1、背景
日誌系統接入的日誌種類多、格式複雜多樣,主流的有以下幾種日誌:
- filebeat採集到的文本日誌,格式多樣
- winbeat採集到的操作系統日誌
- 設備上報到logstash的syslog日誌
- 接入到kafka的業務日誌
以上通過各種渠道接入的日誌,存在2個主要的問題:
- 格式不統一、不規範、標準化不夠
- 如何從各類日誌中提取出用戶關心的指標,挖掘更多的業務價值
為了解決上面2個問題,我們基於flink和drools規則引擎做了實時的日誌處理服務。
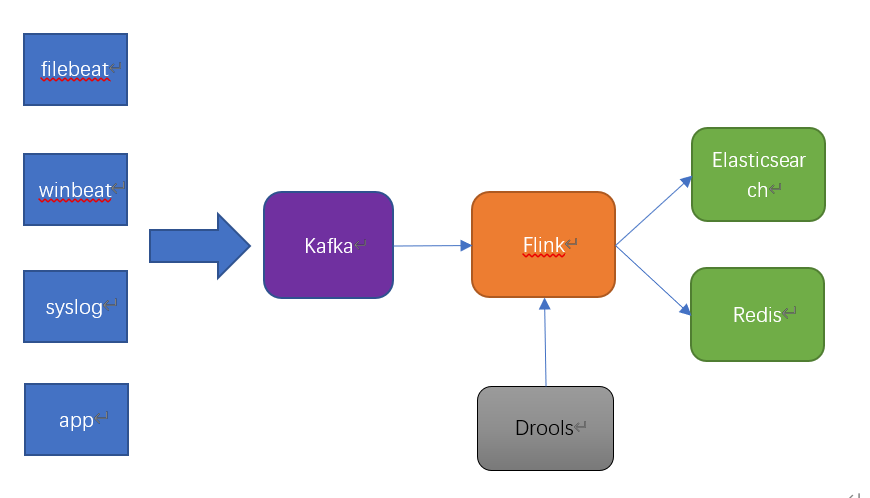
2、系統架構
架構比較簡單,架構圖如下:
各類日誌都是通過kafka匯總,做日誌中轉。
flink消費kafka的數據,同時通過API調用拉取drools規則引擎,對日誌做解析處理后,將解析后的數據存儲到Elasticsearch中,用於日誌的搜索和分析等業務。
為了監控日誌解析的實時狀態,flink會將日誌處理的統計數據,如每分鐘處理的日誌量,每種日誌從各個機器IP來的日誌量寫到Redis中,用於監控統計。
3、模塊介紹
系統項目命名為eagle。
eagle-api:基於springboot,作為drools規則引擎的寫入和讀取API服務。
eagle-common:通用類模塊。
eagle-log:基於flink的日誌處理服務。
重點講一下eagle-log:
對接kafka、ES和Redis
對接kafka和ES都比較簡單,用的官方的connector(flink-connector-kafka-0.10和flink-connector-elasticsearch6),詳見代碼。
對接Redis,最開始用的是org.apache.bahir提供的redis connector,後來發現靈活度不夠,就使用了Jedis。
在將統計數據寫入redis的時候,最開始用的keyby分組后緩存了分組數據,在sink中做統計處理后寫入,參考代碼如下:
String name = "redis-agg-log"; DataStream<Tuple2<String, List<LogEntry>>> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex()) .timeWindow(Time.seconds(windowTime)).trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime)) .process(new ProcessWindowFunction<LogEntry, Tuple2<String, List<LogEntry>>, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<LogEntry> iterable, Collector<Tuple2<String, List<LogEntry>>> collector) { ArrayList<LogEntry> logs = Lists.newArrayList(iterable); if (logs.size() > 0) { collector.collect(new Tuple2(s, logs)); } } }).setParallelism(redisSinkParallelism).name(name).uid(name);
後來發現這樣做對內存消耗比較大,其實不需要緩存整個分組的原始數據,只需要一個統計數據就OK了,優化后:
String name = "redis-agg-log"; DataStream<LogStatWindowResult> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex()) .timeWindow(Time.seconds(windowTime)) .trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime)) .aggregate(new LogStatAggregateFunction(), new LogStatWindowFunction()) .setParallelism(redisSinkParallelism).name(name).uid(name);
這裏使用了flink的聚合函數和Accumulator,通過flink的agg操作做統計,減輕了內存消耗的壓力。
使用broadcast廣播drools規則引擎
1、drools規則流通過broadcast map state廣播出去。
2、kafka的數據流connect規則流處理日誌。
//廣播規則流 env.addSource(new RuleSourceFunction(ruleUrl)).name(ruleName).uid(ruleName).setParallelism(1) .broadcast(ruleStateDescriptor); //kafka數據流 FlinkKafkaConsumer010<LogEntry> source = new FlinkKafkaConsumer010<>(kafkaTopic, new LogSchema(), properties);
env.addSource(source).name(kafkaTopic).uid(kafkaTopic).setParallelism(kafkaParallelism); //數據流connect規則流處理日誌 BroadcastConnectedStream<LogEntry, RuleBase> connectedStreams = dataSource.connect(ruleSource); connectedStreams.process(new LogProcessFunction(ruleStateDescriptor, ruleBase)).setParallelism(processParallelism).name(name).uid(name);
具體細節參考開源代碼。
4、小結
本系統提供了一個基於flink的實時數據處理參考,對接了kafka、redis和elasticsearch,通過可配置的drools規則引擎,將數據處理邏輯配置化和動態化。
對於處理后的數據,也可以對接到其他sink,為其他各類業務平台提供數據的解析、清洗和標準化服務。
項目地址:
https://github.com/luxiaoxun/eagle
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!