本文門檻較高,因此行文看起來會亂一些,如果你看到某處能會心一笑請馬上聯繫我開始擺龍門陣
如果你跟隨這篇文章實現了播放器,那你會得到一個高效率,低cpu佔用(單路720p視頻解碼播放佔用1%左右cpu),且代碼和引用精簡(無其他託管和非託管的dll依賴,更無需安裝任何插件,你的程序完全綠色運行);並且如果硬解不可用,切換到軟件是自動過程
首先需要準備好visual studio/msys2/ffmpeg源碼/dx9sdk。因為我們要自己編譯ffmpeg,並且是改動代碼后編譯,ffmpeg我們編譯時會裁剪。
- ffmpeg源碼大家使用4.2.1,和我保持同步,這樣比較好對應,下載地址為
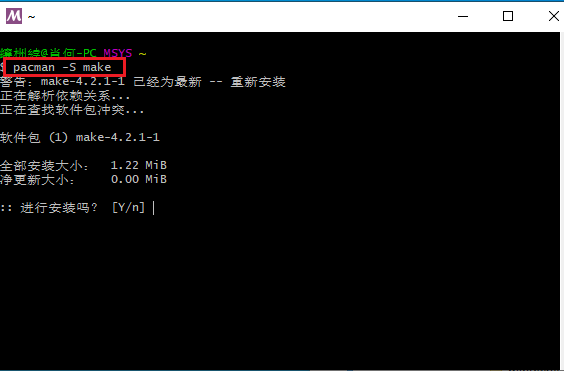
- msys2安裝好后不需要裝mingw和其他東西,只需要安裝make(見下方圖片;我們編譯工具鏈會用msvc而非mingw-gcc)
- visual studio版本按道理是不需要新版本的,應該是2008-2019都可以(不過還是得看看ffmpeg代碼里是否用了c99 c11等低版本不支持的東西),vs需要安裝c++和c#的模塊(見下方圖片;應該也不需要特意去打開什麼功能)
- dx9的sdk理論上是不用安裝的(如果你是高手,可以用c#的ilgenerator直接寫calli;亦或者寫unsafe代碼直接進行內存call,文章最後我會為大家揭秘如何用c#調用c++甚至com組件)。我用了directx的managecode,由官方為我們做了dx的調用(見下方圖片)
第二步是修改ffmpeg源碼並編譯,我們要修改的源碼只有一個文件的十餘行,而且是增量修改。
修改的文件位於libavutil/hwcontext_dxva2.c文件,我先將修改部分貼出來然後再給大家解釋
hwcontext_dxva2.c修改部分
static int dxva2_device_create9_extend(AVHWDeviceContext ctx, UINT adapter, HWND hWnd)
{
DXVA2DevicePriv priv = ctx->user_opaque;
D3DPRESENT_PARAMETERS d3dpp = {0};
D3DDISPLAYMODE d3ddm;
HRESULT hr;
pDirect3DCreate9 createD3D = (pDirect3DCreate9 )dlsym(priv->d3dlib, "Direct3DCreate9");
if (!createD3D) {
av_log(ctx, AV_LOG_ERROR, "Failed to locate Direct3DCreate9\n");
return AVERROR_UNKNOWN;
}priv->d3d9 = createD3D(D3D_SDK_VERSION); if (!priv->d3d9) { av_log(ctx, AV_LOG_ERROR, "Failed to create IDirect3D object\n"); return AVERROR_UNKNOWN; } IDirect3D9_GetAdapterDisplayMode(priv->d3d9, adapter, &d3ddm); d3dpp.BackBufferFormat = d3ddm.Format; d3dpp.Windowed = TRUE; // 是否窗口显示 d3dpp.hDeviceWindow = hWnd; // 显示窗口句柄 d3dpp.SwapEffect = D3DSWAPEFFECT_DISCARD; // 交換鏈設置,後台緩衝使用后直接丟棄 d3dpp.Flags = D3DPRESENTFLAG_VIDEO; // 附加特性,显示視頻 DWORD behaviorFlags = D3DCREATE_MULTITHREADED | D3DCREATE_FPU_PRESERVE; D3DDEVTYPE devType = D3DDEVTYPE_HAL; D3DCAPS9 caps; if (IDirect3D9_GetDeviceCaps(priv->d3d9, D3DADAPTER_DEFAULT, devType, &caps) >= 0) { if (caps.DevCaps & D3DDEVCAPS_HWTRANSFORMANDLIGHT) { behaviorFlags |= D3DCREATE_HARDWARE_VERTEXPROCESSING; } else { behaviorFlags |= D3DCREATE_SOFTWARE_VERTEXPROCESSING; } } if(!hWnd) hWnd = GetDesktopWindow(); hr = IDirect3D9_CreateDevice(priv->d3d9, adapter, D3DDEVTYPE_HAL, hWnd, behaviorFlags, &d3dpp, &priv->d3d9device); if (FAILED(hr)) { av_log(ctx, AV_LOG_ERROR, "Failed to create Direct3D device\n"); return AVERROR_UNKNOWN; } return 0;}
static int dxva2_device_create(AVHWDeviceContext ctx, const char device,
AVDictionary opts, int flags)
{
AVDXVA2DeviceContext hwctx = ctx->hwctx;
DXVA2DevicePriv priv;
pCreateDeviceManager9 createDeviceManager = NULL;
unsigned resetToken = 0;
UINT adapter = D3DADAPTER_DEFAULT;
HRESULT hr;
int err;
AVDictionaryEntry *t = NULL;
HWND hWnd = NULL;if (device) adapter = atoi(device); priv = av_mallocz(sizeof(*priv)); if (!priv) return AVERROR(ENOMEM); ctx->user_opaque = priv; ctx->free = dxva2_device_free; priv->device_handle = INVALID_HANDLE_VALUE; priv->d3dlib = dlopen("d3d9.dll", 0); if (!priv->d3dlib) { av_log(ctx, AV_LOG_ERROR, "Failed to load D3D9 library\n"); return AVERROR_UNKNOWN; } priv->dxva2lib = dlopen("dxva2.dll", 0); if (!priv->dxva2lib) { av_log(ctx, AV_LOG_ERROR, "Failed to load DXVA2 library\n"); return AVERROR_UNKNOWN; } createDeviceManager = (pCreateDeviceManager9 *)dlsym(priv->dxva2lib, "DXVA2CreateDirect3DDeviceManager9"); if (!createDeviceManager) { av_log(ctx, AV_LOG_ERROR, "Failed to locate DXVA2CreateDirect3DDeviceManager9\n"); return AVERROR_UNKNOWN; } t = av_dict_get(opts, "hWnd", NULL, 0); if(t) { hWnd = (HWND)atoi(t->value); } if(hWnd) { if((err = dxva2_device_create9_extend(ctx, adapter, hWnd)) < 0) return err; } else { if (dxva2_device_create9ex(ctx, adapter) < 0) { // Retry with "classic" d3d9 err = dxva2_device_create9(ctx, adapter); if (err < 0) return err; } } hr = createDeviceManager(&resetToken, &hwctx->devmgr); if (FAILED(hr)) { av_log(ctx, AV_LOG_ERROR, "Failed to create Direct3D device manager\n"); return AVERROR_UNKNOWN; } hr = IDirect3DDeviceManager9_ResetDevice(hwctx->devmgr, priv->d3d9device, resetToken); if (FAILED(hr)) { av_log(ctx, AV_LOG_ERROR, "Failed to bind Direct3D device to device manager\n"); return AVERROR_UNKNOWN; } hr = IDirect3DDeviceManager9_OpenDeviceHandle(hwctx->devmgr, &priv->device_handle); if (FAILED(hr)) { av_log(ctx, AV_LOG_ERROR, "Failed to open device handle\n"); return AVERROR_UNKNOWN; } return 0;
}
代碼中dxva2_device_create9_extend函數是我新加入的,並且在dxva2_device_create函數(這個函數是ffmpeg原始流程中的,我的改動不影響原本任何功能)中適時調用;簡單來說,原來的ffmpeg也能基於dxva2硬件解碼,但是它沒法將解碼得到的surface用於前台播放,因為它創建device時並未指定窗口和其他相關參數,大家可以參考我代碼實現,我將窗口句柄傳入后創建過程完全改變(其他人如果使用我們編譯的代碼,他沒有傳入窗口句柄,就執行原來的創建,因此百分百兼容)。
(ps:在這裏我講一下網絡上另外一種寫法(兩年前我也用的他們的,因為沒時間詳細看ffmpeg源碼),他們是在外面創建的device和surface然後想辦法傳到ffmpeg內部進行替換,這樣做有好處,就是不用自己修改和編譯ffmpeg,壞處是得自己維護device和surface。至於二進制兼容方面考慮,兩種做法都不是太好)
代碼修改完成后我們使用msys2編譯
- 首先是需要把編譯器設置為msvc,這個步驟通過使用vs的命令行工具即可,如下圖
- 然後是設置msys2繼承環境變量(這樣make時才能找到cl/link)
- 打開msys,查看變量是否正確
- 編譯ffmpeg
./configure --enable-shared --enable-small --disable-all --disable-autodetect --enable-avcodec --enable-decoder=h264 --enable-dxva2 --enable-hwaccel=h264_dxva2 --toolchain=msvc --prefix=host
make && make install編譯完成後頭文件和dll在host文件夾內(編譯產出的dll也是clear的,不依賴msvc**.dll)
在C#中使用我們產出的方式需要使用p/invoke和unsafe代碼。
我先貼出我針對ffmpeg寫的一個工具類,然後給大家稍微講解一下
FFHelper.cs
using System;
using System.Runtime.InteropServices;
namespace MultiPlayer
{
public enum AVCodecID
{
AV_CODEC_ID_NONE,
/* video codecs */
AV_CODEC_ID_MPEG1VIDEO,
AV_CODEC_ID_MPEG2VIDEO, ///< preferred ID for MPEG-1/2 video decoding
AV_CODEC_ID_H261,
AV_CODEC_ID_H263,
AV_CODEC_ID_RV10,
AV_CODEC_ID_RV20,
AV_CODEC_ID_MJPEG,
AV_CODEC_ID_MJPEGB,
AV_CODEC_ID_LJPEG,
AV_CODEC_ID_SP5X,
AV_CODEC_ID_JPEGLS,
AV_CODEC_ID_MPEG4,
AV_CODEC_ID_RAWVIDEO,
AV_CODEC_ID_MSMPEG4V1,
AV_CODEC_ID_MSMPEG4V2,
AV_CODEC_ID_MSMPEG4V3,
AV_CODEC_ID_WMV1,
AV_CODEC_ID_WMV2,
AV_CODEC_ID_H263P,
AV_CODEC_ID_H263I,
AV_CODEC_ID_FLV1,
AV_CODEC_ID_SVQ1,
AV_CODEC_ID_SVQ3,
AV_CODEC_ID_DVVIDEO,
AV_CODEC_ID_HUFFYUV,
AV_CODEC_ID_CYUV,
AV_CODEC_ID_H264,
AV_CODEC_ID_INDEO3,
AV_CODEC_ID_VP3,
AV_CODEC_ID_THEORA,
AV_CODEC_ID_ASV1,
AV_CODEC_ID_ASV2,
AV_CODEC_ID_FFV1,
AV_CODEC_ID_4XM,
AV_CODEC_ID_VCR1,
AV_CODEC_ID_CLJR,
AV_CODEC_ID_MDEC,
AV_CODEC_ID_ROQ,
AV_CODEC_ID_INTERPLAY_VIDEO,
AV_CODEC_ID_XAN_WC3,
AV_CODEC_ID_XAN_WC4,
AV_CODEC_ID_RPZA,
AV_CODEC_ID_CINEPAK,
AV_CODEC_ID_WS_VQA,
AV_CODEC_ID_MSRLE,
AV_CODEC_ID_MSVIDEO1,
AV_CODEC_ID_IDCIN,
AV_CODEC_ID_8BPS,
AV_CODEC_ID_SMC,
AV_CODEC_ID_FLIC,
AV_CODEC_ID_TRUEMOTION1,
AV_CODEC_ID_VMDVIDEO,
AV_CODEC_ID_MSZH,
AV_CODEC_ID_ZLIB,
AV_CODEC_ID_QTRLE,
AV_CODEC_ID_TSCC,
AV_CODEC_ID_ULTI,
AV_CODEC_ID_QDRAW,
AV_CODEC_ID_VIXL,
AV_CODEC_ID_QPEG,
AV_CODEC_ID_PNG,
AV_CODEC_ID_PPM,
AV_CODEC_ID_PBM,
AV_CODEC_ID_PGM,
AV_CODEC_ID_PGMYUV,
AV_CODEC_ID_PAM,
AV_CODEC_ID_FFVHUFF,
AV_CODEC_ID_RV30,
AV_CODEC_ID_RV40,
AV_CODEC_ID_VC1,
AV_CODEC_ID_WMV3,
AV_CODEC_ID_LOCO,
AV_CODEC_ID_WNV1,
AV_CODEC_ID_AASC,
AV_CODEC_ID_INDEO2,
AV_CODEC_ID_FRAPS,
AV_CODEC_ID_TRUEMOTION2,
AV_CODEC_ID_BMP,
AV_CODEC_ID_CSCD,
AV_CODEC_ID_MMVIDEO,
AV_CODEC_ID_ZMBV,
AV_CODEC_ID_AVS,
AV_CODEC_ID_SMACKVIDEO,
AV_CODEC_ID_NUV,
AV_CODEC_ID_KMVC,
AV_CODEC_ID_FLASHSV,
AV_CODEC_ID_CAVS,
AV_CODEC_ID_JPEG2000,
AV_CODEC_ID_VMNC,
AV_CODEC_ID_VP5,
AV_CODEC_ID_VP6,
AV_CODEC_ID_VP6F,
AV_CODEC_ID_TARGA,
AV_CODEC_ID_DSICINVIDEO,
AV_CODEC_ID_TIERTEXSEQVIDEO,
AV_CODEC_ID_TIFF,
AV_CODEC_ID_GIF,
AV_CODEC_ID_DXA,
AV_CODEC_ID_DNXHD,
AV_CODEC_ID_THP,
AV_CODEC_ID_SGI,
AV_CODEC_ID_C93,
AV_CODEC_ID_BETHSOFTVID,
AV_CODEC_ID_PTX,
AV_CODEC_ID_TXD,
AV_CODEC_ID_VP6A,
AV_CODEC_ID_AMV,
AV_CODEC_ID_VB,
AV_CODEC_ID_PCX,
AV_CODEC_ID_SUNRAST,
AV_CODEC_ID_INDEO4,
AV_CODEC_ID_INDEO5,
AV_CODEC_ID_MIMIC,
AV_CODEC_ID_RL2,
AV_CODEC_ID_ESCAPE124,
AV_CODEC_ID_DIRAC,
AV_CODEC_ID_BFI,
AV_CODEC_ID_CMV,
AV_CODEC_ID_MOTIONPIXELS,
AV_CODEC_ID_TGV,
AV_CODEC_ID_TGQ,
AV_CODEC_ID_TQI,
AV_CODEC_ID_AURA,
AV_CODEC_ID_AURA2,
AV_CODEC_ID_V210X,
AV_CODEC_ID_TMV,
AV_CODEC_ID_V210,
AV_CODEC_ID_DPX,
AV_CODEC_ID_MAD,
AV_CODEC_ID_FRWU,
AV_CODEC_ID_FLASHSV2,
AV_CODEC_ID_CDGRAPHICS,
AV_CODEC_ID_R210,
AV_CODEC_ID_ANM,
AV_CODEC_ID_BINKVIDEO,
AV_CODEC_ID_IFF_ILBM,
//#define AV_CODEC_ID_IFF_BYTERUN1 AV_CODEC_ID_IFF_ILBM
AV_CODEC_ID_KGV1,
AV_CODEC_ID_YOP,
AV_CODEC_ID_VP8,
AV_CODEC_ID_PICTOR,
AV_CODEC_ID_ANSI,
AV_CODEC_ID_A64_MULTI,
AV_CODEC_ID_A64_MULTI5,
AV_CODEC_ID_R10K,
AV_CODEC_ID_MXPEG,
AV_CODEC_ID_LAGARITH,
AV_CODEC_ID_PRORES,
AV_CODEC_ID_JV,
AV_CODEC_ID_DFA,
AV_CODEC_ID_WMV3IMAGE,
AV_CODEC_ID_VC1IMAGE,
AV_CODEC_ID_UTVIDEO,
AV_CODEC_ID_BMV_VIDEO,
AV_CODEC_ID_VBLE,
AV_CODEC_ID_DXTORY,
AV_CODEC_ID_V410,
AV_CODEC_ID_XWD,
AV_CODEC_ID_CDXL,
AV_CODEC_ID_XBM,
AV_CODEC_ID_ZEROCODEC,
AV_CODEC_ID_MSS1,
AV_CODEC_ID_MSA1,
AV_CODEC_ID_TSCC2,
AV_CODEC_ID_MTS2,
AV_CODEC_ID_CLLC,
AV_CODEC_ID_MSS2,
AV_CODEC_ID_VP9,
AV_CODEC_ID_AIC,
AV_CODEC_ID_ESCAPE130,
AV_CODEC_ID_G2M,
AV_CODEC_ID_WEBP,
AV_CODEC_ID_HNM4_VIDEO,
AV_CODEC_ID_HEVC,
//#define AV_CODEC_ID_H265 AV_CODEC_ID_HEVC
AV_CODEC_ID_FIC,
AV_CODEC_ID_ALIAS_PIX,
AV_CODEC_ID_BRENDER_PIX,
AV_CODEC_ID_PAF_VIDEO,
AV_CODEC_ID_EXR,
AV_CODEC_ID_VP7,
AV_CODEC_ID_SANM,
AV_CODEC_ID_SGIRLE,
AV_CODEC_ID_MVC1,
AV_CODEC_ID_MVC2,
AV_CODEC_ID_HQX,
AV_CODEC_ID_TDSC,
AV_CODEC_ID_HQ_HQA,
AV_CODEC_ID_HAP,
AV_CODEC_ID_DDS,
AV_CODEC_ID_DXV,
AV_CODEC_ID_SCREENPRESSO,
AV_CODEC_ID_RSCC,
AV_CODEC_ID_AVS2,
AV_CODEC_ID_Y41P = 0x8000,
AV_CODEC_ID_AVRP,
AV_CODEC_ID_012V,
AV_CODEC_ID_AVUI,
AV_CODEC_ID_AYUV,
AV_CODEC_ID_TARGA_Y216,
AV_CODEC_ID_V308,
AV_CODEC_ID_V408,
AV_CODEC_ID_YUV4,
AV_CODEC_ID_AVRN,
AV_CODEC_ID_CPIA,
AV_CODEC_ID_XFACE,
AV_CODEC_ID_SNOW,
AV_CODEC_ID_SMVJPEG,
AV_CODEC_ID_APNG,
AV_CODEC_ID_DAALA,
AV_CODEC_ID_CFHD,
AV_CODEC_ID_TRUEMOTION2RT,
AV_CODEC_ID_M101,
AV_CODEC_ID_MAGICYUV,
AV_CODEC_ID_SHEERVIDEO,
AV_CODEC_ID_YLC,
AV_CODEC_ID_PSD,
AV_CODEC_ID_PIXLET,
AV_CODEC_ID_SPEEDHQ,
AV_CODEC_ID_FMVC,
AV_CODEC_ID_SCPR,
AV_CODEC_ID_CLEARVIDEO,
AV_CODEC_ID_XPM,
AV_CODEC_ID_AV1,
AV_CODEC_ID_BITPACKED,
AV_CODEC_ID_MSCC,
AV_CODEC_ID_SRGC,
AV_CODEC_ID_SVG,
AV_CODEC_ID_GDV,
AV_CODEC_ID_FITS,
AV_CODEC_ID_IMM4,
AV_CODEC_ID_PROSUMER,
AV_CODEC_ID_MWSC,
AV_CODEC_ID_WCMV,
AV_CODEC_ID_RASC,
AV_CODEC_ID_HYMT,
AV_CODEC_ID_ARBC,
AV_CODEC_ID_AGM,
AV_CODEC_ID_LSCR,
AV_CODEC_ID_VP4,
/* various PCM "codecs" */
AV_CODEC_ID_FIRST_AUDIO = 0x10000, ///< A dummy id pointing at the start of audio codecs
AV_CODEC_ID_PCM_S16LE = 0x10000,
AV_CODEC_ID_PCM_S16BE,
AV_CODEC_ID_PCM_U16LE,
AV_CODEC_ID_PCM_U16BE,
AV_CODEC_ID_PCM_S8,
AV_CODEC_ID_PCM_U8,
AV_CODEC_ID_PCM_MULAW,
AV_CODEC_ID_PCM_ALAW,
AV_CODEC_ID_PCM_S32LE,
AV_CODEC_ID_PCM_S32BE,
AV_CODEC_ID_PCM_U32LE,
AV_CODEC_ID_PCM_U32BE,
AV_CODEC_ID_PCM_S24LE,
AV_CODEC_ID_PCM_S24BE,
AV_CODEC_ID_PCM_U24LE,
AV_CODEC_ID_PCM_U24BE,
AV_CODEC_ID_PCM_S24DAUD,
AV_CODEC_ID_PCM_ZORK,
AV_CODEC_ID_PCM_S16LE_PLANAR,
AV_CODEC_ID_PCM_DVD,
AV_CODEC_ID_PCM_F32BE,
AV_CODEC_ID_PCM_F32LE,
AV_CODEC_ID_PCM_F64BE,
AV_CODEC_ID_PCM_F64LE,
AV_CODEC_ID_PCM_BLURAY,
AV_CODEC_ID_PCM_LXF,
AV_CODEC_ID_S302M,
AV_CODEC_ID_PCM_S8_PLANAR,
AV_CODEC_ID_PCM_S24LE_PLANAR,
AV_CODEC_ID_PCM_S32LE_PLANAR,
AV_CODEC_ID_PCM_S16BE_PLANAR,
AV_CODEC_ID_PCM_S64LE = 0x10800,
AV_CODEC_ID_PCM_S64BE,
AV_CODEC_ID_PCM_F16LE,
AV_CODEC_ID_PCM_F24LE,
AV_CODEC_ID_PCM_VIDC,
/* various ADPCM codecs */
AV_CODEC_ID_ADPCM_IMA_QT = 0x11000,
AV_CODEC_ID_ADPCM_IMA_WAV,
AV_CODEC_ID_ADPCM_IMA_DK3,
AV_CODEC_ID_ADPCM_IMA_DK4,
AV_CODEC_ID_ADPCM_IMA_WS,
AV_CODEC_ID_ADPCM_IMA_SMJPEG,
AV_CODEC_ID_ADPCM_MS,
AV_CODEC_ID_ADPCM_4XM,
AV_CODEC_ID_ADPCM_XA,
AV_CODEC_ID_ADPCM_ADX,
AV_CODEC_ID_ADPCM_EA,
AV_CODEC_ID_ADPCM_G726,
AV_CODEC_ID_ADPCM_CT,
AV_CODEC_ID_ADPCM_SWF,
AV_CODEC_ID_ADPCM_YAMAHA,
AV_CODEC_ID_ADPCM_SBPRO_4,
AV_CODEC_ID_ADPCM_SBPRO_3,
AV_CODEC_ID_ADPCM_SBPRO_2,
AV_CODEC_ID_ADPCM_THP,
AV_CODEC_ID_ADPCM_IMA_AMV,
AV_CODEC_ID_ADPCM_EA_R1,
AV_CODEC_ID_ADPCM_EA_R3,
AV_CODEC_ID_ADPCM_EA_R2,
AV_CODEC_ID_ADPCM_IMA_EA_SEAD,
AV_CODEC_ID_ADPCM_IMA_EA_EACS,
AV_CODEC_ID_ADPCM_EA_XAS,
AV_CODEC_ID_ADPCM_EA_MAXIS_XA,
AV_CODEC_ID_ADPCM_IMA_ISS,
AV_CODEC_ID_ADPCM_G722,
AV_CODEC_ID_ADPCM_IMA_APC,
AV_CODEC_ID_ADPCM_VIMA,
AV_CODEC_ID_ADPCM_AFC = 0x11800,
AV_CODEC_ID_ADPCM_IMA_OKI,
AV_CODEC_ID_ADPCM_DTK,
AV_CODEC_ID_ADPCM_IMA_RAD,
AV_CODEC_ID_ADPCM_G726LE,
AV_CODEC_ID_ADPCM_THP_LE,
AV_CODEC_ID_ADPCM_PSX,
AV_CODEC_ID_ADPCM_AICA,
AV_CODEC_ID_ADPCM_IMA_DAT4,
AV_CODEC_ID_ADPCM_MTAF,
AV_CODEC_ID_ADPCM_AGM,
/* AMR */
AV_CODEC_ID_AMR_NB = 0x12000,
AV_CODEC_ID_AMR_WB,
/* RealAudio codecs*/
AV_CODEC_ID_RA_144 = 0x13000,
AV_CODEC_ID_RA_288,
/* various DPCM codecs */
AV_CODEC_ID_ROQ_DPCM = 0x14000,
AV_CODEC_ID_INTERPLAY_DPCM,
AV_CODEC_ID_XAN_DPCM,
AV_CODEC_ID_SOL_DPCM,
AV_CODEC_ID_SDX2_DPCM = 0x14800,
AV_CODEC_ID_GREMLIN_DPCM,
/* audio codecs */
AV_CODEC_ID_MP2 = 0x15000,
AV_CODEC_ID_MP3, ///< preferred ID for decoding MPEG audio layer 1, 2 or 3
AV_CODEC_ID_AAC,
AV_CODEC_ID_AC3,
AV_CODEC_ID_DTS,
AV_CODEC_ID_VORBIS,
AV_CODEC_ID_DVAUDIO,
AV_CODEC_ID_WMAV1,
AV_CODEC_ID_WMAV2,
AV_CODEC_ID_MACE3,
AV_CODEC_ID_MACE6,
AV_CODEC_ID_VMDAUDIO,
AV_CODEC_ID_FLAC,
AV_CODEC_ID_MP3ADU,
AV_CODEC_ID_MP3ON4,
AV_CODEC_ID_SHORTEN,
AV_CODEC_ID_ALAC,
AV_CODEC_ID_WESTWOOD_SND1,
AV_CODEC_ID_GSM, ///< as in Berlin toast format
AV_CODEC_ID_QDM2,
AV_CODEC_ID_COOK,
AV_CODEC_ID_TRUESPEECH,
AV_CODEC_ID_TTA,
AV_CODEC_ID_SMACKAUDIO,
AV_CODEC_ID_QCELP,
AV_CODEC_ID_WAVPACK,
AV_CODEC_ID_DSICINAUDIO,
AV_CODEC_ID_IMC,
AV_CODEC_ID_MUSEPACK7,
AV_CODEC_ID_MLP,
AV_CODEC_ID_GSM_MS, /* as found in WAV */
AV_CODEC_ID_ATRAC3,
AV_CODEC_ID_APE,
AV_CODEC_ID_NELLYMOSER,
AV_CODEC_ID_MUSEPACK8,
AV_CODEC_ID_SPEEX,
AV_CODEC_ID_WMAVOICE,
AV_CODEC_ID_WMAPRO,
AV_CODEC_ID_WMALOSSLESS,
AV_CODEC_ID_ATRAC3P,
AV_CODEC_ID_EAC3,
AV_CODEC_ID_SIPR,
AV_CODEC_ID_MP1,
AV_CODEC_ID_TWINVQ,
AV_CODEC_ID_TRUEHD,
AV_CODEC_ID_MP4ALS,
AV_CODEC_ID_ATRAC1,
AV_CODEC_ID_BINKAUDIO_RDFT,
AV_CODEC_ID_BINKAUDIO_DCT,
AV_CODEC_ID_AAC_LATM,
AV_CODEC_ID_QDMC,
AV_CODEC_ID_CELT,
AV_CODEC_ID_G723_1,
AV_CODEC_ID_G729,
AV_CODEC_ID_8SVX_EXP,
AV_CODEC_ID_8SVX_FIB,
AV_CODEC_ID_BMV_AUDIO,
AV_CODEC_ID_RALF,
AV_CODEC_ID_IAC,
AV_CODEC_ID_ILBC,
AV_CODEC_ID_OPUS,
AV_CODEC_ID_COMFORT_NOISE,
AV_CODEC_ID_TAK,
AV_CODEC_ID_METASOUND,
AV_CODEC_ID_PAF_AUDIO,
AV_CODEC_ID_ON2AVC,
AV_CODEC_ID_DSS_SP,
AV_CODEC_ID_CODEC2,
AV_CODEC_ID_FFWAVESYNTH = 0x15800,
AV_CODEC_ID_SONIC,
AV_CODEC_ID_SONIC_LS,
AV_CODEC_ID_EVRC,
AV_CODEC_ID_SMV,
AV_CODEC_ID_DSD_LSBF,
AV_CODEC_ID_DSD_MSBF,
AV_CODEC_ID_DSD_LSBF_PLANAR,
AV_CODEC_ID_DSD_MSBF_PLANAR,
AV_CODEC_ID_4GV,
AV_CODEC_ID_INTERPLAY_ACM,
AV_CODEC_ID_XMA1,
AV_CODEC_ID_XMA2,
AV_CODEC_ID_DST,
AV_CODEC_ID_ATRAC3AL,
AV_CODEC_ID_ATRAC3PAL,
AV_CODEC_ID_DOLBY_E,
AV_CODEC_ID_APTX,
AV_CODEC_ID_APTX_HD,
AV_CODEC_ID_SBC,
AV_CODEC_ID_ATRAC9,
AV_CODEC_ID_HCOM,
/* subtitle codecs */
AV_CODEC_ID_FIRST_SUBTITLE = 0x17000, ///< A dummy ID pointing at the start of subtitle codecs.
AV_CODEC_ID_DVD_SUBTITLE = 0x17000,
AV_CODEC_ID_DVB_SUBTITLE,
AV_CODEC_ID_TEXT, ///< raw UTF-8 text
AV_CODEC_ID_XSUB,
AV_CODEC_ID_SSA,
AV_CODEC_ID_MOV_TEXT,
AV_CODEC_ID_HDMV_PGS_SUBTITLE,
AV_CODEC_ID_DVB_TELETEXT,
AV_CODEC_ID_SRT,
AV_CODEC_ID_MICRODVD = 0x17800,
AV_CODEC_ID_EIA_608,
AV_CODEC_ID_JACOSUB,
AV_CODEC_ID_SAMI,
AV_CODEC_ID_REALTEXT,
AV_CODEC_ID_STL,
AV_CODEC_ID_SUBVIEWER1,
AV_CODEC_ID_SUBVIEWER,
AV_CODEC_ID_SUBRIP,
AV_CODEC_ID_WEBVTT,
AV_CODEC_ID_MPL2,
AV_CODEC_ID_VPLAYER,
AV_CODEC_ID_PJS,
AV_CODEC_ID_ASS,
AV_CODEC_ID_HDMV_TEXT_SUBTITLE,
AV_CODEC_ID_TTML,
AV_CODEC_ID_ARIB_CAPTION,
/* other specific kind of codecs (generally used for attachments) */
AV_CODEC_ID_FIRST_UNKNOWN = 0x18000, ///< A dummy ID pointing at the start of various fake codecs.
AV_CODEC_ID_TTF = 0x18000,
AV_CODEC_ID_SCTE_35, ///< Contain timestamp estimated through PCR of program stream.
AV_CODEC_ID_BINTEXT = 0x18800,
AV_CODEC_ID_XBIN,
AV_CODEC_ID_IDF,
AV_CODEC_ID_OTF,
AV_CODEC_ID_SMPTE_KLV,
AV_CODEC_ID_DVD_NAV,
AV_CODEC_ID_TIMED_ID3,
AV_CODEC_ID_BIN_DATA,
AV_CODEC_ID_PROBE = 0x19000, ///< codec_id is not known (like AV_CODEC_ID_NONE) but lavf should attempt to identify it
AV_CODEC_ID_MPEG2TS = 0x20000, /**< _FAKE_ codec to indicate a raw MPEG-2 TS
* stream (only used by libavformat) */
AV_CODEC_ID_MPEG4SYSTEMS = 0x20001, /**< _FAKE_ codec to indicate a MPEG-4 Systems
* stream (only used by libavformat) */
AV_CODEC_ID_FFMETADATA = 0x21000, ///< Dummy codec for streams containing only metadata information.
AV_CODEC_ID_WRAPPED_AVFRAME = 0x21001, ///< Passthrough codec, AVFrames wrapped in AVPacket
}
public enum AVHWDeviceType
{
AV_HWDEVICE_TYPE_NONE,
AV_HWDEVICE_TYPE_VDPAU,
AV_HWDEVICE_TYPE_CUDA,
AV_HWDEVICE_TYPE_VAAPI,
AV_HWDEVICE_TYPE_DXVA2,
AV_HWDEVICE_TYPE_QSV,
AV_HWDEVICE_TYPE_VIDEOTOOLBOX,
AV_HWDEVICE_TYPE_D3D11VA,
AV_HWDEVICE_TYPE_DRM,
AV_HWDEVICE_TYPE_OPENCL,
AV_HWDEVICE_TYPE_MEDIACODEC,
}
public enum AVPixelFormat
{
AV_PIX_FMT_NONE = -1,
AV_PIX_FMT_YUV420P, ///< planar YUV 4:2:0, 12bpp, (1 Cr & Cb sample per 2x2 Y samples)
AV_PIX_FMT_YUYV422, ///< packed YUV 4:2:2, 16bpp, Y0 Cb Y1 Cr
AV_PIX_FMT_RGB24, ///< packed RGB 8:8:8, 24bpp, RGBRGB...
AV_PIX_FMT_BGR24, ///< packed RGB 8:8:8, 24bpp, BGRBGR...
AV_PIX_FMT_YUV422P, ///< planar YUV 4:2:2, 16bpp, (1 Cr & Cb sample per 2x1 Y samples)
AV_PIX_FMT_YUV444P, ///< planar YUV 4:4:4, 24bpp, (1 Cr & Cb sample per 1x1 Y samples)
AV_PIX_FMT_YUV410P, ///< planar YUV 4:1:0, 9bpp, (1 Cr & Cb sample per 4x4 Y samples)
AV_PIX_FMT_YUV411P, ///< planar YUV 4:1:1, 12bpp, (1 Cr & Cb sample per 4x1 Y samples)
AV_PIX_FMT_GRAY8, ///< Y , 8bpp
AV_PIX_FMT_MONOWHITE, ///< Y , 1bpp, 0 is white, 1 is black, in each byte pixels are ordered from the msb to the lsb
AV_PIX_FMT_MONOBLACK, ///< Y , 1bpp, 0 is black, 1 is white, in each byte pixels are ordered from the msb to the lsb
AV_PIX_FMT_PAL8, ///< 8 bits with AV_PIX_FMT_RGB32 palette
AV_PIX_FMT_YUVJ420P, ///< planar YUV 4:2:0, 12bpp, full scale (JPEG), deprecated in favor of AV_PIX_FMT_YUV420P and setting color_range
AV_PIX_FMT_YUVJ422P, ///< planar YUV 4:2:2, 16bpp, full scale (JPEG), deprecated in favor of AV_PIX_FMT_YUV422P and setting color_range
AV_PIX_FMT_YUVJ444P, ///< planar YUV 4:4:4, 24bpp, full scale (JPEG), deprecated in favor of AV_PIX_FMT_YUV444P and setting color_range
AV_PIX_FMT_UYVY422, ///< packed YUV 4:2:2, 16bpp, Cb Y0 Cr Y1
AV_PIX_FMT_UYYVYY411, ///< packed YUV 4:1:1, 12bpp, Cb Y0 Y1 Cr Y2 Y3
AV_PIX_FMT_BGR8, ///< packed RGB 3:3:2, 8bpp, (msb)2B 3G 3R(lsb)
AV_PIX_FMT_BGR4, ///< packed RGB 1:2:1 bitstream, 4bpp, (msb)1B 2G 1R(lsb), a byte contains two pixels, the first pixel in the byte is the one composed by the 4 msb bits
AV_PIX_FMT_BGR4_BYTE, ///< packed RGB 1:2:1, 8bpp, (msb)1B 2G 1R(lsb)
AV_PIX_FMT_RGB8, ///< packed RGB 3:3:2, 8bpp, (msb)2R 3G 3B(lsb)
AV_PIX_FMT_RGB4, ///< packed RGB 1:2:1 bitstream, 4bpp, (msb)1R 2G 1B(lsb), a byte contains two pixels, the first pixel in the byte is the one composed by the 4 msb bits
AV_PIX_FMT_RGB4_BYTE, ///< packed RGB 1:2:1, 8bpp, (msb)1R 2G 1B(lsb)
AV_PIX_FMT_NV12, ///< planar YUV 4:2:0, 12bpp, 1 plane for Y and 1 plane for the UV components, which are interleaved (first byte U and the following byte V)
AV_PIX_FMT_NV21, ///< as above, but U and V bytes are swapped
AV_PIX_FMT_ARGB, ///< packed ARGB 8:8:8:8, 32bpp, ARGBARGB...
AV_PIX_FMT_RGBA, ///< packed RGBA 8:8:8:8, 32bpp, RGBARGBA...
AV_PIX_FMT_ABGR, ///< packed ABGR 8:8:8:8, 32bpp, ABGRABGR...
AV_PIX_FMT_BGRA, ///< packed BGRA 8:8:8:8, 32bpp, BGRABGRA...
AV_PIX_FMT_GRAY16BE, ///< Y , 16bpp, big-endian
AV_PIX_FMT_GRAY16LE, ///< Y , 16bpp, little-endian
AV_PIX_FMT_YUV440P, ///< planar YUV 4:4:0 (1 Cr & Cb sample per 1x2 Y samples)
AV_PIX_FMT_YUVJ440P, ///< planar YUV 4:4:0 full scale (JPEG), deprecated in favor of AV_PIX_FMT_YUV440P and setting color_range
AV_PIX_FMT_YUVA420P, ///< planar YUV 4:2:0, 20bpp, (1 Cr & Cb sample per 2x2 Y & A samples)
AV_PIX_FMT_RGB48BE, ///< packed RGB 16:16:16, 48bpp, 16R, 16G, 16B, the 2-byte value for each R/G/B component is stored as big-endian
AV_PIX_FMT_RGB48LE, ///< packed RGB 16:16:16, 48bpp, 16R, 16G, 16B, the 2-byte value for each R/G/B component is stored as little-endian
AV_PIX_FMT_RGB565BE, ///< packed RGB 5:6:5, 16bpp, (msb) 5R 6G 5B(lsb), big-endian
AV_PIX_FMT_RGB565LE, ///< packed RGB 5:6:5, 16bpp, (msb) 5R 6G 5B(lsb), little-endian
AV_PIX_FMT_RGB555BE, ///< packed RGB 5:5:5, 16bpp, (msb)1X 5R 5G 5B(lsb), big-endian , X=unused/undefined
AV_PIX_FMT_RGB555LE, ///< packed RGB 5:5:5, 16bpp, (msb)1X 5R 5G 5B(lsb), little-endian, X=unused/undefined
AV_PIX_FMT_BGR565BE, ///< packed BGR 5:6:5, 16bpp, (msb) 5B 6G 5R(lsb), big-endian
AV_PIX_FMT_BGR565LE, ///< packed BGR 5:6:5, 16bpp, (msb) 5B 6G 5R(lsb), little-endian
AV_PIX_FMT_BGR555BE, ///< packed BGR 5:5:5, 16bpp, (msb)1X 5B 5G 5R(lsb), big-endian , X=unused/undefined
AV_PIX_FMT_BGR555LE, ///< packed BGR 5:5:5, 16bpp, (msb)1X 5B 5G 5R(lsb), little-endian, X=unused/undefined
/** @name Deprecated pixel formats */
/**@{*/
AV_PIX_FMT_VAAPI_MOCO, ///< HW acceleration through VA API at motion compensation entry-point, Picture.data[3] contains a vaapi_render_state struct which contains macroblocks as well as various fields extracted from headers
AV_PIX_FMT_VAAPI_IDCT, ///< HW acceleration through VA API at IDCT entry-point, Picture.data[3] contains a vaapi_render_state struct which contains fields extracted from headers
AV_PIX_FMT_VAAPI_VLD, ///< HW decoding through VA API, Picture.data[3] contains a VASurfaceID
/**@}*/
AV_PIX_FMT_VAAPI = AV_PIX_FMT_VAAPI_VLD,
AV_PIX_FMT_YUV420P16LE, ///< planar YUV 4:2:0, 24bpp, (1 Cr & Cb sample per 2x2 Y samples), little-endian
AV_PIX_FMT_YUV420P16BE, ///< planar YUV 4:2:0, 24bpp, (1 Cr & Cb sample per 2x2 Y samples), big-endian
AV_PIX_FMT_YUV422P16LE, ///< planar YUV 4:2:2, 32bpp, (1 Cr & Cb sample per 2x1 Y samples), little-endian
AV_PIX_FMT_YUV422P16BE, ///< planar YUV 4:2:2, 32bpp, (1 Cr & Cb sample per 2x1 Y samples), big-endian
AV_PIX_FMT_YUV444P16LE, ///< planar YUV 4:4:4, 48bpp, (1 Cr & Cb sample per 1x1 Y samples), little-endian
AV_PIX_FMT_YUV444P16BE, ///< planar YUV 4:4:4, 48bpp, (1 Cr & Cb sample per 1x1 Y samples), big-endian
AV_PIX_FMT_DXVA2_VLD, ///< HW decoding through DXVA2, Picture.data[3] contains a LPDIRECT3DSURFACE9 pointer
AV_PIX_FMT_RGB444LE, ///< packed RGB 4:4:4, 16bpp, (msb)4X 4R 4G 4B(lsb), little-endian, X=unused/undefined
AV_PIX_FMT_RGB444BE, ///< packed RGB 4:4:4, 16bpp, (msb)4X 4R 4G 4B(lsb), big-endian, X=unused/undefined
AV_PIX_FMT_BGR444LE, ///< packed BGR 4:4:4, 16bpp, (msb)4X 4B 4G 4R(lsb), little-endian, X=unused/undefined
AV_PIX_FMT_BGR444BE, ///< packed BGR 4:4:4, 16bpp, (msb)4X 4B 4G 4R(lsb), big-endian, X=unused/undefined
AV_PIX_FMT_YA8, ///< 8 bits gray, 8 bits alpha
AV_PIX_FMT_Y400A = AV_PIX_FMT_YA8, ///< alias for AV_PIX_FMT_YA8
AV_PIX_FMT_GRAY8A = AV_PIX_FMT_YA8, ///< alias for AV_PIX_FMT_YA8
AV_PIX_FMT_BGR48BE, ///< packed RGB 16:16:16, 48bpp, 16B, 16G, 16R, the 2-byte value for each R/G/B component is stored as big-endian
AV_PIX_FMT_BGR48LE, ///< packed RGB 16:16:16, 48bpp, 16B, 16G, 16R, the 2-byte value for each R/G/B component is stored as little-endian
/**
* The following 12 formats have the disadvantage of needing 1 format for each bit depth.
* Notice that each 9/10 bits sample is stored in 16 bits with extra padding.
* If you want to support multiple bit depths, then using AV_PIX_FMT_YUV420P16* with the bpp stored separately is better.
*/
AV_PIX_FMT_YUV420P9BE, ///< planar YUV 4:2:0, 13.5bpp, (1 Cr & Cb sample per 2x2 Y samples), big-endian
AV_PIX_FMT_YUV420P9LE, ///< planar YUV 4:2:0, 13.5bpp, (1 Cr & Cb sample per 2x2 Y samples), little-endian
AV_PIX_FMT_YUV420P10BE,///< planar YUV 4:2:0, 15bpp, (1 Cr & Cb sample per 2x2 Y samples), big-endian
AV_PIX_FMT_YUV420P10LE,///< planar YUV 4:2:0, 15bpp, (1 Cr & Cb sample per 2x2 Y samples), little-endian
AV_PIX_FMT_YUV422P10BE,///< planar YUV 4:2:2, 20bpp, (1 Cr & Cb sample per 2x1 Y samples), big-endian
AV_PIX_FMT_YUV422P10LE,///< planar YUV 4:2:2, 20bpp, (1 Cr & Cb sample per 2x1 Y samples), little-endian
AV_PIX_FMT_YUV444P9BE, ///< planar YUV 4:4:4, 27bpp, (1 Cr & Cb sample per 1x1 Y samples), big-endian
AV_PIX_FMT_YUV444P9LE, ///< planar YUV 4:4:4, 27bpp, (1 Cr & Cb sample per 1x1 Y samples), little-endian
AV_PIX_FMT_YUV444P10BE,///< planar YUV 4:4:4, 30bpp, (1 Cr & Cb sample per 1x1 Y samples), big-endian
AV_PIX_FMT_YUV444P10LE,///< planar YUV 4:4:4, 30bpp, (1 Cr & Cb sample per 1x1 Y samples), little-endian
AV_PIX_FMT_YUV422P9BE, ///< planar YUV 4:2:2, 18bpp, (1 Cr & Cb sample per 2x1 Y samples), big-endian
AV_PIX_FMT_YUV422P9LE, ///< planar YUV 4:2:2, 18bpp, (1 Cr & Cb sample per 2x1 Y samples), little-endian
AV_PIX_FMT_GBRP, ///< planar GBR 4:4:4 24bpp
AV_PIX_FMT_GBR24P = AV_PIX_FMT_GBRP, // alias for #AV_PIX_FMT_GBRP
AV_PIX_FMT_GBRP9BE, ///< planar GBR 4:4:4 27bpp, big-endian
AV_PIX_FMT_GBRP9LE, ///< planar GBR 4:4:4 27bpp, little-endian
AV_PIX_FMT_GBRP10BE, ///< planar GBR 4:4:4 30bpp, big-endian
AV_PIX_FMT_GBRP10LE, ///< planar GBR 4:4:4 30bpp, little-endian
AV_PIX_FMT_GBRP16BE, ///< planar GBR 4:4:4 48bpp, big-endian
AV_PIX_FMT_GBRP16LE, ///< planar GBR 4:4:4 48bpp, little-endian
AV_PIX_FMT_YUVA422P, ///< planar YUV 4:2:2 24bpp, (1 Cr & Cb sample per 2x1 Y & A samples)
AV_PIX_FMT_YUVA444P, ///< planar YUV 4:4:4 32bpp, (1 Cr & Cb sample per 1x1 Y & A samples)
AV_PIX_FMT_YUVA420P9BE, ///< planar YUV 4:2:0 22.5bpp, (1 Cr & Cb sample per 2x2 Y & A samples), big-endian
AV_PIX_FMT_YUVA420P9LE, ///< planar YUV 4:2:0 22.5bpp, (1 Cr & Cb sample per 2x2 Y & A samples), little-endian
AV_PIX_FMT_YUVA422P9BE, ///< planar YUV 4:2:2 27bpp, (1 Cr & Cb sample per 2x1 Y & A samples), big-endian
AV_PIX_FMT_YUVA422P9LE, ///< planar YUV 4:2:2 27bpp, (1 Cr & Cb sample per 2x1 Y & A samples), little-endian
AV_PIX_FMT_YUVA444P9BE, ///< planar YUV 4:4:4 36bpp, (1 Cr & Cb sample per 1x1 Y & A samples), big-endian
AV_PIX_FMT_YUVA444P9LE, ///< planar YUV 4:4:4 36bpp, (1 Cr & Cb sample per 1x1 Y & A samples), little-endian
AV_PIX_FMT_YUVA420P10BE, ///< planar YUV 4:2:0 25bpp, (1 Cr & Cb sample per 2x2 Y & A samples, big-endian)
AV_PIX_FMT_YUVA420P10LE, ///< planar YUV 4:2:0 25bpp, (1 Cr & Cb sample per 2x2 Y & A samples, little-endian)
AV_PIX_FMT_YUVA422P10BE, ///< planar YUV 4:2:2 30bpp, (1 Cr & Cb sample per 2x1 Y & A samples, big-endian)
AV_PIX_FMT_YUVA422P10LE, ///< planar YUV 4:2:2 30bpp, (1 Cr & Cb sample per 2x1 Y & A samples, little-endian)
AV_PIX_FMT_YUVA444P10BE, ///< planar YUV 4:4:4 40bpp, (1 Cr & Cb sample per 1x1 Y & A samples, big-endian)
AV_PIX_FMT_YUVA444P10LE, ///< planar YUV 4:4:4 40bpp, (1 Cr & Cb sample per 1x1 Y & A samples, little-endian)
AV_PIX_FMT_YUVA420P16BE, ///< planar YUV 4:2:0 40bpp, (1 Cr & Cb sample per 2x2 Y & A samples, big-endian)
AV_PIX_FMT_YUVA420P16LE, ///< planar YUV 4:2:0 40bpp, (1 Cr & Cb sample per 2x2 Y & A samples, little-endian)
AV_PIX_FMT_YUVA422P16BE, ///< planar YUV 4:2:2 48bpp, (1 Cr & Cb sample per 2x1 Y & A samples, big-endian)
AV_PIX_FMT_YUVA422P16LE, ///< planar YUV 4:2:2 48bpp, (1 Cr & Cb sample per 2x1 Y & A samples, little-endian)
AV_PIX_FMT_YUVA444P16BE, ///< planar YUV 4:4:4 64bpp, (1 Cr & Cb sample per 1x1 Y & A samples, big-endian)
AV_PIX_FMT_YUVA444P16LE, ///< planar YUV 4:4:4 64bpp, (1 Cr & Cb sample per 1x1 Y & A samples, little-endian)
AV_PIX_FMT_VDPAU, ///< HW acceleration through VDPAU, Picture.data[3] contains a VdpVideoSurface
AV_PIX_FMT_XYZ12LE, ///< packed XYZ 4:4:4, 36 bpp, (msb) 12X, 12Y, 12Z (lsb), the 2-byte value for each X/Y/Z is stored as little-endian, the 4 lower bits are set to 0
AV_PIX_FMT_XYZ12BE, ///< packed XYZ 4:4:4, 36 bpp, (msb) 12X, 12Y, 12Z (lsb), the 2-byte value for each X/Y/Z is stored as big-endian, the 4 lower bits are set to 0
AV_PIX_FMT_NV16, ///< interleaved chroma YUV 4:2:2, 16bpp, (1 Cr & Cb sample per 2x1 Y samples)
AV_PIX_FMT_NV20LE, ///< interleaved chroma YUV 4:2:2, 20bpp, (1 Cr & Cb sample per 2x1 Y samples), little-endian
AV_PIX_FMT_NV20BE, ///< interleaved chroma YUV 4:2:2, 20bpp, (1 Cr & Cb sample per 2x1 Y samples), big-endian
AV_PIX_FMT_RGBA64BE, ///< packed RGBA 16:16:16:16, 64bpp, 16R, 16G, 16B, 16A, the 2-byte value for each R/G/B/A component is stored as big-endian
AV_PIX_FMT_RGBA64LE, ///< packed RGBA 16:16:16:16, 64bpp, 16R, 16G, 16B, 16A, the 2-byte value for each R/G/B/A component is stored as little-endian
AV_PIX_FMT_BGRA64BE, ///< packed RGBA 16:16:16:16, 64bpp, 16B, 16G, 16R, 16A, the 2-byte value for each R/G/B/A component is stored as big-endian
AV_PIX_FMT_BGRA64LE, ///< packed RGBA 16:16:16:16, 64bpp, 16B, 16G, 16R, 16A, the 2-byte value for each R/G/B/A component is stored as little-endian
AV_PIX_FMT_YVYU422, ///< packed YUV 4:2:2, 16bpp, Y0 Cr Y1 Cb
AV_PIX_FMT_YA16BE, ///< 16 bits gray, 16 bits alpha (big-endian)
AV_PIX_FMT_YA16LE, ///< 16 bits gray, 16 bits alpha (little-endian)
AV_PIX_FMT_GBRAP, ///< planar GBRA 4:4:4:4 32bpp
AV_PIX_FMT_GBRAP16BE, ///< planar GBRA 4:4:4:4 64bpp, big-endian
AV_PIX_FMT_GBRAP16LE, ///< planar GBRA 4:4:4:4 64bpp, little-endian
/**
* HW acceleration through QSV, data[3] contains a pointer to the
* mfxFrameSurface1 structure.
*/
AV_PIX_FMT_QSV,
/**
* HW acceleration though MMAL, data[3] contains a pointer to the
* MMAL_BUFFER_HEADER_T structure.
*/
AV_PIX_FMT_MMAL,
AV_PIX_FMT_D3D11VA_VLD, ///< HW decoding through Direct3D11 via old API, Picture.data[3] contains a ID3D11VideoDecoderOutputView pointer
/**
* HW acceleration through CUDA. data[i] contain CUdeviceptr pointers
* exactly as for system memory frames.
*/
AV_PIX_FMT_CUDA,
AV_PIX_FMT_0RGB, ///< packed RGB 8:8:8, 32bpp, XRGBXRGB... X=unused/undefined
AV_PIX_FMT_RGB0, ///< packed RGB 8:8:8, 32bpp, RGBXRGBX... X=unused/undefined
AV_PIX_FMT_0BGR, ///< packed BGR 8:8:8, 32bpp, XBGRXBGR... X=unused/undefined
AV_PIX_FMT_BGR0, ///< packed BGR 8:8:8, 32bpp, BGRXBGRX... X=unused/undefined
AV_PIX_FMT_YUV420P12BE, ///< planar YUV 4:2:0,18bpp, (1 Cr & Cb sample per 2x2 Y samples), big-endian
AV_PIX_FMT_YUV420P12LE, ///< planar YUV 4:2:0,18bpp, (1 Cr & Cb sample per 2x2 Y samples), little-endian
AV_PIX_FMT_YUV420P14BE, ///< planar YUV 4:2:0,21bpp, (1 Cr & Cb sample per 2x2 Y samples), big-endian
AV_PIX_FMT_YUV420P14LE, ///< planar YUV 4:2:0,21bpp, (1 Cr & Cb sample per 2x2 Y samples), little-endian
AV_PIX_FMT_YUV422P12BE, ///< planar YUV 4:2:2,24bpp, (1 Cr & Cb sample per 2x1 Y samples), big-endian
AV_PIX_FMT_YUV422P12LE, ///< planar YUV 4:2:2,24bpp, (1 Cr & Cb sample per 2x1 Y samples), little-endian
AV_PIX_FMT_YUV422P14BE, ///< planar YUV 4:2:2,28bpp, (1 Cr & Cb sample per 2x1 Y samples), big-endian
AV_PIX_FMT_YUV422P14LE, ///< planar YUV 4:2:2,28bpp, (1 Cr & Cb sample per 2x1 Y samples), little-endian
AV_PIX_FMT_YUV444P12BE, ///< planar YUV 4:4:4,36bpp, (1 Cr & Cb sample per 1x1 Y samples), big-endian
AV_PIX_FMT_YUV444P12LE, ///< planar YUV 4:4:4,36bpp, (1 Cr & Cb sample per 1x1 Y samples), little-endian
AV_PIX_FMT_YUV444P14BE, ///< planar YUV 4:4:4,42bpp, (1 Cr & Cb sample per 1x1 Y samples), big-endian
AV_PIX_FMT_YUV444P14LE, ///< planar YUV 4:4:4,42bpp, (1 Cr & Cb sample per 1x1 Y samples), little-endian
AV_PIX_FMT_GBRP12BE, ///< planar GBR 4:4:4 36bpp, big-endian
AV_PIX_FMT_GBRP12LE, ///< planar GBR 4:4:4 36bpp, little-endian
AV_PIX_FMT_GBRP14BE, ///< planar GBR 4:4:4 42bpp, big-endian
AV_PIX_FMT_GBRP14LE, ///< planar GBR 4:4:4 42bpp, little-endian
AV_PIX_FMT_YUVJ411P, ///< planar YUV 4:1:1, 12bpp, (1 Cr & Cb sample per 4x1 Y samples) full scale (JPEG), deprecated in favor of AV_PIX_FMT_YUV411P and setting color_range
AV_PIX_FMT_BAYER_BGGR8, ///< bayer, BGBG..(odd line), GRGR..(even line), 8-bit samples */
AV_PIX_FMT_BAYER_RGGB8, ///< bayer, RGRG..(odd line), GBGB..(even line), 8-bit samples */
AV_PIX_FMT_BAYER_GBRG8, ///< bayer, GBGB..(odd line), RGRG..(even line), 8-bit samples */
AV_PIX_FMT_BAYER_GRBG8, ///< bayer, GRGR..(odd line), BGBG..(even line), 8-bit samples */
AV_PIX_FMT_BAYER_BGGR16LE, ///< bayer, BGBG..(odd line), GRGR..(even line), 16-bit samples, little-endian */
AV_PIX_FMT_BAYER_BGGR16BE, ///< bayer, BGBG..(odd line), GRGR..(even line), 16-bit samples, big-endian */
AV_PIX_FMT_BAYER_RGGB16LE, ///< bayer, RGRG..(odd line), GBGB..(even line), 16-bit samples, little-endian */
AV_PIX_FMT_BAYER_RGGB16BE, ///< bayer, RGRG..(odd line), GBGB..(even line), 16-bit samples, big-endian */
AV_PIX_FMT_BAYER_GBRG16LE, ///< bayer, GBGB..(odd line), RGRG..(even line), 16-bit samples, little-endian */
AV_PIX_FMT_BAYER_GBRG16BE, ///< bayer, GBGB..(odd line), RGRG..(even line), 16-bit samples, big-endian */
AV_PIX_FMT_BAYER_GRBG16LE, ///< bayer, GRGR..(odd line), BGBG..(even line), 16-bit samples, little-endian */
AV_PIX_FMT_BAYER_GRBG16BE, ///< bayer, GRGR..(odd line), BGBG..(even line), 16-bit samples, big-endian */
AV_PIX_FMT_XVMC,///< XVideo Motion Acceleration via common packet passing
AV_PIX_FMT_YUV440P10LE, ///< planar YUV 4:4:0,20bpp, (1 Cr & Cb sample per 1x2 Y samples), little-endian
AV_PIX_FMT_YUV440P10BE, ///< planar YUV 4:4:0,20bpp, (1 Cr & Cb sample per 1x2 Y samples), big-endian
AV_PIX_FMT_YUV440P12LE, ///< planar YUV 4:4:0,24bpp, (1 Cr & Cb sample per 1x2 Y samples), little-endian
AV_PIX_FMT_YUV440P12BE, ///< planar YUV 4:4:0,24bpp, (1 Cr & Cb sample per 1x2 Y samples), big-endian
AV_PIX_FMT_AYUV64LE, ///< packed AYUV 4:4:4,64bpp (1 Cr & Cb sample per 1x1 Y & A samples), little-endian
AV_PIX_FMT_AYUV64BE, ///< packed AYUV 4:4:4,64bpp (1 Cr & Cb sample per 1x1 Y & A samples), big-endian
AV_PIX_FMT_VIDEOTOOLBOX, ///< hardware decoding through Videotoolbox
AV_PIX_FMT_P010LE, ///< like NV12, with 10bpp per component, data in the high bits, zeros in the low bits, little-endian
AV_PIX_FMT_P010BE, ///< like NV12, with 10bpp per component, data in the high bits, zeros in the low bits, big-endian
AV_PIX_FMT_GBRAP12BE, ///< planar GBR 4:4:4:4 48bpp, big-endian
AV_PIX_FMT_GBRAP12LE, ///< planar GBR 4:4:4:4 48bpp, little-endian
AV_PIX_FMT_GBRAP10BE, ///< planar GBR 4:4:4:4 40bpp, big-endian
AV_PIX_FMT_GBRAP10LE, ///< planar GBR 4:4:4:4 40bpp, little-endian
AV_PIX_FMT_MEDIACODEC, ///< hardware decoding through MediaCodec
AV_PIX_FMT_GRAY12BE, ///< Y , 12bpp, big-endian
AV_PIX_FMT_GRAY12LE, ///< Y , 12bpp, little-endian
AV_PIX_FMT_GRAY10BE, ///< Y , 10bpp, big-endian
AV_PIX_FMT_GRAY10LE, ///< Y , 10bpp, little-endian
AV_PIX_FMT_P016LE, ///< like NV12, with 16bpp per component, little-endian
AV_PIX_FMT_P016BE, ///< like NV12, with 16bpp per component, big-endian
/**
* Hardware surfaces for Direct3D11.
*
* This is preferred over the legacy AV_PIX_FMT_D3D11VA_VLD. The new D3D11
* hwaccel API and filtering support AV_PIX_FMT_D3D11 only.
*
* data[0] contains a ID3D11Texture2D pointer, and data[1] contains the
* texture array index of the frame as intptr_t if the ID3D11Texture2D is
* an array texture (or always 0 if it's a normal texture).
*/
AV_PIX_FMT_D3D11,
AV_PIX_FMT_GRAY9BE, ///< Y , 9bpp, big-endian
AV_PIX_FMT_GRAY9LE, ///< Y , 9bpp, little-endian
AV_PIX_FMT_GBRPF32BE, ///< IEEE-754 single precision planar GBR 4:4:4, 96bpp, big-endian
AV_PIX_FMT_GBRPF32LE, ///< IEEE-754 single precision planar GBR 4:4:4, 96bpp, little-endian
AV_PIX_FMT_GBRAPF32BE, ///< IEEE-754 single precision planar GBRA 4:4:4:4, 128bpp, big-endian
AV_PIX_FMT_GBRAPF32LE, ///< IEEE-754 single precision planar GBRA 4:4:4:4, 128bpp, little-endian
/**
* DRM-managed buffers exposed through PRIME buffer sharing.
*
* data[0] points to an AVDRMFrameDescriptor.
*/
AV_PIX_FMT_DRM_PRIME,
/**
* Hardware surfaces for OpenCL.
*
* data[i] contain 2D image objects (typed in C as cl_mem, used
* in OpenCL as image2d_t) for each plane of the surface.
*/
AV_PIX_FMT_OPENCL,
AV_PIX_FMT_GRAY14BE, ///< Y , 14bpp, big-endian
AV_PIX_FMT_GRAY14LE, ///< Y , 14bpp, little-endian
AV_PIX_FMT_GRAYF32BE, ///< IEEE-754 single precision Y, 32bpp, big-endian
AV_PIX_FMT_GRAYF32LE, ///< IEEE-754 single precision Y, 32bpp, little-endian
AV_PIX_FMT_YUVA422P12BE, ///< planar YUV 4:2:2,24bpp, (1 Cr & Cb sample per 2x1 Y samples), 12b alpha, big-endian
AV_PIX_FMT_YUVA422P12LE, ///< planar YUV 4:2:2,24bpp, (1 Cr & Cb sample per 2x1 Y samples), 12b alpha, little-endian
AV_PIX_FMT_YUVA444P12BE, ///< planar YUV 4:4:4,36bpp, (1 Cr & Cb sample per 1x1 Y samples), 12b alpha, big-endian
AV_PIX_FMT_YUVA444P12LE, ///< planar YUV 4:4:4,36bpp, (1 Cr & Cb sample per 1x1 Y samples), 12b alpha, little-endian
AV_PIX_FMT_NV24, ///< planar YUV 4:4:4, 24bpp, 1 plane for Y and 1 plane for the UV components, which are interleaved (first byte U and the following byte V)
AV_PIX_FMT_NV42, ///< as above, but U and V bytes are swapped
AV_PIX_FMT_NB ///< number of pixel formats, DO NOT USE THIS if you want to link with shared libav* because the number of formats might differ between versions
}
/// /// ffmpeg中AVFrame結構體的前半部分,因為它太長了我不需要完全移植過來 ///
[StructLayout(LayoutKind.Sequential, Pack = 1, Size = 408)]
public struct AVFrame
{
//#define AV_NUM_DATA_POINTERS 8
// uint8_t* data[AV_NUM_DATA_POINTERS];
public IntPtr data1;// 一般是y分量
public IntPtr data2;// 一般是v分量
public IntPtr data3;// 一般是u分量
public IntPtr data4;// 一般是surface(dxva2硬解時)
public IntPtr data5;
public IntPtr data6;
public IntPtr data7;
public IntPtr data8;
public int linesize1;// y分量每行長度(stride)
public int linesize2;// v分量每行長度(stride)
public int linesize3;// u分量每行長度(stride)
public int linesize4;
public int linesize5;
public int linesize6;
public int linesize7;
public int linesize8;
//uint8_t **extended_data;
IntPtr extended_data;
public int width;
public int height;
public int nb_samples;
public AVPixelFormat format;
}
[StructLayout(LayoutKind.Sequential, Pack = 1, Size = 128)]
public struct AVCodec { }
[StructLayout(LayoutKind.Sequential, Pack = 1, Size = 72)]
public unsafe struct AVPacket
{
fixed byte frontUnused[24]; // 前部無關數據
public void* data;
public int size;
}
[StructLayout(LayoutKind.Sequential, Pack = 1, Size = 12)]
public struct AVBufferRef { }
[StructLayout(LayoutKind.Sequential, Pack = 1, Size = 904)]
public unsafe struct AVCodecContext
{
fixed byte frontUnused[880]; // 前部無關數據
public AVBufferRef* hw_frames_ctx;
}
[StructLayout(LayoutKind.Sequential)]
public struct AVDictionary { }
public unsafe static class FFHelper
{
const string avcodec = "avcodec-58";
const string avutil = "avutil-56";
const CallingConvention callingConvention = CallingConvention.Cdecl;
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static void avcodec_register_all();
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static AVCodec* avcodec_find_decoder(AVCodecID id);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static AVPacket* av_packet_alloc();
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static void av_init_packet(AVPacket* pkt);
//[DllImport(avcodec, CallingConvention = callingConvention)]
//public extern static void av_packet_unref(AVPacket* pkt);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static void av_packet_free(AVPacket** pkt);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static AVCodecContext* avcodec_alloc_context3(AVCodec* codec);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static int avcodec_open2(AVCodecContext* avctx, AVCodec* codec, AVDictionary** options);
//[DllImport(avcodec, CallingConvention = callingConvention)]
//public extern static int avcodec_decode_video2(IntPtr avctx, IntPtr picture, ref int got_picture_ptr, IntPtr avpkt);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static void avcodec_free_context(AVCodecContext** avctx);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static int avcodec_send_packet(AVCodecContext* avctx, AVPacket* pkt);
[DllImport(avcodec, CallingConvention = callingConvention)]
public extern static int avcodec_receive_frame(AVCodecContext* avctx, AVFrame* frame);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static int av_hwdevice_ctx_create(AVBufferRef** device_ctx, AVHWDeviceType type, string device, AVDictionary* opts, int flags);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static AVBufferRef* av_buffer_ref(AVBufferRef* buf);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static void av_buffer_unref(AVBufferRef** buf);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static AVFrame* av_frame_alloc();
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static void av_frame_free(AVFrame** frame);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static void av_log_set_level(int level);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static int av_dict_set_int(AVDictionary** pm, string key, long value, int flags);
[DllImport(avutil, CallingConvention = callingConvention)]
public extern static void av_dict_free(AVDictionary** m);
}
}
上文中主要有幾個地方是知識點,大家做c#的如果需要和底層交互可以了解一下
- 結構體的使用
結構體在c#與c/c++基本一致,都是內存連續變量的一種組合方式。與c/c++相同,在c#中,如果我們不知道(或者可以規避,因為結構體可能很複雜,很多無關字段)結構體細節只知道結構體整體大小時,我們可以用Pack=1,SizeConst=來表示一個大小已知的結構體。 - 指針的使用
c#中,有兩種存儲內存地址(指針)的方式,一是使用interop體系中的IntPtr類型(大家可以將其想象成void*),一是在不安全的上下文(unsafe)中使用結構體類型指針(此處不討論c++類指針) - unsafe和fixed使用
簡單來說,有了unsafe你才能用指針;而有了fixed你才能確保指針指向位置不被GC壓縮。我們使用fixed達到的效果就是顯式跳過了結構體中前部無關數據(參考上文中AVCodecContext等結構體定義),後文中我們還會使用fixed。
現在我們開始編寫解碼和播放部分(即我們的具體應用)代碼
FFPlayer.cs
using Microsoft.DirectX;
using Microsoft.DirectX.Direct3D;
using System;
using System.Drawing;
using System.Runtime.InteropServices;
using System.Text;
using System.Windows.Forms;
using static MultiPlayer.FFHelper;namespace MultiPlayer
{
public unsafe partial class FFPlayer : UserControl
{
[DllImport("msvcrt", EntryPoint = "memcpy", CallingConvention = CallingConvention.Cdecl, SetLastError = false)]
static extern void memcpy(IntPtr dest, IntPtr src, int count); // 用於在解碼器和directx間拷貝內存的c函數private IntPtr contentPanelHandle; // 畫面渲染的控件句柄,因為畫面渲染時可能出於非UI線程,因此先保存句柄避免CLR報錯 private int lastIWidth, lastIHeight; // 上次控件大小,用於在控件大小改變時做出判定重新初始化渲染上下文 private Rectangle lastCBounds; // 臨時變量,存儲上次控件區域(屏幕坐標) private Rectangle lastVRect; // 臨時變量,存儲上次解碼出的圖像大小 private Device device; // 當使用軟解時,這個變量生效,它是IDirect3Device9*對象,用於繪製YUV private Surface surface; // 當使用軟解時,這個變量生效,它是IDirect3Surface9*對象,用於接受解碼后的YUV數據 AVPixelFormat lastFmt; // 上次解碼出的圖像數據類型,這個理論上不會變 AVCodec* codec; // ffmpeg的解碼器 AVCodecContext* ctx; // ffmpeg的解碼上下文 AVBufferRef* hw_ctx; // ffmpeg的解碼器硬件加速上下文,作為ctx的擴展存在 AVPacket* avpkt; // ffmpeg的數據包,用於封送待解碼數據 IntPtr nalData; // 一塊預分配內存,作為avpkt中真正存儲數據的內存地址 AVFrame* frame; // ffmpeg的已解碼幀,用於回傳解碼后的圖像 private volatile bool _released = false; // 資源釋放標識,與鎖配合使用避免重複釋放資源(由於底層是c/c++,多線程下double free會導致程序崩潰) private object _codecLocker = new object(); // 鎖,用於多線程下的互斥 static FFPlayer() { avcodec_register_all(); // 靜態塊中註冊ffmpeg解碼器 } public FFPlayer() { InitializeComponent(); // 過程中,下列對象只需初始化一次 frame = av_frame_alloc(); avpkt = av_packet_alloc(); av_init_packet(avpkt); nalData = Marshal.AllocHGlobal(1024 * 1024); codec = avcodec_find_decoder(AVCodecID.AV_CODEC_ID_H264); avpkt->data = (void*)nalData; } ~FFPlayer() { // 過程中,下列對象只需釋放一次 if (null != frame) fixed (AVFrame** LPframe = &frame) av_frame_free(LPframe); if (null != avpkt) fixed (AVPacket** LPpkt = &avpkt) av_packet_free(LPpkt); if (default != nalData) Marshal.FreeHGlobal(nalData); } // 釋放資源 // 此函數並非表示“終止”,更多的是表示“改變”和“重置”,實際上對此函數的調用更多的是發生在界面大小發生變化時和網絡掉包導致硬解異常時 private void Releases() { // 過程中,下列對象會重複創建和銷毀多次 lock (_codecLocker) { if (_released) return; if (null != ctx) fixed (AVCodecContext** LPctx = &ctx) avcodec_free_context(LPctx); if (null != hw_ctx) fixed (AVBufferRef** LPhw_ctx = &hw_ctx) av_buffer_unref(LPhw_ctx); // (PS:device和surface我們將其置為null,讓GC幫我們調用Finalize,它則會自行釋放資源) surface = null; device = null; lastFmt = AVPixelFormat.AV_PIX_FMT_NONE; _released = true; } } // Load事件中保存控件句柄 private void FFPlayer_Load(object sender, EventArgs e) { contentPanelHandle = Handle; // 這個句柄也可以是你控件內真正要渲染畫面的句柄 lastCBounds = ClientRectangle; // 同理,區域也不一定是自身显示區域 } // 解碼函數,由外部調用,送一一個分片好的nal public void H264Received(byte[] nal) { lock (_codecLocker) { // 判斷界面大小更改了,先重置一波 // (因為DirectX中界面大小改變是一件大事,沒得法繞過,只能推倒從來) // 如果你的显示控件不是當前控件本身,此處需要做修改 if (!ClientRectangle.Equals(lastCBounds)) { lastCBounds = ClientRectangle; Releases(); } if (null == ctx) { // 第一次接收到待解碼數據時初始化一個解碼器上下文 ctx = avcodec_alloc_context3(codec); if (null == ctx) { return; } // 通過參數傳遞控件句柄給硬件加速上下文 AVDictionary* dic; av_dict_set_int(&dic, "hWnd", contentPanelHandle.ToInt64(), 0); fixed (AVBufferRef** LPhw_ctx = &hw_ctx) { if (av_hwdevice_ctx_create(LPhw_ctx, AVHWDeviceType.AV_HWDEVICE_TYPE_DXVA2, null, dic, 0) >= 0) { ctx->hw_frames_ctx = av_buffer_ref(hw_ctx); } } av_dict_free(&dic); ctx->hw_frames_ctx = av_buffer_ref(hw_ctx); if (avcodec_open2(ctx, codec, null) < 0) { fixed (AVCodecContext** LPctx = &ctx) avcodec_free_context(LPctx); fixed (AVBufferRef** LPhw_ctx = &hw_ctx) av_buffer_unref(LPhw_ctx); return; } } _released = false; // 開始解碼 Marshal.Copy(nal, 0, nalData, nal.Length); avpkt->size = nal.Length; if (avcodec_send_packet(ctx, avpkt) < 0) { Releases(); return; // 如果程序走到了這裏,一般是因為網絡掉包導致nal數據不連續,沒辦法, 推倒從來 } receive_frame: int err = avcodec_receive_frame(ctx, frame); if (err == -11) return; // EAGAIN if (err < 0) { Releases(); return; // 同上,一般這裏很少出錯,但一旦發生,只能推倒從來 } // 嘗試播放一幀畫面 AVFrame s_frame = *frame; // 這裏由於我無論如何都要加速,而一般顯卡最兼容的是yv12格式,因此我只對dxva2和420p做了處理,如果你的h264解出來不是這些,我建議轉成rgb(那你就需要編譯和使用swscale模塊了) if (s_frame.format != AVPixelFormat.AV_PIX_FMT_DXVA2_VLD && s_frame.format != AVPixelFormat.AV_PIX_FMT_YUV420P && s_frame.format != AVPixelFormat.AV_PIX_FMT_YUVJ420P) return; try { int width = s_frame.width; int height = s_frame.height; if (lastIWidth != width || lastIHeight != height || lastFmt != s_frame.format) // 這個if判定的是第一次嘗試渲染,因為一般碼流的寬高和格式不會變 { if (s_frame.format != AVPixelFormat.AV_PIX_FMT_DXVA2_VLD) { // 假如硬解不成功(例如h264是baseline的,ffmpeg新版不支持baseline的dxva2硬解) // 我們就嘗試用directx渲染yuv,至少省去yuv轉rgb,可以略微節省一丟丟cpu PresentParameters pp = new PresentParameters(); pp.Windowed = true; pp.SwapEffect = SwapEffect.Discard; pp.BackBufferCount = 0; pp.DeviceWindowHandle = contentPanelHandle; pp.BackBufferFormat = Manager.Adapters.Default.CurrentDisplayMode.Format; pp.EnableAutoDepthStencil = false; pp.PresentFlag = PresentFlag.Video; pp.FullScreenRefreshRateInHz = 0;//D3DPRESENT_RATE_DEFAULT pp.PresentationInterval = 0;//D3DPRESENT_INTERVAL_DEFAULT Caps caps = Manager.GetDeviceCaps(Manager.Adapters.Default.Adapter, DeviceType.Hardware); CreateFlags behaviorFlas = CreateFlags.MultiThreaded | CreateFlags.FpuPreserve; if (caps.DeviceCaps.SupportsHardwareTransformAndLight) { behaviorFlas |= CreateFlags.HardwareVertexProcessing; } else { behaviorFlas |= CreateFlags.SoftwareVertexProcessing; } device = new Device(Manager.Adapters.Default.Adapter, DeviceType.Hardware, contentPanelHandle, behaviorFlas, pp); //(Format)842094158;//nv12 surface = device.CreateOffscreenPlainSurface(width, height, (Format)842094169, Pool.Default);//yv12,顯卡兼容性最好的格式 } lastIWidth = width; lastIHeight = height; lastVRect = new Rectangle(0, 0, lastIWidth, lastIHeight); lastFmt = s_frame.format; } if (lastFmt != AVPixelFormat.AV_PIX_FMT_DXVA2_VLD) { // 如果硬解失敗,我們還需要把yuv拷貝到surface //ffmpeg沒有yv12,只有i420,而一般顯卡又支持的是yv12,因此下文中uv分量是反向的 int stride; var gs = surface.LockRectangle(LockFlags.DoNotWait, out stride); if (gs == null) return; for (int i = 0; i < lastIHeight; i++) { memcpy(gs.InternalData + i * stride, s_frame.data1 + i * s_frame.linesize1, lastIWidth); } for (int i = 0; i < lastIHeight / 2; i++) { memcpy(gs.InternalData + stride * lastIHeight + i * stride / 2, s_frame.data3 + i * s_frame.linesize3, lastIWidth / 2); } for (int i = 0; i < lastIHeight / 2; i++) { memcpy(gs.InternalData + stride * lastIHeight + stride * lastIHeight / 4 + i * stride / 2, s_frame.data2 + i * s_frame.linesize2, lastIWidth / 2); } surface.UnlockRectangle(); } // 下面的代碼開始燒腦了,如果是dxva2硬解出來的圖像數據,則圖像數據本身就是一個surface,並且它就綁定了device // 因此我們可以直接用它,如果是x264軟解出來的yuv,則我們需要用上文創建的device和surface搞事情 Surface _surface = lastFmt == AVPixelFormat.AV_PIX_FMT_DXVA2_VLD ? new Surface(s_frame.data4) : surface; if (lastFmt == AVPixelFormat.AV_PIX_FMT_DXVA2_VLD) GC.SuppressFinalize(_surface);// 這一句代碼是點睛之筆,如果不加,程序一會兒就崩潰了,熟悉GC和DX的童鞋估計一下就能看出門道;整篇代碼,就這句折騰了我好幾天,其他都好說 Device _device = lastFmt == AVPixelFormat.AV_PIX_FMT_DXVA2_VLD ? _surface.Device : device; _device.Clear(ClearFlags.Target, Color.Black, 1, 0); _device.BeginScene(); Surface backBuffer = _device.GetBackBuffer(0, 0, BackBufferType.Mono); _device.StretchRectangle(_surface, lastVRect, backBuffer, lastCBounds, TextureFilter.Linear); _device.EndScene(); _device.Present(); backBuffer.Dispose(); } catch (DirectXException ex) { StringBuilder msg = new StringBuilder(); msg.Append("*************************************** \n"); msg.AppendFormat(" 異常發生時間: {0} \n", DateTime.Now); msg.AppendFormat(" 導致當前異常的 Exception 實例: {0} \n", ex.InnerException); msg.AppendFormat(" 導致異常的應用程序或對象的名稱: {0} \n", ex.Source); msg.AppendFormat(" 引發異常的方法: {0} \n", ex.TargetSite); msg.AppendFormat(" 異常堆棧信息: {0} \n", ex.StackTrace); msg.AppendFormat(" 異常消息: {0} \n", ex.Message); msg.Append("***************************************"); Console.WriteLine(msg); Releases(); return; } goto receive_frame; // 嘗試解出第二幅畫面(實際上不行,因為我們約定了單次傳入nal是一個,當然,代碼是可以改的) } } // 外部調用停止解碼以显示釋放資源 public void Stop() { Releases(); } }}
下面講解代碼最主要的三個部分
- 初始化ffmpeg
主要在靜態塊和構造函數中,過程中我沒有將AVPacket和AVFrame局部化,很多網上的代碼包括官方代碼都是局部化這兩個對象。我對此持保留意見(等我程序報錯了再說) - 將收到的數據送入ffmpeg解碼並將拿到的數據進行展示
這裏值得一提的是get_format,官方有一個示例,下圖
它有一個get_format過程(詳見215行和63行),我沒有採用。這裏給大家解釋一下原因:
這個get_format的作用是ffmpeg給你提供了多個解碼器讓你來選一個,而且它內部有一個機制,如果你第一次選的解碼器不生效(初始化錯誤等),它會調用get_format第二次(第三次。。。)讓你再選一個,而我們首先認定了要用dxva2的硬件解碼器,其次,如果dxva2初始化錯誤,ffmpeg內部會自動降級為內置264軟解,因此我們無需多此一舉。
- 發現解碼和播放過程中出現異常的解決辦法
- 不支持硬解
代碼中已經做出了一部分兼容,因為baseline的判定必須解出sps/pps才能知道,因此這個錯誤可能會延遲爆出(不過不用擔心,如果此時報錯,ffmpeg會自動降級為軟解) - 窗體大小改變
基於DirectX中設備後台緩衝的寬高無法動態重設,我們只能在控件大小改變時推倒重來。如若不然,你繪製的畫面會進行意向不到的縮放 - 網絡掉包導致硬件解碼器錯誤
見代碼 - 其他directx底層異常
代碼中我加了一個try-catch,捕獲的異常類型是DirectXException,在c/c++中,我們一般是調用完函數後會得到一個HRESULT,並通過FAILED宏判定他,而這個步驟在c#自動幫我們做了,取而代之的是一個throw DirectXException過程,我們通過try-catch進行可能的異常處理(實際上還是推倒重來)
- 不支持硬解
番外篇:C#對DiretX調用的封裝
上文中我們使用DirectX的方式看起來即非COM組件,又非C-DLL的P/Invoke,難道DirectX真有託管代碼?
答案是否定的,C#的dll當然也是調用系統的d3d9.dll。不過我們有必要一探究竟,因為這裏面有一個隱藏副本
首先請大家準備好ildasm和visual studio,我們打開visual studio,創建一個c++工程(類型隨意),然後新建一個cpp文件,然後填入下面的代碼
如果你能執行,你會發現輸出是136(0x88);然後我們使用ildasm找到StrechRectangle的代碼
你會發現也有一個+0x88的過程,那麼其實道理就很容易懂了,c#通過calli(CLR指令)可以執行內存call,而得益於微軟com組件的函數表偏移量約定,我們可以通過頭文件知道函數對於對象指針的偏移(其實就是一個簡單的ThisCall)。具體細節大家查閱d3d9.h和calli的網絡文章即可。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象





