改動,達到所需的目的呢?
條條大路通羅馬,所以要達成我們的目的也是有很多方案的,具體選擇哪種方案需要根據具體的業務場景,業務體量等多種因素綜合考慮,下面我將一一介紹分析相關方案。
在正式介紹可用方案前,筆者想先介紹一種很多新手容易錯誤使用的一種方案(因為筆者就曾經天真的使用過這種錯誤的方案)。
提到異步,絕大部分.net開發者應該第一想到的就是Task,async,await等,的確,async,await的語法糖簡化了.net開發者異步編程的門檻,減少了很多代碼量。通常一個返回Task類型的方法,在被調用時,會在方法的前面加上await,表示需要等待此方法的執行結果,再繼續執行後面的代碼。但如果不加await時,則不會等待方法的執行結果,進而也不會阻塞主線程。所以,有些人可能就會將發送短信/郵件以及寫日誌的操作如下方式進行改造。
public async Task<IActionResult> Reg1([FromBody] User user)
{
_logger.LogInformation("持久化數據開始");
await Task.Delay(50);
_logger.LogInformation("持久化結束");
_ = Task.Run(async () =>
{
_logger.LogInformation("發送短信開始");
await Task.Delay(100);
_logger.LogInformation("發送短信結束");
_logger.LogInformation("操作日誌開始");
await _logRepository.Insert(new Log { Txt = "註冊日誌" });
_logger.LogInformation("操作日誌結束");
});
return Ok("註冊成功");
}
然後使用jmeter分別壓測改造前和改造后的接口,結果如下:
有沒有被驚訝到?就這樣一個簡單的改造,吞吐量就提高了三四倍。既然已經提高了三四倍,那為什麼說這是一種錯誤的改造方法嗎?各位看官且往下看。
熟悉.netcore的大佬,應該都知道.netcore的依賴注入的生命周期吧。通常情況下,注入的生命周期包括:Singleton,Scope,Transient。
在以上的流程中,假如寫操作日誌的實例的生命周期是Scope,當在Task中調用Controller獲取到的實例的方法時,因為Task.Run並沒有阻塞主線程,當調用Action return后,當前請求的scope注入的對象會被回收,如果對象被回收之後,Task.Run還未執行完,則會報System.ObjectDisposedException: Cannot access a disposed object. 異常。意思是,不能訪問一個已disposed的對象。正確的做法是使用IServiceScopeFactory創建一個新的作用域,在新的作用域中獲取獲取日誌倉儲服務的實例。這樣就可以避免System.ObjectDisposedException異常了。
改造后的示例代碼如下:
public async Task<IActionResult> Reg1([FromBody] User user)
{
_logger.LogInformation("持久化數據開始");
await Task.Delay(50);
_logger.LogInformation("持久化結束");
_ = Task.Run(async () =>
{
using (var scope = _scopeFactory.CreateScope())
{
var sp = scope.ServiceProvider;
var logRepository = sp.GetService<ILogRepository>();
_logger.LogInformation("發送短信開始");
await Task.Delay(100);
_logger.LogInformation("發送短信結束");
_logger.LogInformation("操作日誌開始");
await logRepository.Insert(new Log { Txt = "註冊日誌" });
_logger.LogInformation("操作日誌結束");
}
});
return Ok("註冊成功");
}
雖然得到了正解,但上述的代碼着實有點多,如果一個項目有多個相似的業務場景,就要考慮對CreateScope相關的操作進行封裝。
下面就來一一介紹下筆者覺得實現此業務場景的幾種方案。
1.消息隊列
2.Quartz任務調度組件
3.Hangfire任務調度組件
4.Weshare.TransferJob(推薦)
首先說下消息隊列的方式。準確的說,消息隊列應該是這種場景的最優解決方案,消息隊列的其中一個比較重要的特性就是解耦,從而提高吞吐量。但並不是所有的應用程序都需要上消息隊列。有些業務場景使用消息隊列時,往往會給人一種”殺雞用牛刀”的感覺。
其次Quartz和Hangfire都是任務調度框架,都提供了可實現以上業務場景的邏輯,但Quartz和Hangfire都需要持久化作業數據。雖然Hangfire提供了內存版本,但經過我的測試,發現Hangfire的內存版本特別消耗內存,所以不太推薦使用任務調度框架來實現類似於這樣的業務邏輯。
最後,也就是本文的重點,筆者結合了消息隊列和任務調度的思想,實現了一個輕量級的轉移作業到後台執行的組件。此組件完美的解決了Scope生命周期實例獲取的問題,一行代碼將不需要等待的操作轉移到後台線程執行。
接入步驟如下:
1.使用nuget安裝Weshare.TransferJob
2.在Stratup中注入服務。
services.AddTransferJob();
3.通過構造函數或其他方法獲取到IBackgroundRunService的實例。
4.調用實例的Transfer方法將作業轉移到後台線程。
_backgroundRunService.Transfer(log=>log.Insert(new Log(){Txt = "註冊日誌"}));
就是這麼簡單的實現了這樣的業務場景,不僅簡化了代碼,而且大大提高了系統的吞吐量。
下面再來一起分析下Weshare.TransferJob的核心代碼(畢竟文章要點題)。各位器宇不凡的看官請繼續往下看。
下面的代碼是AddTransferJob方法的實現:
public static IServiceCollection AddTransferJob(this IServiceCollection services)
{
services.AddSingleton<IBackgroundRunService, BackgroundRunService>();
services.AddHostedService<TransferJobHostedService>();
return services;
}
聰明”絕頂”的各位看官應該已經發現上述代碼的關鍵所在。是的, 你沒有看錯,此組件的就是利用.net core提供的HostedService在後台執行被轉移的作業的。
我們再來一起看看TransferJobHostedService的代碼:
public class TransferJobHostedService:BackgroundService
{
private IBackgroundRunService _runService;
public TransferJobHostedService(IBackgroundRunService runService)
{
_runService = runService;
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
await _runService.Execute(stoppingToken);
}
}
}
這個類的代碼也很簡單,重寫了BackgroundService類的ExecuteAsync,循環調用IBackgroundRunService實例的Execute方法。所以,最最關鍵的代碼是IBackgroundRunService的實現類中。
詳細代碼如下:
public class BackgroundRunService : IBackgroundRunService
{
private readonly SemaphoreSlim _slim;
private readonly ConcurrentQueue<LambdaExpression> queue;
private ILogger<BackgroundRunService> _logger;
private readonly IServiceProvider _serviceProvider;
public BackgroundRunService(ILogger<BackgroundRunService> logger, IServiceProvider serviceProvider)
{
_slim = new SemaphoreSlim(1);
_logger = logger;
_serviceProvider = serviceProvider;
queue = new ConcurrentQueue<LambdaExpression>();
}
public async Task Execute(CancellationToken cancellationToken)
{
try
{
await _slim.WaitAsync(cancellationToken);
if (queue.TryDequeue(out var job))
{
using (var scope = _serviceProvider.GetRequiredService<IServiceScopeFactory>().CreateScope())
{
var action = job.Compile();
var isTask = action.Method.ReturnType == typeof(Task);
var parameters = job.Parameters;
var pars = new List<object>();
if (parameters.Any())
{
var type = parameters[0].Type;
var param = scope.ServiceProvider.GetRequiredService(type);
pars.Add(param);
}
if (isTask)
{
await (Task)action.DynamicInvoke(pars.ToArray());
}
else
{
action.DynamicInvoke(pars.ToArray());
}
}
}
}
catch (Exception e)
{
_logger.LogError(e.ToString());
}
}
public void Transfer<T>(Expression<Func<T, Task>> expression)
{
queue.Enqueue(expression);
_slim.Release();
}
public void Transfer(Expression<Action> expression)
{
queue.Enqueue(expression);
_slim.Release();
}
}
納尼?嫌代碼多看不懂?那咱們一起來剖析下吧。
首先,此類有三個較重要的私有變量,對應的類型分別是SemaphoreSlim, ConcurrentQueue ,IServiceProvider。
其中SemaphoreSlim是為了控制後台作業執行的順序的,在構造函數中初始化了此對象的信號量為1,表示在後台服務的ExecuteAsync方法的循環中每次只能有一個作業執行。
ConcurrentQueue 的對象是用來存儲被轉移到後台服務執行的作業的邏輯,所以使用LambdaExpression作為隊列的類型。
IServiceProvider是為了解決依賴注入的生命周期的。
然後在Execute方法中,第一行代碼如下:
await _slim.WaitAsync(cancellationToken);
作用是等待一個信號量,當沒有可用的信號量時,會阻塞線程的執行,這樣在後台服務的ExecuteAsync方法的死循環就不會一直執行下去,只有獲取到信號量才會繼續執行。
當獲取到信號量后,則說明有新的作業等待執行,所以此時則需要從隊列中讀出要執行的LambdaExpression表達式,創建一個新的Scope后,編譯此表達式樹,判斷返回類型,獲取泛型的具體類型,最後獲取到泛型對應的實例,執行對應的方法。
另外,Transfer方法就是暴露給調用者的方法,用於將表達式樹寫到隊列中,同時釋放信號量。
到此為止,Weshare.TransferJob的實現原理已分析完畢,由於此組件的原理只是將任務轉移到後台進行執行,所以並不是適合對事務有要求的場景。正如本文開頭所假設的場景,TransferJob最適合的場景還是那些和主操作關聯性較低的、失敗或成功並不會影響業務的正常運行。
同時,此組件的定位就是小而美,像延遲執行、定時執行的功能在最初的規劃中其實是有的,後來發現這些功能quartz已經有了,所以沒必要重複造這樣的輪子。
後期會根據使用場景,嘗試加入異常重試機制,以及異常通知回調機制。
最後,不知道有沒有較真的看官想計算下代碼量是否超過120行。
為了證明我不是標題黨,現將此組件進行開源,地址是:
https://github.com/fuluteam/WeShare.TransferJob
橋豆麻袋,筆者辛苦敲的代碼,難道各位看官想白嫖嗎? 點個贊再走唄。點完贊還有力氣的話,如果git上能點個star的話,那也是最好不過的。小生這廂先行謝過。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!