1.1 背景知識
1.1.1 紅黑樹
二叉查找樹可能因為多次插入新節點導致失去平衡,使得查找效率低,查找的複雜度甚至可能會出現線性的,為了解決因為新節點的插入而導致查找樹不平衡,此時就出現了紅黑樹。
紅黑樹它一種特殊的二叉查找樹。紅黑樹的每個節點上都有存儲位表示節點的顏色,可以是紅(Red)或黑(Black)。它具有以下特點:
(1)每個節點或者是黑色,或者是紅色。
(2)根節點是黑色。
(3)每個恭弘=叶 恭弘子節點(恭弘=叶 恭弘子節點,是指為空(NIL或NULL)的恭弘=叶 恭弘子節點)是黑色。
(4)如果一個節點是紅色的,則它的子節點一定是黑色(即從根節點到恭弘=叶 恭弘子節點的路徑上不能有兩個重複的紅色節點)。
(5)從一個節點到其上每一個恭弘=叶 恭弘節點的所有路徑都具有相同的黑色節點個數。
紅黑樹的基本操作–添加
① 將紅黑樹當作一顆二叉查找樹,將節點插入。
② 將插入的節點着色為”紅色”。(因為條件5,從一個節點到其中每一個節點的的所有路徑都具有相同的黑色節點)。
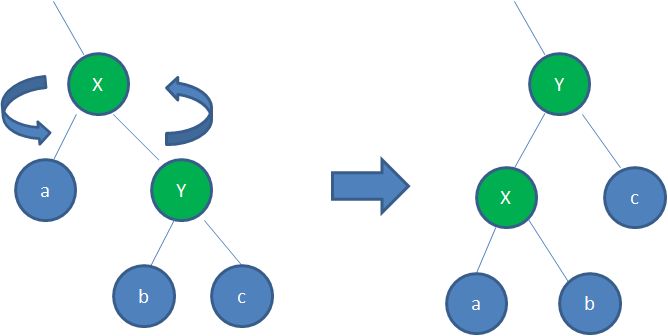
③通過一系列的旋轉(左旋或右旋操作)或着色等操作,使之重新成為一顆紅黑樹。
1.2 源碼
在java 1.7之前是用數組和鏈表一起組合構成HashMap,在java1.8之後就使用當鏈表長度超過8之後,就會將鏈錶轉化為紅黑樹,縮小查找的時間(紅黑樹維護也會花費大量時間,包含左旋、右旋和變色過程)。
1.2.1 HashMap的初始化
hashmap構造函數會初始化三個值:
- 初始容量initialCapacity:默認值是16,當儲存的數據越來越多的時候,就必須進行擴容操作。
- 閾值threshold:hashmap的數組結構中所能存放的最大數量,超過該數量,則會對數組進行擴容。閾值的計算方式為:容量(initialCapacity)*負載因子(loadFactor)。
- 負載因子loadFactor:當負載因子很大時,閾值會很大,table數組擴容的可能性比較小,會使得一個數組中的鏈表(紅黑樹)存放過多的數據,雖然節省了一定的空間,但會導致查詢時間很長。相反負載因子很小時,擴容的可能性會很高,使得數組中的數據變得相對少,查詢時間會縮短,但會花費較長的時間。
在初始化一個hashmap對象的時候,指定鍵值對的同時,也可以指定初始map的容量大小,假設此處我們指定大小為11,則會在構造函數中調用tableSizeFor將容量改為2的n冪次,即比當前容量大,而且必須是2的指數次冪的最小數,就會變成16。這是因為2的指數次冪便於計算進行位運算操作,提升運行效率問題(位運算>加法>乘法>除法>取模)。
hashmap的的默認值是16,負載因子默認是0.75,代碼如下:
//HashMap<String,String> hashMap = new HashMap<String, String>(11);
/**
* Returns a power of two size for the given target capacity.
**/
static final int tableSizeFor(int cap) {
int n = cap - 1; //10 防止在cap已經是2的n次冪的情況下
// >>> 表示不關心符號位,對數據的二進制形式進行右移 |表示或運算
n |= n >>> 1; //15
n |= n >>> 2; //15
n |= n >>> 4; //15
n |= n >>> 8; //15
n |= n >>> 16; //15
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; //16
}
1.2.2 HashMap的put操作
這裏可以介紹一下&位運算,當我們將一對KV存儲到hashmap當中時,會通過(n – 1) & hash運算來定位將要插入的鍵值對放入到哈希表的某個桶中。其中n表示哈希表的長度,通常n為2的倍數,通過n-1即可n所表示的二進制數,除最高位外,全部轉化為1,藉助與運算即可快速完成取模操作。
//hashMap.put("2020", "good luck");
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果hashtable沒有初始化,則初始化該table數組
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通過位運算找到數組中的下標位置,如果數組中對應下標為空,則可以直接存放下去
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//數組元素對應的位置已經有元素,產生碰撞
Node<K,V> e; K k;
//如果插入的元素key是已經存在的,則將新的value替換掉原來的舊值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果此時table數組對應的位置是紅黑樹結構,則將該節點插入紅黑樹中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果此時table數組對應的位置是鏈表結構
for (int binCount = 0; ; ++binCount) {
//遍歷到數組尾端,沒有與插入鍵值對相同的key,則將新的鍵值對插入鏈表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//鏈表過長,將鏈錶轉化為紅黑樹
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//發現鏈表中的某個節點有與插入鍵值對相同的key,則跳出循環,在循環外部重新賦值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//該key在hashmap已存在,更新與在鏈表跳出循環節點對應的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//超過閾值則更新
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
1.2.3 HashMap的get操作
/**
* Implements Map.get and related methods.
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//table數組不為空,且對應的下標位置也不為空。
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果第一個位置是對應的key,則返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//遍歷其他元素
if ((e = first.next) != null) {
//紅黑樹
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//鏈表
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
1.2.4 HashMap的擴容操作
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//table不為空,且容量大於0
if (oldCap > 0) {
//如果舊的容量到達閾值,則不再擴容,閾值直接設置為最大值
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果舊的容量沒有到達閾值,直接操作
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//閾值大於0,直接使用舊的閾值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//如果閾值為零,則使用默認的初始化值
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//更新數組桶
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//將之前舊數組桶的數據重新移到新數組桶中
if (oldTab != null) {
//依次遍歷舊table中每個數組桶的元素
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果數組桶中含有元素
if ((e = oldTab[j]) != null) {
//將下標數據清空
oldTab[j] = null;
//如果元組的某一桶中只有一個元素,則直接將該元素移到新的位置去
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果是紅黑樹結構
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//鏈表 -- 對舊桶里鏈表中的每一個元素重新計算哈希值得到下標
else { // preserve order
//將原先桶中的鏈表分為兩個鏈表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/*
* e.hash & oldCap 對hash取模運算,
* 雖然數組大小擴大了一倍,
* 但是同一個key在新舊table中對應的index卻存在一定聯繫:
* 要麼一致,要麼相差一個 oldCap。
*/
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
此處在處理鏈表的時候,如何將鏈表中的節點重新分配到新的哈希表需要做一些解釋。在擴容的時候,將原來的哈希表擴大了一倍,原來屬於同一個桶中的數據會被重新分配,此時取模運算時(a mod b),會注意到,b會擴大兩倍(a mod 2b),此時如果該桶中的某一個數據的哈希值是c1(0<c<b),則它必定還是會落入原來的位置,而如果桶中的某一個數據的哈希值是c2(b<c2<2b),則它會被重新分配到一個新的位置(這個位置是原先的哈希桶位置+舊桶的大小)。
HashMap在多線程的情況下出現的死循環現象
在某些java版本中擴容機制如果使用鏈表,且再插入時使用尾插法會出現死循環,具體原因可以參考老生常談,HashMap的死循環,在本文中所參考的java版本使用了頭插法的方式將元素添加到鏈表當中,可以避免死循環的出現,但是會出現一部分節點丟失的問題。如圖:
假設原始的哈希map的某個桶的數據如下,此時線程開始擴容,將桶中的數據分配到lo和hi桶的鏈表中。
初始時刻線程1和線程2開始運行,線程1在執行完以下代碼后,線程1的時間片運行結束。線程1運行的結果如圖所示
線程2與線程1同時運行,線程2的時間片未用完,還在繼續執行,根據代碼的分配策略,線程2直到時間片運行結束,出現如圖所示的結果:
此時CPU的時間片又被分配到了線程1,線程1繼續運行,因為此時A所在的鏈表結構已經發生了變化,只能處理A,B,D三個元素。此時線程1創建的hashmap如圖:
參考資料
教你初步了解紅黑樹
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!