背景
之前做過一個項目,數據庫存儲採用的是mysql。當時面臨着業務指數級的增長,存儲容量不足。當時採用的措施是
1>短期解決容量的問題
mysql從5.6升級5.7,因為數據核心且重要,數據庫主從同步採用的是全同步, 利用5.7并行複製新特性,減少了主從同步的延遲,提高了吞吐量。
當時業務量高峰是2000TPS,5.6時可承受的最大TPS是3000,升級到5.7壓測可承受的最大TPD是5000.
2>流量拆分,從根本上解決容量問題
首先進行容量評估,通過對於業務開展規劃、活動預估,年底的容量會翻5倍。由於目前指數級增長的特性,數據庫要預留至少4倍的冗餘。
要對數據庫進行擴容,因為我們已經使用的是最頂配的SSD物理機了,就算可以在linux內核層面對numa進行綁核和非綁核等測試調參優化性能,提升容量也很有限。注意:一般的業務系統numa綁核會提高性能,但是mysql等數據庫系統是相反的。
所以垂直擴容不成功,就看看是否可以拆分流量。mysql流量拆分方式有x軸拆分(水平拆分)、y軸拆分(垂直拆分)、z軸拆分。
其中y軸拆分(垂直拆分)就是目前都在說做垂直領域,就是在一個細分領域里做深入的意思。由此可以很容易的記住垂直拆分的意思就是按照業務領域進行拆分,專庫專用。實際上能按領域拆分是最理想的,因為這種拆分業務清晰;拆分規則明確;系統之間整合或擴展容易。但是因為當時的業務已經很簡單,y軸拆分已經沒有什麼空間,這種拆分不能達到擴容20倍的目的。
z軸拆分近幾年沒有聽說過了,實際上大家也一直在用。這種方式是將一張大表拆分為子母表,就是分為概要信息和詳細信息。這種拆分方式對解決容量問題意義不大。
比較可行的一個方案是水平拆分。就是常說的分庫分表。按照容量評估,數據庫水平拆分一拆十,根據業務特點找一個標準字段來進行取模。
水平拆分一個技術點在於新老切換。
採用的是數據庫雙寫的方式,採用異步確保性的補償型事務,發送實時和延遲兩個MQ,通過開關來控制以老數據為準還是新數據庫為準。開始時以老數據庫為準,觀察新老數據沒有一致性問題之後,在一個低峰期,關閉了系統入口,等數據庫沒有任何變更之後切換開關,再打開系統入口。
問題
對於容量問題,上面採用的是一次性拆分到位的方法。對於一個規模稍大的公司來講,10組物理機(1組包含1主N從)的成本還好。
1>如果量級再次升級,需要每周增加10台數據庫才能支撐容量呢?
2>並且對系統可用性還有強要求,1s的停機都不可以接受呢?
解決方案分析
垂直流量拆分
首先我要分析的是每周增加10台數據庫這個容量是不是合理的。是否存在放大效應或者說可以減少對mysql這種昂貴資源的使用,轉為增加對HBase、Elasticsearch這種低成本高擴展性資源的使用呢?
基於這個思路,我們需要梳理下是否有可垂直拆分的流量。比如正向流量和負向流量。所謂正向流量是指比如交易下單,負向流量就是取消訂單,包括已付款取消、未付款取消、已到貨取消、未到貨取消等等。實際上負向流量在總訂單里佔比很少,但是業務要比正向交易業務複雜。將正向和逆向拆分的一個主要優勢是分治思想,可以降低兩部分各自的複雜度。將流量拆分重心轉移到正向流量上。
對於正向流量,一個業務比較常用的流量拆分思路是CQRS命令查詢分離,也就是常說的讀寫分離。如果讀流量大於寫流量。可以考慮能否將讀流量進一步拆分。拆分成實時和離線,將實時性要求不高的查詢走ES。ES的數據可以通過同步binlog變更獲得。
另外一個思路是將數據庫按照歷史數據來拆分。就是數據庫里只保存一定時間內的實時數據。超過指定時間則進行數據歸檔。將數據歸檔到HBase等,一般對於歷史的查詢實時性要求也不是很高。
垂直流量拆分可能遇到的問題
以上方法都是只考慮問題1如果量級再次升級,需要每周增加10台數據庫才能支撐容量的方案。如果再考慮問題2並且對系統可用性還有強要求,1s的停機都不可以接受。就需要看上述方案可能會遇到的問題。
拆分正向流量和負向流量、CQRS都需要改造,改造過程就需要過渡。過渡可以採用上面說的雙寫方式,觀察運行情況進行切換。切換過程中也可以不關閉流量。
麻煩的是數據歸檔。因為數據歸檔后刪除數據庫的數據,變更生效時,針對innodb來說,意味着數據結構重建,頻繁IO。這會影響OLTP在線事務的處理。可以考慮按表來歸檔,控制操作頻率,控制單位時間內對IO的影響。
分佈式關係型數據庫
分佈式關係型數據庫本質上是通過增加代理等方式將分庫分表做的更加隱蔽。
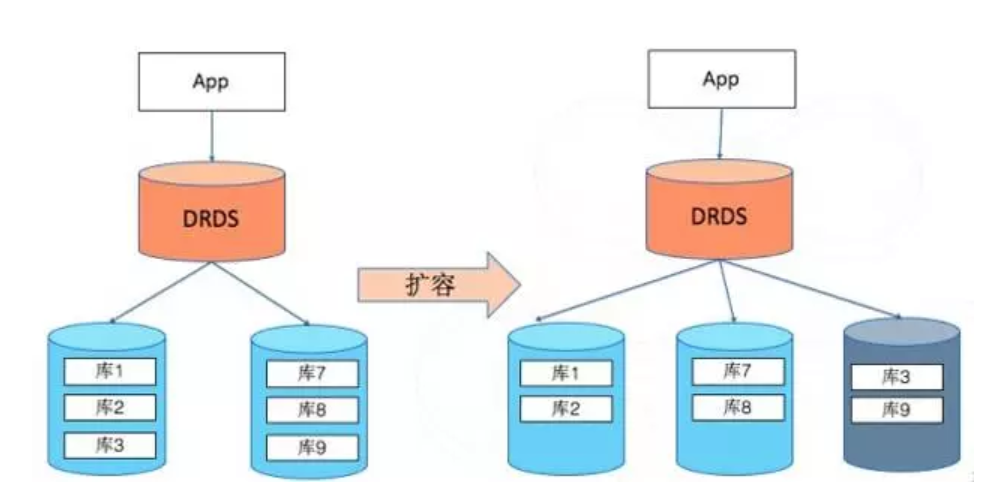
阿里巴巴分佈式關係數據庫(DRDS),前身是淘寶分佈式數據層(TDDL),核心就是用於分庫分表管理的代理層,宣稱可實現平滑擴容。
擴容過程實際是物理數據遷移的過程,引擎層按照分庫遷移后的邏輯先在物理節點上建立新的分庫,然後保留一個時間點進行全量的數據遷移。完成全量遷移后,開始基於先前保留的時間點進行增量的數據追趕。當增量數據追趕到兩邊的數據幾乎一致時,對數據庫進行瞬時停寫,將最後的數據追平,引擎層進行分庫邏輯的路由切換,路由規則切換完成后就完成了核心的擴容邏輯,整個切換過程在毫秒級別完成。
因為整個過程是毫秒級,所以可以做到業務層沒有感知,等多就是看到擴容過程中請求延時增加了不到1s。從原理上來說是可行的。
NOSQL解決方案
像這麼大的數據量一個很好的參考是12306。12306採用的是Geode。它是有數據庫功能的內存數據網格(In-Memory Data Grid,IMDG)。其重要特性是
1)集群內存總容量,現在Geode可以實現單個節點200-300GB內存,總集群包含300個節點的大型集群,因此總容量可以達到90TB左右的級別。
2)Geode集群功能非常強大,實現了內存中數據Shard分佈,自動管理,集群故障自動恢復,自動平均分佈等一系列企業級的功能,而且有自帶的集群間數據同步功能。
3)在CAP原理下(不了解的話可以百度一下CAP不可能三角),Geode可以保證集群內數據的強一致性,注意是真正的強一致性而不是最終一致性,再加上分區可用性,因此是一個CP型的產品,可以提供統一的數據視圖,支持高併發下的acid事務。
採用新的解決方案最大問題是平滑過渡,平滑過渡方面我還是覺得上面提到的數據庫雙寫方式安全可靠。
系統共建的解決方案
如果達到我所說的量級,基本上在一個行業中是處於垄斷地位的。並不是一家純的互聯網公司。這種公司可以採用和互聯網大廠合作的方式、用已經有這方面經驗的大廠,來根據自己內部系統的特性共建一套合適自己的定製化數據庫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心