1. 信息的存儲
大多數計算機使用 8 位的塊,或者字節,作為最小的尋址內存單位,而非訪問內存中單獨的位,機器級程序將內存視為一個非常大的字節數組,稱為 虛擬內存 ,內存的每個字節都用一個唯一的数字標識,稱為它的 地址 。以 C 語言的指針為例,指針使用時指向某一個存儲塊的首字節的 虛擬地址 ,C 編譯器將指針和其類型信息結合起來,這樣即可以根據指針的類型,生成不同的機器級代碼來訪問存儲在指針所指向位置處的值。每個程序對象可以簡單視為一個字節塊,而程序本身就是一個字節序列。
1.1 十六進製表示法
一個字節由 8 位組成。用二進製表示即 00000000 ~ 11111111 。十進製表示為 0 ~ 255 。由於兩者表示要麼過於冗餘,要麼轉換不遍,因此通常使用十六進制來表示一個字節。這幾種進制的轉換在此就不多說了。
1.2 字數據大小
每台計算機都會有一個字長(此處字長非字節長度),指明 指針數據的標稱大小(nominal size),因為虛擬地址是以這樣的一個字來進行編碼的,所以字長決定的最重要的一個系統參數即是虛擬地址空間的最大大小。 對於一個字長為 w 位的機器而言,虛擬地址的範圍為 0 ~ (2 ^w )- 1 ,程序最多訪問 2 ^ w 個字節。以 32 位機器為例,32位字長限制虛擬地址空間為 (2 ^32) -1 ,程序最多訪問 2 ^ 32 個字節,大約為 4 x 10^9 字節,即4 GB ( 根據 2 ^ 10 (1024) 約等於 10 ^ 3 (1000) ,可以得到 2 ^ 32 = 4 * 2^30 = 4 * 10 ^ 9 ) 。64位機器的限制虛擬地址空間為 16 EB。大約為 1.84 x 10 ^9 。
1.3 尋址和字節順序
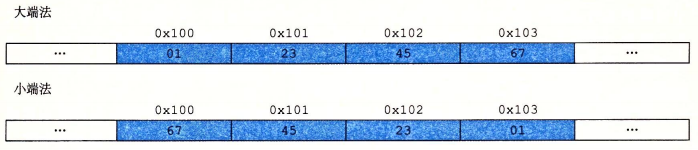
對於跨越多個字節的對象,我們必須建立兩個規則:這個對象的地址是什麼以及在內存中如何排列這些字節。在幾乎所有的機器上,多字節對象都被存儲為連續的字節序列,對象的地址為這個字節序列中最小的字節地址。以 int 類型為例,假定int 大小為32 位,有變量 int x = 0x01234567 。若 x 的地址為 0x100 ,則 x 的 4 個字節將被存儲在 0x100 , 0x101 , 0x102, 0x103 的位置,此時 4個字節的值分別為 0x01, 0x23, 0x45, 0x67,那麼在內存中的排列順序有如下兩種情況,
- 大端法:最高有效字節放在最前面的方式稱為大端法,即將一個数字的最高位字節放在最小的字節地址。
- 小端法:最低有效字節放在最前面的方式稱為小端法,即將一個数字的最低位字節放在最小的字節地址。
以上面的 x 為例,x 的最高位字節是 0x01 ,將其放在最小的字節地址即 0x100。x 的最低位字節為 0x67 ,將其放在最小的字節地址 0x100 。即大小端對應高低位字節。對於我們來說,機器的字節順序是完全不可見的,我們大部分情況下也無需關心其字節順序,但是在不同類型的機器之間通過網絡傳遞二進制數據的時候,如小端法機器傳送數據給大端法機器時,接受方接收到的字節序會變成反序,為了避免這種問題的產生,發送方和接收方都需要遵循一個網絡規則,發送方將二進制數據轉換成網絡標準,接收方再將這個網絡標準的字節序轉換成自己的字節序。此外,我們在閱讀機器級代碼的時候,可能會出現如下的情況:
暫時忽略這條指令的意義,可以看到左邊6個字節分別為 01 05 43 0b 20 00 ,而右邊的指令中的地址為 0x200b43,可以看到從左邊的第三個字節開始,43 0b 20 是右邊指令地址的倒序,因此在閱讀這種機器級代碼的時候,也需要注意字節序的問題。此外還存在一種情況。如下圖所示。
我們可以看到, show_bytes 這個函數可以打印出 start 指針指向的地址開始的 len 個字節內容,且不受字節序的影響,那麼它是如何做到的呢?在 show_int 函數中,可以看到它將 參數 x 的地址強制類型轉換為了 byte_pointer , 即 unsigned char * 。通過強制類型轉換的 start 指針指向的仍是 x 的最低字節地址,但是其類型改變了,通過其類型編譯器會認為該指針指向的對象大小為 1 個字節,此時將該指針進行 ++ 操作可以得到順延下一個字節的內容,從而得到對應的整個對象的字節序列中每個字節的內容而不受字節序影響。
1.4 字符串
在C語言中,字符串被編碼為一個以 null (其值為0 )字符結尾的字符數組。每個字符都有某個標準編碼來表示,最常見的則是 ASCII 字符碼。假如我們調用 show_bytes(“12345”, 6),那麼會輸出 31 32 33 34 35 00 。可以看到最後打印出了一個終止符,所以通常 C 字符串的長度為實際字符串長度 + 1。 在C 標準庫中的 strlen 函數可以傳入一個字符串得出其長度,這裏的長度即是實際長度,不包含終止符。
2. 整數表示
在本章節中,介紹了編碼整數的兩種不同的方式,一種只能表示非負數,另一種則能夠表示負數,正數和零。接下來逐一進行介紹。
2.1 整型數據類型
C語言中,整數有多種數據類型,如下圖所示,此外可以通過加上 unsigned 符號來限定該數據類型為非負數。這些數據類型有的是根據機器的字長(32位和64位)決定其實際最大值和最小值的範圍。我們可以看到,圖中最小值和最大值的取值範圍是不對稱的,負數的取值範圍比正數大一,當我們考慮如何表現負數時,會看到為什麼會這樣。
關於無符號整數的編碼,其實與普通的十進制正數轉換成二進制沒有什麼區別,假設字長 w = 32 位,轉換后大於 32 位的数字將被捨去。這裏主要介紹一下關於有符號数字的編碼,通常計算機使用的編碼錶示方式為 補碼 ,在這個表示方式中,將字的最高有效位(即符號位)表示為負權,權重為 – 2^(w-1) ,當 w 位的值為 1 時表示為負數,反之為正數。以 -1 為例,-1 的補碼為1111 1111 …. …. 1111 ,即 -2^31 + 2^30 + … + 2^0 = -1 ,通常我們看到一個負數想要直接將其使用補碼錶示還是有些不方便的,因此我們可以先使用原碼錶示,所謂原碼和普通的十進制數轉二進制數沒有區別,只不過最高位用來表示符號位,然後再求其反碼,即符號位不變,其餘位取反加 1,就可以得到這個負數的補碼了,還是以 -1 舉例, -1 的原碼為 1000 0000 …. 0001 ,其反碼的值為 1111 1111 …. 1111 ,與 -1 的補碼值是相同的。而正數的補碼為其本身,不需要做這種轉換。
那麼為什麼要使用補碼這種表示方式呢,首先,二進制補碼可以使正負數相加時仍然採用正常加法的邏輯,不需要做特殊的處理,此外,如果不採用補碼錶示,採用原碼的表示方法,那麼會出現幾個問題,正負零的存在,以及提高了減法的計算複雜度,而補碼可以十分簡單的計算正負數相加,只需求出兩者的補碼對其進行加法,更多關於補碼的解釋可以參考 。
PS: 為什麼正負數補碼相加會得到正確的結果,這裏個人的見解是:由於補碼最高位為負權,而正數與負數補碼相加相當於正數去抵消這個負權。比如 -16 的補碼為 1111 …. 1111 0000,加上正數 1,由於正數的補碼為本身,所以等價於 -16 + 1 == (-2^31 + 2^30 + … + 2^4 ) + 2^ 0 ,相當於多了一個 2^0 的正權去抵消其最高位的負權。
2.2 有符號數和無符號數之間的轉換
C語言允許各種不同的数字類型之間進行強制類型轉換, 如 int x= -1 ; unsigned y = (unsigned) x ; 此時會將 x 的值強制類型轉換成 unsigned 類型然後賦值給 y ,那麼此時 y 的值是多少呢?可以通過打印兩者的十六進制值來看有什麼區別。下面為 test.c 的代碼:
int main()
{
int x = -1;
unsigned y = (unsigned) x;
printf(“%x \n”, x);
printf(“%x \n”, x);
return 0;
}
此處為編譯后可執行文件的輸出結果:
ffffffff
ffffffff
可以看到, x 和 y 的十六進制值是相同的,這也說明了,強制類型轉換並不會改變數據底層的位表示,只是改變了解釋位模式的方式。我們可以利用 printf 的指示符進一步驗證這個結果,使用 %d (有符號十進制), %u (無符號十進制), 來打印 x 和 y 的值。以下是代碼:
int main()
{
int x = 1;
unsigned y = (unsigned) x;
printf(“x format d = %d , format u = %u \n”, x, x);
printf(“y format d = %d , format u = %u \n”, y, y);
return 0;
}
這是編譯后可執行文件的對應輸出:
x format d = -1 , format u = 4294967295
y format d = -1 , format u = 4294967295
我們可以看到,我們使用指示符控制了解釋這些位的方式,得到的結果是一致的。
2.3 整數運算
關於整數的運算,主要就是加減乘除四種運算,補碼的加減乘除都比較簡單明了,這裏主要說一下除法的舍入問題,首先,我們先確認下 C 語言中的舍入方式,在 C 語言中,浮點數被賦值給整數時,小數位總是被捨去,如
float f = 1.5;
int x = f ;
printf(“%d \n “, x);
輸出的結果為:
1
當 f 為負數時結果又是如何呢 ?
float f = -1.5 ;
int x = f;
printf(“%d \n”, x);
輸出的結果為:
-1
因此我們可以認為,C語言的舍入方式為向零舍入。接下來看一下除法的舍入問題。此處先以除以 2 的冪的無符號除法為例,
上圖表示 12340 / 2^k 的時候二進制與對應的十進制的表示,此時的舍入是完全沒有問題的。接下來看下除以 2 的冪的有符號除法。
當k = 4 的時候,-12340 / 2^ 4 == -771.25,此時的正確舍入值應該為 -771,但是其卻舍入成了 -772。這是因為,如果我們單純使用右移來進行除法的時候,其舍入方式為向下舍入,即總是往更小值的方向舍入,在沒有小數位的情況下是正確的,但是如果有小數位的時候,如 -771.25 舍入為 -772, 771.25 舍入為 771。而C語言的舍入方式為向零舍入,即總是往靠近零的值舍入,如 771.25 舍入為 771, -771.25 舍入為 -771。那麼如何實現這種舍入方式呢。當被除數為負數時,我們可以通過加上一個偏置值來糾正這種不正確的舍入方式。
我們可以觀察一下上圖的有符號除法例子,可以發現,當右移的 k 位單獨拿出來,不為 0 的時候,會導致舍入結果不正確,這是因為,k 位的值不為 0 的時候,表示該結果有小數,所以可以通過 (x + (1 << k) – 1) >> k 得到正確的結果, (1 << k) – 1 可以獲得 k 個 1,x 加上 k 個 1 可以使捨去的 k 位不為 0 時產生進位,x >> k 的結果加一,從而使舍入正確。
關於整數的表示和運算,個人覺得有幾個需要關注的點,一是溢出問題,由於使用有限的位來表示整數,所以當数字過大的時候可能會產生溢出,溢出的位會被捨去,但是有符號數的溢出可能會使符號位被置反,如 0111 1111 …. 1111 + 1 = 1000 0000 …. 0000,0111 1111 …. 1111 為 INT_MAX , INT_MAX + 1 會得到 INT_MIN。此外,無符號數與有符號數進行比較的時候,會使有符號數強制轉換為無符號數,如果有以下循環代碼:
for(size_t i = 10; i >= 0 ; i–);
由於 i 為無符號數,當 i == 0 的時候,判斷還會繼續循環下去, 0 – 1 = -1 , -1 的補碼錶示為 1111 1111 …. 1111 , 剛好是無符號數的最大值,會導致死循環。因此也需要注意一切與無符號類型數據的運算,以及強制類型轉換可能出現的問題。
3. 浮點數
終於來到了這一章的重點內容之一(其實感覺這本書哪裡都挺重要的),這裏主要介紹浮點數是如何表示的,並且介紹浮點數舍入的問題(和上面講到的舍入不大一樣),浮點數的表示及其運算標準稱為 IEEE754 標準,初看可能會讓你覺得有些晦澀難懂,但是理解之後會覺得設計的十分巧妙。
3.1 定點表示法
首先讓我們先看下十進制的浮點數是如何表示的,浮點數的定義與小數點息息相關,定義在小數點左邊的数字的權是 10 的正冪,右邊的数字為 10 的負冪,如 12.34 表示 1 * 10^ 1 + 2 * 10^0 + 3 * 10 ^-1 + 4 * 10 ^ -2 = 12又34/100,同理可以得到二進制的浮點數表示,即定義在小數點左邊的数字的權是 2 的正冪,右邊的数字為 2 的負冪,如 101.11 = 1 * 2^2 + 0 * 2^1 + 1 * 2^0 + 1 * 2^-1 + 1 * 2^-2 。這種浮點數的表示方法是有缺陷的,無法精準的表示特定的数字,以 1/5 為例,可以用 十進制数字 0.2 表示,但是我們無法用二進制數字錶示它,只能近似的表示它,通過增加二進製表示的長度可以提升表示的精度。如下圖所示。
3.2 IEEE754標準
在前面談到的定點表示法不能有效的表示一個比較大的数字,例如 5 x 2^100 是用 101 後面跟隨 100 個零的位模式,我們希望能夠通過給定 x 和 y 的值來表示如 x * 2 ^y 的数字。IEEE754 標準使用 V = ( – 1)^S * M * 2^E 的形式來表示一個數。
- 符號(Sign): S 決定這個數是負數(S = 1 )還是正數 (S = 0), 對於數值為 0 的符號位做特殊解釋。
- 尾數(Significand): M 是一個二進制小數,範圍為 1 ~ 2 – e , 或者是 0 ~ 1 – e 。
- 階碼(Exponent): E 的作用是對浮點數進行加權,這個權重是 2 的 E 次冪(E 可能為負數)。
通過將浮點數的位劃分為三個字段,分別對這些值進行編碼:
- 一個單獨的符號位 S 。
- k 位的階碼字段 ,exp = e(0) e(1) e(2) … e(k-1) ,exp 用來編碼階碼 E。
- n 位的小数字段 , frac = f(n-1) … f(1) f(0) ,frac 用來編碼尾數 M。
下圖是該標準下封裝到字中的兩種最常見的格式。
此外,根據階碼值(exp),被編碼的值可以分為下圖幾種情況(階碼值全為 0 ,階碼值全為 1 , 階碼值不全為 0 也不全為 1):
接下來對這幾種格式進行一一介紹~:
- 規格化浮點數 : 這是最普遍的情況,當 exp 的值不全為 0 也不全為 1 時,就屬於這種情況,這種情況下,階碼值 E = e – bias ,其中 e 為無符號數,即 exp 的值,而 bias 是一個 2^(k-1) – 1 的偏置值(單精度為 127,雙精度為 1023),而小数字段 frac 被解釋為描述小數值 f ,其中 0 <= f < 1,其二進製表示為 0.f(n-1)…f(1)f(0) 的数字,也就是二進制小數點在最高有效位的左邊的形式。尾數定義為 M = 1 + f 。 有時候這種方式也叫做 隱含 1 開頭的表示(implied leading 1),因為這種定義我們可以把 M 看成一個二進製表示為 1.f(n-1) … f(1)f(0) 的数字。既然我們總是能調整階碼 E ,使得尾數 M 在範圍 1 <= M < 2 之中(假設沒有溢出),那麼這樣可以節約一個位,因為第一位總是為 1 。
- 非規格化浮點數 : 當 exp 的值全為 0 的時候,所表示的浮點數為非規格化類型,E = 1 – bias ,而尾數的值為 M = f 。不含開頭的 1 。非規格化有兩種用途,首先它提供了表示 0 的方法,因為規格化數使得 M >= 1,所以不能表示 0 ,另外非規格化數另一個功能則是表示那些非常接近於 0.0 的數,他們提供了一種屬性,稱為逐漸溢出,其中,可能的數值均勻分佈接近於 0.0 。
- 特殊值 : 最後一類數值是指當階碼全為 1 的時候出現的。當小數域全為 0 時,表示為無窮大/小,當我們將兩個非常大的數相乘時,或者除以零時,無窮能夠表示溢出的結果。當小數域為非 0 時,結果為 NaN(Not a Number),一些運算的結果不能為實數或者無窮時,會返回 NaN,比如 根號 -1 ,或者 無窮減無窮。此外,在某些應用中也可以用來表示未初始化的數值。
首先,通過一個字長為 8 位的例子,來看一下IEEE754標準實際上使用時是如何表示的 :
上圖為展示了假定 w = 8 的字長,k = 4 的階碼位以及 n = 3 的小數位。偏移量為 2 ^ ( k -1 ) -1 = (2 ^ 3) – 1 = 7。圖中分別展示了非規格化數,規格化數以及特殊值是如何編碼的,以及如何結合在一起表示 V = (2^E) * M。我們可以看到,從最大非規格化數到最小規格化數,其值的轉變十分平滑,從 7/512 到 8/512 。這得益於非規格化數的 E 定義為 1 – bias ,最大的非規格化數的階碼值 E 與最小的規格化數的階碼值 E 是相等的,兩者唯一的區別在於 M 值,規格化數尾數 M = 1 + f ,而非規格化的尾數 M = f ,因為非規格化值是用於表示 [0, 1] 區間的小數的,當 f 達到最大值時, f 接近於 1 ,此時最大的非規格化數再進一位,小數 M 只能表示為 1 ,因為此時限制於 f 的位數,沒有比 f 大又比 1 小的小數值 ,進位後轉換成了規格化數,此時 f = 0 , 在階碼值 E 相等的情況下,讓規格化的 M = 1 + f 恰好可以使兩者進行平滑的轉換。
假如我們使非規格化數的 E = 0 – bias = -7 ,那麼會導致最大非規格化數和最小規格化數的粒度過大,兩者的值分別為 7/1024 和 8/512 。這種定義可以彌補非規格化數的尾數沒有隱含的 1 。通過上述的例子,我們可以發現 ,假如我們把上述的例子按無符號整數表示的話,會發現它的值是有序上升的,這不是偶然的,IEEE 格式如此設計就是為了浮點數能夠使用整數排序函數進行排序。
通過練習將整數值轉換為浮點數值形式對理解浮點數很有用,以 12345(十進制) 為例,其二進製表示為 1100 0000 1110 01 . 0 ,通過將小數點左移 13 位得到 1.1000000111001 * 2^13 ,我們丟棄開頭的 1 (這裏的 1 就是規格化數隱含的 1),構造小数字段,當 f 不足 23 位的時候,往後填充 0 ,即 M = 1 + f = 1 + 1000 0001 1100 1000 0000 000 ,當 f 大於 23 位的時候,f 多出的位會被捨棄(這裏可以看出浮點數的兩個性質,以 int 類型和 float 類型舉例,當 int 值 大於 2^24 的時候,int 轉換成 float 兩者很有可能值會不相等,因為多出的部分被捨棄了,二是 float 可以表示的數值遠遠大於 int 類型,V = (-1 ^ S) * M * 2^E ,E 最高可以等於 127 ,float 的最大值為 (2^127) * (1 + f),而 int 最大值為 (2^31) -1。
3.3 舍入
浮點數的舍入方式有四種,分別是向上舍入,向下舍入,向零舍入,向偶數舍入。下圖是幾種舍入方式的例子 :
偶數舍入是浮點數默認的舍入方式,可以看到,向偶數舍入時,當小數值為中間值時,會使最低有效数字總為偶數,如 2.5 和 1.5 都舍入為 2 。為什麼使用向偶數舍入呢,假設我們採用向上舍入,用這種方法舍入一組數值,會在計算這些值的平均值中引入統計偏差。我們採用這種方式舍入得到的平均值總是比這些數本身的平均值要略高一些,反之向下舍入亦然,向偶數舍入則可以使在 50% 的時間內向上舍入,50% 的時間內向下舍入。
4. 小結
- 計算機將信息編碼為位(bit),通常組織成字節序列,有不同的編碼方式來表示整數,實數和字符串。不同的計算機模型在編碼数字和多字節數據中的字節順序時使用不同的約定。
- 絕大部分機器使用補碼來編碼整數。對於浮點數使用 IEEE754 標準來編碼。
- 在進行對無符號和有符號整數進行強制類型轉換時,底層的位模式是不變的。(浮點數與整數轉換則會進行 改變,如 float f = 1.25; int x = f; 此時打印兩者的十六進制值,可以分別輸出為 f = 92463258 ,x = 1 )
- 由於編碼的長度有限,當超出表示範圍時,有限長度會引起數值溢出,如 x * x 可能會得到負數。當浮點數非常接近於 0.0 時,轉換成 0 時也會產生下溢。
- 使用補碼運算 ~x + 1 = -x (不適用於 INT_MIN) 。可以通過 (2^k) – 1 生成一個 k 位的掩碼。
- 浮點數不具備結合率,因為可能發生溢出或者舍入,從而失去精度。如(le20 * le20) * le-20 = 正無窮,而 le20 * (le20 * le-20) = le20 。此外也不具備分配性,如 le20 * (le20 – le20) = 0.0 ,而 le20 * le20 – le20 * le20 = NaN。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?