使用請求頭認證來測試需要授權的 API 接口
Intro
有一些需要認證授權的接口在寫測試用例的時候一般會先獲取一個 token,然後再去調用接口,其實這樣做的話很不靈活,一方面是存在着一定的安全性問題,獲取 token 可能會有一些用戶名密碼之類的測試數據,還有就是獲取 token 的話如果全局使用同一個 token 會很不靈活,如果我要測試沒有用戶信息的話還比較簡單,我可以不傳遞 token,如果token里有兩個角色,我要測試另外一個角色的時候,只能給這個測試用戶新增一個角色然後再獲取token,這樣就很不靈活,於是我就嘗試把之前寫的自定義請求頭認證的代碼,整理了一下,集成到了一個 nuget 包里以方便其他項目使用,nuget 包是 WeihanLi.Web.Extensions,源代碼在這裏 https://github.com/WeihanLi/WeihanLi.Web.Extensions 有想自己改的可以直接拿去用,目前提供了基於請求頭的認證和基於 QueryString 的認證兩種認證方式。
實現效果
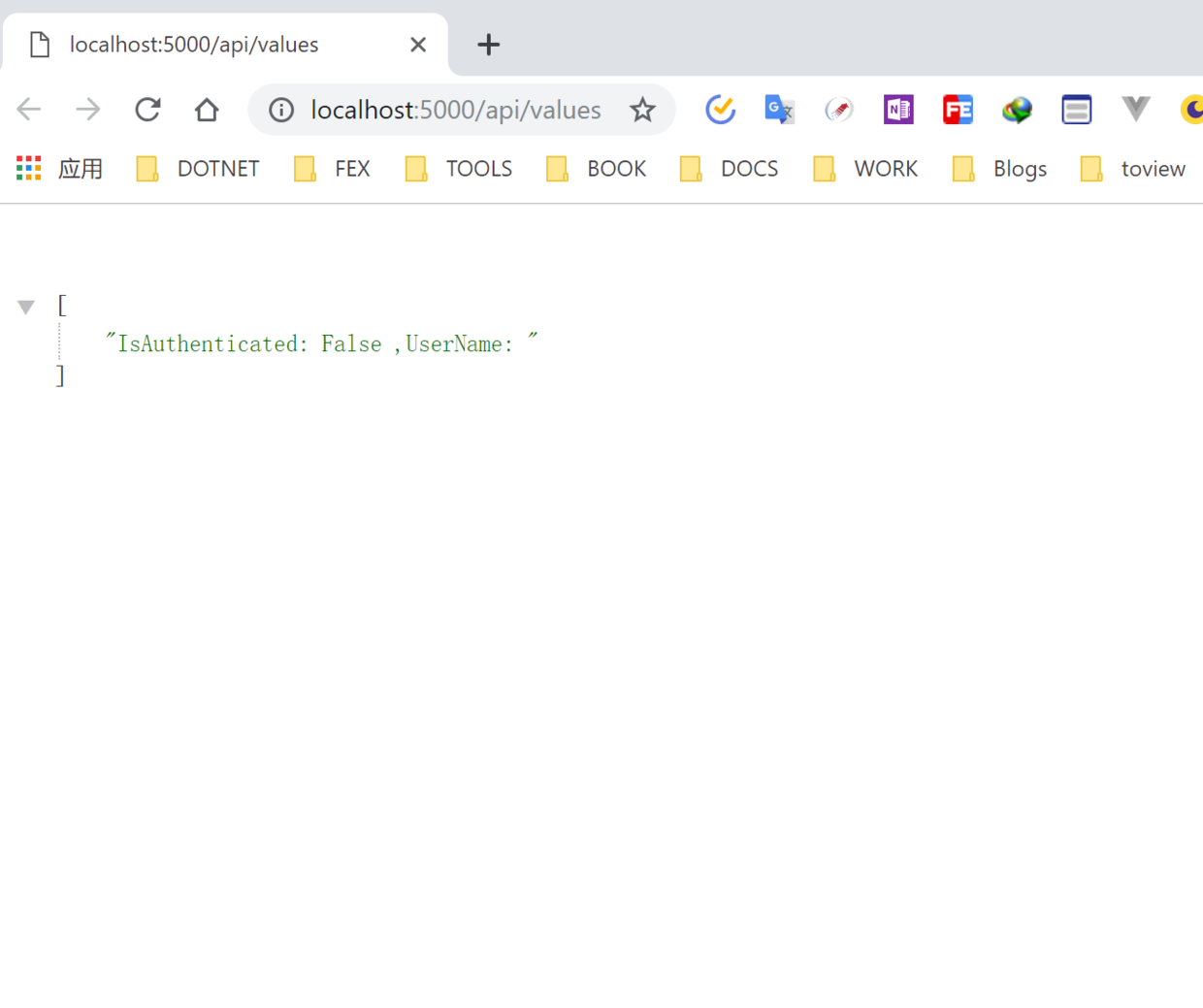
基於請求頭動態配置用戶的信息,需要什麼樣的信息就在請求頭中添加什麼信息,示例如下:
再來看個單元測試的示例:
[Fact]
public async Task MakeReservationWithUserInfo()
{
using var request = new HttpRequestMessage(HttpMethod.Post, "/api/reservations");
request.Headers.TryAddWithoutValidation("UserId", GuidIdGenerator.Instance.NewId()); // 用戶Id
request.Headers.TryAddWithoutValidation("UserName", Environment.UserName); // 用戶名
request.Headers.TryAddWithoutValidation("UserRoles", "User,ReservationManager"); //用戶角色
request.Content = new StringContent($@"{{""reservationUnit"":""nnnnn"",""reservationActivityContent"":""13211112222"",""reservationPersonName"":""謝謝謝"",""reservationPersonPhone"":""13211112222"",""reservationPlaceId"":""f9833d13-a57f-4bc0-9197-232113667ece"",""reservationPlaceName"":""第一多功能廳"",""reservationForDate"":""2020-06-13"",""reservationForTime"":""10:00~12:00"",""reservationForTimeIds"":""1""}}", Encoding.UTF8, "application/json");
using var response = await Client.SendAsync(request);
Assert.Equal(HttpStatusCode.OK, response.StatusCode);
}
實現原理解析
實現原理其實挺簡單的,就是實現了一種基於 header 的自定義認證模式,從 header 中獲取用戶信息並進行認證,核心代碼如下:
protected override async Task<AuthenticateResult> HandleAuthenticateAsync()
{
if (await Options.AuthenticationValidator(Context))
{
var claims = new List<Claim>();
if (Request.Headers.TryGetValue(Options.UserIdHeaderName, out var userIdValues))
{
claims.Add(new Claim(ClaimTypes.NameIdentifier, userIdValues.ToString()));
}
if (Request.Headers.TryGetValue(Options.UserNameHeaderName, out var userNameValues))
{
claims.Add(new Claim(ClaimTypes.Name, userNameValues.ToString()));
}
if (Request.Headers.TryGetValue(Options.UserRolesHeaderName, out var userRolesValues))
{
var userRoles = userRolesValues.ToString()
.Split(new[] { Options.Delimiter }, StringSplitOptions.RemoveEmptyEntries);
claims.AddRange(userRoles.Select(r => new Claim(ClaimTypes.Role, r)));
}
if (Options.AdditionalHeaderToClaims.Count > 0)
{
foreach (var headerToClaim in Options.AdditionalHeaderToClaims)
{
if (Request.Headers.TryGetValue(headerToClaim.Key, out var headerValues))
{
foreach (var val in headerValues.ToString().Split(new[] { Options.Delimiter }, StringSplitOptions.RemoveEmptyEntries))
{
claims.Add(new Claim(headerToClaim.Value, val));
}
}
}
}
// claims identity 's authentication type can not be null https://stackoverflow.com/questions/45261732/user-identity-isauthenticated-always-false-in-net-core-custom-authentication
var principal = new ClaimsPrincipal(new ClaimsIdentity(claims, Scheme.Name));
var ticket = new AuthenticationTicket(
principal,
Scheme.Name
);
return AuthenticateResult.Success(ticket);
}
return AuthenticateResult.NoResult();
}
其實就是將請求頭的信息讀取到 Claims,然後返回一個 ClaimsPrincipal 和 AuthenticationTicket,在讀取 header 之前有一個 AuthenticationValidator 是用來驗證請求是不是滿足使用 Header 認證,是一個基於 HttpContext 的斷言委託(Func<HttpContext, Task<bool>>),默認實現是驗證是否有 UserId 對應的 Header,如果要修改可以通過 Startup 來配置
使用示例
Startup 配置,和其它的認證方式一樣,Header 認證和 Query 認證也提供了基於 AuthenticationBuilder 的擴展,只需要在 services.AddAuthentication() 后增加 Header 認證的模式即可,示例如下:
services.AddAuthentication(HeaderAuthenticationDefaults.AuthenticationSchema)
.AddQuery(options =>
{
options.UserIdQueryKey = "uid";
})
.AddHeader(options =>
{
options.UserIdHeaderName = "X-UserId";
options.UserNameHeaderName = "X-UserName";
options.UserRolesHeaderName = "X-UserRoles";
});
默認的 Header 是 UserId/UserName/UserRoles,你也可以自定義為符合自己需要的配置,如果只是想新增一個轉換可以配置 AdditionalHeaderToClaims 增加自己需要的請求頭 => Claims 轉換,AuthenticationValidator 也可以自定義,就是上面提到的會首先會驗證是不是需要讀取 Header,驗證通過之後才會讀取 Header 信息並認證
測試示例
有一個接口我需要登錄之後才能訪問,需要用戶信息,類似下面這樣
[HttpPost]
[Authorize]
public async Task<IActionResult> MakeReservation(
[FromBody] ReservationViewModel model
)
{
// ...
}
在測試代碼里我配置使用了 Header 認證,在請求的時候直接通過 Header 來控制用戶的信息
Startup 配置:
services
.AddAuthentication(HeaderAuthenticationDefaults.AuthenticationSchema)
.AddHeader()
// 使用 Query 認證
//.AddAuthentication(QueryAuthenticationDefaults.AuthenticationSchema)
//.AddQuery()
;
測試代碼:
[Fact]
public async Task MakeReservationWithUserInfo()
{
using var request = new HttpRequestMessage(HttpMethod.Post, "/api/reservations");
request.Headers.TryAddWithoutValidation("UserId", GuidIdGenerator.Instance.NewId());
request.Headers.TryAddWithoutValidation("UserName", Environment.UserName);
request.Headers.TryAddWithoutValidation("UserRoles", "User,ReservationManager");
request.Content = new StringContent($@"{{""reservationUnit"":""nnnnn"",""reservationActivityContent"":""13211112222"",""reservationPersonName"":""謝謝謝"",""reservationPersonPhone"":""13211112222"",""reservationPlaceId"":""f9833d13-a57f-4bc0-9197-232113667ece"",""reservationPlaceName"":""第一多功能廳"",""reservationForDate"":""2020-06-13"",""reservationForTime"":""10:00~12:00"",""reservationForTimeIds"":""1""}}", Encoding.UTF8, "application/json");
using var response = await Client.SendAsync(request);
Assert.Equal(HttpStatusCode.OK, response.StatusCode);
}
[Fact]
public async Task MakeReservationWithInvalidUserInfo()
{
using var request = new HttpRequestMessage(HttpMethod.Post, "/api/reservations");
request.Headers.TryAddWithoutValidation("UserName", Environment.UserName);
request.Content = new StringContent($@"{{""reservationUnit"":""nnnnn"",""reservationActivityContent"":""13211112222"",""reservationPersonName"":""謝謝謝"",""reservationPersonPhone"":""13211112222"",""reservationPlaceId"":""f9833d13-a57f-4bc0-9197-232113667ece"",""reservationPlaceName"":""第一多功能廳"",""reservationForDate"":""2020-06-13"",""reservationForTime"":""10:00~12:00"",""reservationForTimeIds"":""1""}}", Encoding.UTF8, "application/json");
using var response = await Client.SendAsync(request);
Assert.Equal(HttpStatusCode.Unauthorized, response.StatusCode);
}
[Fact]
public async Task MakeReservationWithoutUserInfo()
{
using var request = new HttpRequestMessage(HttpMethod.Post, "/api/reservations")
{
Content = new StringContent(
@"{""reservationUnit"":""nnnnn"",""reservationActivityContent"":""13211112222"",""reservationPersonName"":""謝謝謝"",""reservationPersonPhone"":""13211112222"",""reservationPlaceId"":""f9833d13-a57f-4bc0-9197-232113667ece"",""reservationPlaceName"":""第一多功能廳"",""reservationForDate"":""2020-06-13"",""reservationForTime"":""10:00~12:00"",""reservationForTimeIds"":""1""}",
Encoding.UTF8, "application/json")
};
using var response = await Client.SendAsync(request);
Assert.Equal(HttpStatusCode.Unauthorized, response.StatusCode);
}
More
QueryString 認證和請求頭認證是類似的,這裏就不再贅述,只是把請求頭上的參數轉移到 QueryString 上了,覺得不夠好用的可以直接 Github 上找源碼修改, 也歡迎 PR,源碼地址: https://github.com/WeihanLi/WeihanLi.Web.Extensions
Reference
- https://github.com/WeihanLi/WeihanLi.Web.Extensions
- https://www.nuget.org/packages/WeihanLi.Web.Extensions
- https://github.com/OpenReservation/ReservationServer/blob/dev/ActivityReservation.API.Test/TestStartup.cs
- https://github.com/OpenReservation/ReservationServer/blob/dev/ActivityReservation.API.Test/Controllers/ReservationControllerTest.cs
- https://www.cnblogs.com/weihanli/p/cutom-authentication-in-aspnetcore.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※推薦台中搬家公司優質服務,可到府估價