1. Overview
Adaptive softmax算法在鏈接1中的論文中提出,該算法目的是為了提高softmax函數的運算效率,適用於一些具有非常大詞彙量的神經網絡。
在NLP的大部分任務中,都會用到softmax,但是對於詞彙量非常大的任務,每次進行完全的softmax會有非常大的計算量,很耗時(每次預測一個token都需要O(|V|)的時間複雜度)。
所以paper中提出adaptive softmax來提升softmax的運算效率。
1) 該算法的提出利用到了單詞分佈不均衡的特點(unbalanced word distribution)來形成clusters, 這樣在計算softmax時可以避免對詞彙量大小的線性依賴關係,降低計算時間;
2) 另外通過結合現代架構和矩陣乘積操作的特點,通過使其更適合GPU單元的方式進一步加速計算。
2. Introduction
2.1 一般降低softmax計算複雜度的兩種方式
1) 考慮原始分佈:近似原始概率分佈或近似原始概率分佈的子集
2) 構造近似模型,但是產生準確的概率分佈。比如:hierarchical softmax.
(上述兩個方法可以大致區分為:一是準確的模型產生近似概率分佈,二是用近似模型產生準確的概率分佈)
2.2 本文貢獻點
paper中主要採用的上述(2)的方式,主要借鑒的是hierarchical softmax和一些變型。與以往工作的不同在於,本paper結合了GPU的特點進行了計算加速。主要
1. 定義了一種可以生成 近似層次模型 的策略,該策略同時考慮了矩陣乘積運算的計算時間。這個計算時間並非與矩陣的維數是簡單線性關係。
2. 在近來的GPU上對該模型進行了實證分析。在所提出的優化算法中也包含了對實際計算時間模型的定義。
3. 與一般的softmax相比,有2× 到 10× 的加速。這等價於在同等算力限制下提高了準確度。另外一點非常重要,該paper所提出的這種高效計算的方法與一些通過并行提高效率的方法相比,在給定一定量的training data下,對準確度並沒有損失。
3. Adaptive Softmax
3.1 矩陣乘積運算的計算時間模型
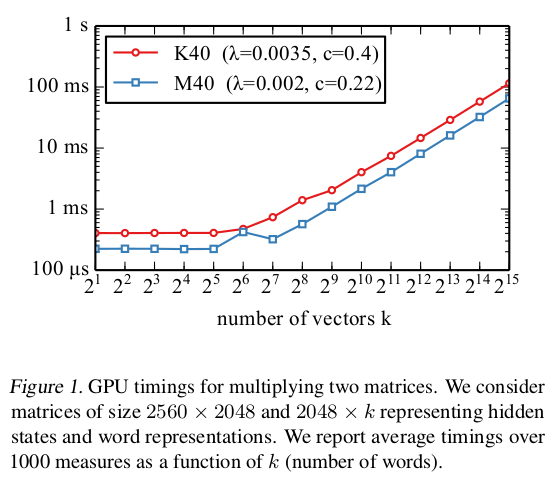
hidden states: (B × d); Word representation: (d × k); 這兩個矩陣的乘積運算時間: g(k, B)。其中B是batch size, d: hidden layer 的size, k vectors的數量。
(1) 固定B,d, 探究k值大小與g(k)的關係:
在K40、 M40兩種GPU model中進行實驗,發現k在大約為$k_0 \approx 50$的範圍之內,g(k)是常數級別的,在$k > k_0$后,呈線性依賴關係。其計算模型為:
同樣的,關於B的計算時間的函數也呈現這樣的關係。這可以表示,矩陣相乘時,當其中一個維度很小時,矩陣乘法是低效的。
如何理解呢?比如對於 $k_1 = 2^2$, $k_2 = 2^4$,它們均在同樣的常量時間內完成運算,那麼顯然對於$k1$量級有算力被浪費了。
那麼這也說明,一些words的層次結構,其每個節點只具有少量的子節點(比如huffman 編碼的tree),是次優的。
(2) 探究batch size B值大小與g(B)的關係:
同樣的,當探究計算用時與batch size $B$,的關係時,發現在矩陣乘法運算中,其中一個維度很小時計算並不高效。因此會導致:
(i) 在層次結構中,因為每個節點只有少數一些孩子節點 (比如Huffman 樹),其計算效率是次優的;
(ii) 對於按照詞頻劃分clusters后,那些只包含稀有詞的cluster,被選擇的概率為p, 並且其batch size也縮減為 $p B$,也會出現以上所述的低效的矩陣乘積運算問題。
(3) 本文的計算模型
所以paper中綜合考慮了k與B,提出了下面的計算模型:
對於Adaptive Softmax, 其核心思想是根據詞頻大小,將不同詞頻區間的詞分為不同的clusters,按照詞頻高的優先訪問的原則,來對每個cluster整體,進而對cluster中的每個詞進行訪問,進行softmax操作。
那麼paper中首先以2個clusters為例,對該模型進行講解,之後推廣到多個clusters的一般情況。
3.2 Two-Clusters Case
根據Zipf定律,在Penn TreeBank中 20%的詞,可以覆蓋一般文檔中87%的出現過的詞。
直觀地,可以將字典$V$中的詞分為$V_h$、$V_t$兩個部分。其中$V_h$表示高頻詞集合(head),$V_t$表示低頻詞集合(tail)。一般地,$|V_h| << |V_t|$,$P(V_h) >> P(V_t)$。
(1) Clusters 的組織
直觀地可以想到對於這兩個clusters有兩種組織方式:(i) 兩個clusters都是2層的樹結構,(ii) 將head部分用一個短列表保存,對tail部分用二層樹結構。何種方式更優可以就其計算效率和準確率進行比較:
在準確率方面,(i) 較之 (ii) 一般有 5 ~ 10 %的下降。原因如下:
對於屬於cluster $c$的每個詞$w$的概率計算為:
若採用(i): $P(c | h) * P(w | c, h)$
若採用(ii): 對於高頻詞head部分可以直接計算獲得 $P(w | h)$,其更為簡單直接。
因此,除非(i)(ii)的計算時間有非常大的差別,否則選擇(ii)的組織方式。
(2) 對計算時間的縮短
圖2. Two clusters示意圖
如圖2所示,$k_h = |V_h|, k_t = k – k_h, p_t = 1 – p_h$
(i) 對於第一層:對於batch size 為B的輸入,在head中對$k_h$個高頻詞以及1個單位的二層cluster的向量(加陰影部分),共$k_h + 1$個向量,做softmax,
這樣占文檔中$p_h$的詞可以基本確定下來,在head 的 short list 部分找到對應的單詞;
而如果與陰影部分進行softmax值更大,表明待預測的詞,在第二層的低頻詞部分;
第一層的計算開銷為:$g(k_h + 1, B)$
(ii) 在short list 中確定了 $p_h × B$ 的內容后,還剩下 $p_t B$的輸入需要在tail中繼續進行softmax來確定所預測的詞。
第二層中需要對$k_t$個向量做softmax;
第二層的計算開銷為:$g(k_t, pB)$
綜上,總的計算開銷為:$$C = g(k_h + 1, B) + g(k_t, p_t B)$$
相比於最初的softmax,分母中需要對詞典中的每個詞的向量逐一進行計算;採用adaptive softmax可以使得該過程分為兩部分進行,每部分只需對該部分所包含的詞的向量進行計算即可,降低了計算用時。
論文中的Figure 2显示了,對於$k_h$的合理劃分,最高可以實現相較於完全softmax的5x加速。
(3) 不同cluster的分類器能力不同
由於每個cluster基本是獨立計算的,它們並不要求有相同的能力(capacity)。
一般可以為高頻詞的cluster予以更高的capacity,而可以適當降低詞頻詞的cluster的capacity。因為低頻詞在文檔中很少出現,因此對其capacity的適當降低並不會非常影響總體的性能。
在本文中,採取了為不同的clusters共享隱層,通過加映射矩陣的方式降低分類器的輸入大小。一般的,tail部分的映射矩陣將其大小從$d$維縮小到$d_t = d / 4$維。
3.3 一般性情況
在3.2中以分為2個cluster為例,介紹了adaptive softmax如何組織並計算的,這裏將其拓展為一般情況,即可以分為多個clusters時的處理方式。
假設將整個詞典分為一個head部分和J個詞頻詞cluster部分,那麼有:
$$V = V_h \cup V_1 … V_j, V_i \cap V_j = \phi$$
其中$V_h$在第一層,其餘均在第二層,如圖Figure 3所示。
每個cluster中的詞向量的數目為$k_i = |V_i|$,單詞$w$屬於某個cluster的概率為:$p_i = \sum_{w \in V_i} p(w)$.
那麼,
計算head部分的時間開銷為:$C_h = g(J + k_h, B)$
計算每個二層cluster的時間開銷為:$\forall_i, C_i = g(k_i, p_i B)$
那麼總的時間開銷為:$C = g(J + k_h, B) + \sum_i g(k_i, p_i B) \tag8$
回顧公式(7):
$$g(k,B) = max(c + \lambda k_0 B_0, c + \lambda k B) \tag7$$
這裡有兩部分,一個是常數部分$c + \lambda k_0 B_0$,一個是線性變換部分$c + \lambda k B$。
通過3.1可知,在常數部分GPU的算力並未得到充分利用,因此應盡量避免落入該部分。那麼需要滿足:
$kB \geq k_0B_0$,這樣在求max時,可以利用以上的第二部分。
將(8)式代入(7)的第二部分得:
那麼接下來的目標就是根據(10) 以最小化時間開銷C.
在(10)中,$J ,B$是固定的,那麼可以重點關注$\sum_i p_ik_i$與$k_h$。
(1) $\sum_i p_ik_i$
假設$p_{i + j} = p_i + p_j$, 那麼 $p_jk_j = (p_{i + j} – p_i) k_j$
$p_ik_i + p_jk_j = p_i(k_i – k_j) + p_{i + j}k_j \tag{11}$
假設$k_i > k_j, p_{i + j}$, $k_j$均固定,那麼(11)中只有$p_i$可變,可以通過減小$p_i$的方式使(11)式減小。=> 也即$k_i > k_j$ 且 $p_i$盡量小,即包含越多詞的cluster,其概率越小。
(2) $k_h$
減小$k_h$可以使(10)式減小。 => 即為可以使高頻詞所在的cluster包含更少的詞。
綜上,給定了cluster的個數J,與batch size B,可以通過給大的cluster分配以更小的概率降低時間開銷C.
另外paper中講到可以用動態規劃的方法,在給定了J后,對$k_i$的大小進行劃分。
cluster的劃分個數$J$。paper中實驗了採用不同的J所導致的不同計算時間。如圖Figure 4所示。雖然在$10 ~ 15$區間內效果最好,但$ > 5$之後效果沒有非常明顯的提升。所以文中建議採用2~5個clusters。
實驗主要在text8, europarl, one billion word三個數據集上做的,通過比較ppl發現,adaptive softmax仍能保持低的ppl,並且相比於原模型有2x到10x的提速。
參考鏈接:
1. Efficient softmax approximation for GPUs:
Some of us get dipped in flat, some in satin, some in gloss. But every once in a while you find someone who’s iridescent, and when you do, nothing will ever compare. ~ Flipped
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象