目錄
- 一、背景
- 二、JAVA對象拷貝的實現
- 2.1 淺拷貝
- 2.2 深拷貝的實現方法一
- 2.3 深拷貝的實現方法二
- 2.3.1 C++拷貝構造函數
- 2.3.2 C++源碼
- 2.3.3 JAVA通過拷貝構造方法實現深拷貝
- 四、總結
一、背景
JAVA編程中的對象一般都是通過new進行創建的,新創建的對象通常是初始化的狀態,但當這個對象某些屬性產生變更,且要求用一個對象副本來保存當前對象的“狀態”,這時候就需要用到對象拷貝的功能,以便封裝對象之間的快速克隆。
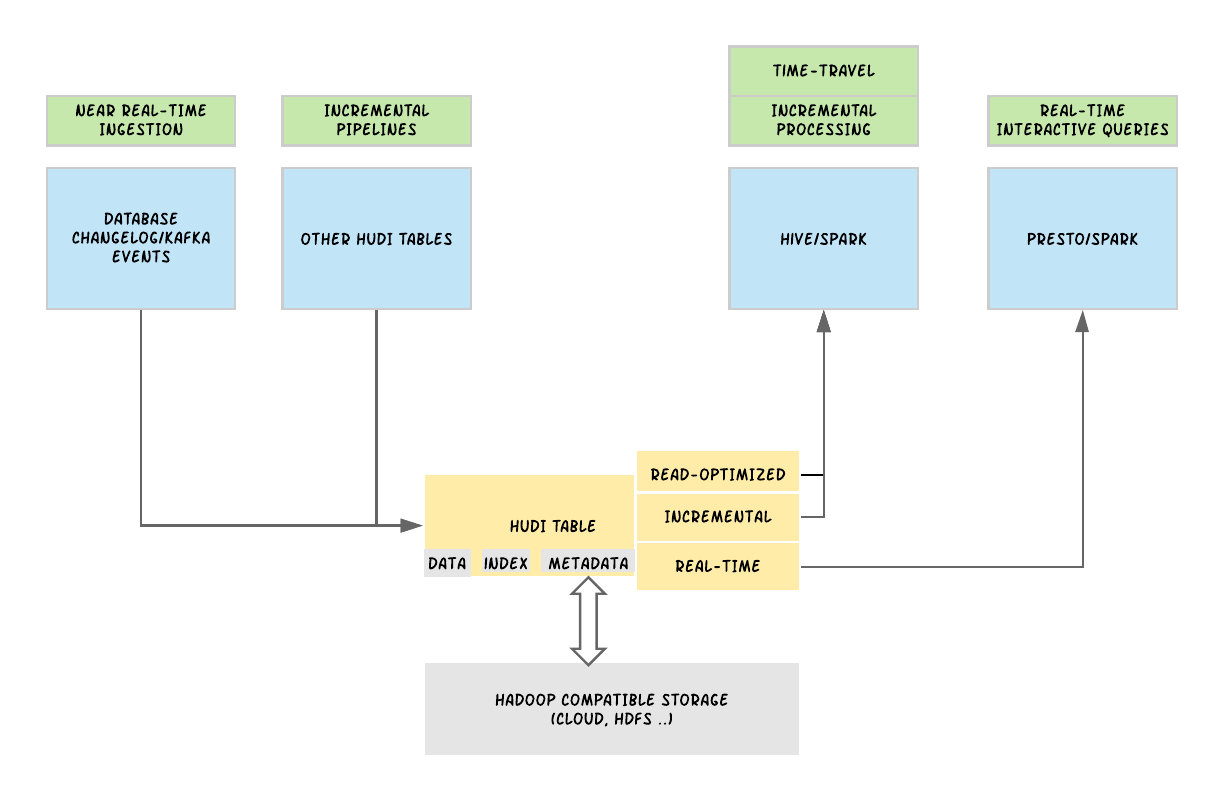
二、JAVA對象拷貝的實現
2.1 淺拷貝
- 被複制的類需要實現Clonenable接口;
- 覆蓋clone()方法,調用super.clone()方法得到需要的複製對象;
- 淺拷貝對基本類型(boolean,char,byte,short,float,double.long)能完成自身的複製,但對於引用類型只對引用地址進行拷貝。
— 下面我們用一個實例進行驗證:
/**
* 單隻牌
*
* @author zhuhuix
* @date 2020-06-10
*/
public class Card implements Comparable, Serializable,Cloneable {
// 花色
private String color = "";
//数字
private String number = "";
public Card() {
}
public Card(String color, String number) {
this.color = color;
this.number = number;
}
public String getColor() {
return this.color;
}
public void setColor(String color) {
this.color = color;
}
public String getNumber() {
return this.number;
}
public void setNumber(String number) {
this.number = number;
}
@Override
public String toString() {
return this.color + this.number;
}
@Override
public int compareTo(Object o) {
if (o instanceof Card) {
int thisColorIndex = Constant.COLORS.indexOf(this.getColor());
int anotherColorIndex = Constant.COLORS.indexOf(((Card) o).getColor());
int thisNumberIndex = Constant.NUMBERS.indexOf(this.getNumber());
int anotherNumberIndex = Constant.NUMBERS.indexOf(((Card) o).getNumber());
// 大小王之間相互比較: 大王大於小王
if ("JOKER".equals(this.color) && "JOKER".equals(((Card) o).getColor())) {
return thisColorIndex > anotherColorIndex ? 1 : -1;
}
// 大小王與数字牌之間相互比較:大小王大於数字牌
if ("JOKER".equals(this.color) && !"JOKER".equals(((Card) o).getColor())) {
return 1;
}
if (!"JOKER".equals(this.color) && "JOKER".equals(((Card) o).getColor())) {
return -1;
}
// 数字牌之間相互比較: 数字不相等,数字大則牌面大;数字相等 ,花色大則牌面大
if (thisNumberIndex == anotherNumberIndex) {
return thisColorIndex > anotherColorIndex ? 1 : -1;
} else {
return thisNumberIndex > anotherNumberIndex ? 1 : -1;
}
} else {
return -1;
}
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
/**
* 撲克牌常量定義
*
* @author zhuhuix
* @date 2020-06-10
*/
public class Constant {
// 紙牌花色:黑桃,紅心,梅花,方塊
final static List<String> COLORS = new ArrayList<>(
Arrays.asList(new String[]{"", "", "", ""}));
// 紙牌数字
final static List<String> NUMBERS = new ArrayList<>(
Arrays.asList(new String[]{"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"}));
// 大王小王
final static List<String> JOKER = new ArrayList<>(
Arrays.asList(new String[]{"小王","大王"}));
}
/**
* 整副副撲克牌
*
* @author zhuhuix
* @date 2020-06-10
*/
public class Poker implements Cloneable, Serializable {
private List<Card> cards;
public Poker() {
List<Card> cardList = new ArrayList<>();
// 按花色與数字組合生成52張撲克牌
for (int i = 0; i < Constant.COLORS.size(); i++) {
for (int j = 0; j < Constant.NUMBERS.size(); j++) {
cardList.add(new Card(Constant.COLORS.get(i), Constant.NUMBERS.get(j)));
}
}
// 生成大小王
for (int i = 0; i < Constant.JOKER.size(); i++) {
cardList.add(new Card("JOKER", Constant.JOKER.get(i)));
}
this.cards = cardList;
}
// 從整副撲克牌中抽走大小王
public void removeJoker() {
Iterator<Card> iterator = this.cards.iterator();
while (iterator.hasNext()) {
Card cardJoker = iterator.next();
if (cardJoker.getColor() == "JOKER") {
iterator.remove();
}
}
}
public List<Card> getCards() {
return cards;
}
public void setCards(List<Card> cards) {
this.cards = cards;
}
public Integer getCardCount() {
return this.cards.size();
}
@Override
public String toString() {
StringBuilder poker = new StringBuilder("[");
Iterator<Card> iterator = this.cards.iterator();
while (iterator.hasNext()) {
poker.append(iterator.next().toString() + ",");
}
poker.setCharAt(poker.length() - 1, ']');
return poker.toString();
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
/**
* 測試程序
*
* @author zhuhuix
* @date 2020-6-10
*/
public class PlayDemo {
public static void main(String[] args) throws CloneNotSupportedException {
// 生成一副撲克牌並洗好牌
Poker poker1 = new Poker();
System.out.println("新建:第一副牌共 "+poker1.getCardCount()+" 張:"+poker1.toString());
Poker poker2= (Poker) poker1.clone();
System.out.println("第一副牌拷頁生成第二副牌,共 "+poker2.getCardCount()+" 張:"+poker2.toString());
poker1.removeJoker();
System.out.println("====第一副牌抽走大小王后====");
System.out.println("第一副牌還有 "+poker1.getCardCount()+" 張:"+poker1.toString());
System.out.println("第二副牌還有 "+poker2.getCardCount()+" 張:"+poker2.toString());
}
}
- 運行結果:
— 在第一副的對象中抽走了“大小王”,克隆的第二副的對象的“大小王”竟然也被“抽走了”
2.2 深拷貝的實現方法一
- 被複制的類需要實現Clonenable接口;
- 覆蓋clone()方法,自主實現引用類型成員的拷貝複製。
— 我們只要改寫一下Poker類中的clone方法,讓引用類型成員實現複製:
/**
* 整副副撲克牌--自主實現引用變量的複製
*
* @author zhuhuix
* @date 2020-06-10
*/
public class Poker implements Cloneable, Serializable {
private List<Card> cards;
public Poker() {
List<Card> cardList = new ArrayList<>();
// 按花色與数字組合生成52張撲克牌
for (int i = 0; i < Constant.COLORS.size(); i++) {
for (int j = 0; j < Constant.NUMBERS.size(); j++) {
cardList.add(new Card(Constant.COLORS.get(i), Constant.NUMBERS.get(j)));
}
}
// 生成大小王
for (int i = 0; i < Constant.JOKER.size(); i++) {
cardList.add(new Card("JOKER", Constant.JOKER.get(i)));
}
this.cards = cardList;
}
// 從整副撲克牌中抽走大小王
public void removeJoker() {
Iterator<Card> iterator = this.cards.iterator();
while (iterator.hasNext()) {
Card cardJoker = iterator.next();
if (cardJoker.getColor() == "JOKER") {
iterator.remove();
}
}
}
public List<Card> getCards() {
return cards;
}
public void setCards(List<Card> cards) {
this.cards = cards;
}
public Integer getCardCount() {
return this.cards.size();
}
@Override
public String toString() {
StringBuilder poker = new StringBuilder("[");
Iterator<Card> iterator = this.cards.iterator();
while (iterator.hasNext()) {
poker.append(iterator.next().toString() + ",");
}
poker.setCharAt(poker.length() - 1, ']');
return poker.toString();
}
// 遍歷原始對象的集合,對生成的對象進行集合複製
@Override
protected Object clone() throws CloneNotSupportedException {
Poker newPoker = (Poker)super.clone();
newPoker.cards = new ArrayList<>();
newPoker.cards.addAll(this.cards);
return newPoker;
}
}
- 輸出結果:
— 通過自主實現引用類型的複製,原對象與對象的拷貝的引用類型成員地址不再關聯
2.3 深拷貝的實現方法二
- 在用第二種方式實現JAVA深拷貝之前,我們首先對C++程序的對象拷貝做個了解:
2.3.1 C++拷貝構造函數
C++拷貝構造函數,它只有一個參數,參數類型是本類的引用,且一般用const修飾
2.3.2 C++源碼
// 單隻牌的類定義
// Created by Administrator on 2020-06-10.
//
#ifndef _CARD_H
#define _CARD_H
#include <string>
using namespace std;
class Card {
private :
string color;
string number;
public:
Card();
Card(const string &color, const string &number);
const string &getColor() const;
void setColor(const string &color);
const string &getNumber() const;
void setNumber(const string &number);
string toString();
};
#endif //_CARD_H
// 單隻牌類的實現
// Created by Administrator on 2020-06-10.
//
#include "card.h"
Card::Card(){}
Card::Card(const string &color, const string &number) : color(color), number(number) {}
const string &Card::getColor() const {
return color;
}
void Card::setColor(const string &color) {
Card::color = color;
}
const string &Card::getNumber() const {
return number;
}
void Card::setNumber(const string &number) {
Card::number = number;
}
string Card::toString() {
return getColor()+getNumber();
}
// 撲克牌類的定義
// Created by Administrator on 2020-06-10.
//
#ifndef _POKER_H
#define _POKER_H
#include <vector>
#include "card.h"
using namespace std;
const int COLOR_COUNT=4;
const int NUMBER_COUNT=13;
const int JOKER_COUNT=2;
const string COLORS[COLOR_COUNT] = {"", "", "", ""};
const string NUMBERS[NUMBER_COUNT]={"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};
const string JOKER[JOKER_COUNT] ={"小王","大王"};
class Poker {
private:
vector<Card> cards;
public:
Poker();
Poker(const Poker &poker);
const vector<Card> &getCards() const;
void setCards(const vector<Card> &cards);
int getCardCount();
void toString();
void clear();
};
#endif //_POKER_H
// 撲克牌類的實現
// Created by zhuhuix on 2020-06-10.
//
#include "Poker.h"
#include <iostream>
const vector<Card> &Poker::getCards() const {
return this->cards;
}
void Poker::setCards(const vector<Card> &cards) {
Poker::cards = cards;
}
// 構造函數
Poker::Poker() {
for (int i = 0; i < NUMBER_COUNT; i++) {
for (int j = 0; j < COLOR_COUNT; j++) {
this->cards.emplace_back(COLORS[j], NUMBERS[i]);
}
}
for (int i = 0; i < JOKER_COUNT; i++) {
this->cards.emplace_back("JOKER", JOKER[i]);
}
}
// 拷貝構造函數
Poker::Poker(const Poker &poker) {
for (int i = 0; i < poker.getCards().size(); i++) {
this->cards.emplace_back(poker.cards[i].getColor(), poker.cards[i].getNumber());
}
}
int Poker::getCardCount() {
return this->cards.size();
}
void Poker::toString() {
cout << "共" << getCardCount() << "張牌:";
cout << "[";
for (int i = 0; i < this->cards.size(); i++) {
cout << this->cards[i].toString();
if (i != getCardCount() - 1) {
cout << ",";
}
}
cout << "]" << endl;
}
void Poker::clear() {
this->cards.clear();
}
// 主測試程序
// Created by Administrator on 2020-06-10.
//
#include "Poker.h"
#include <iostream>
using namespace std;
int main() {
Poker poker1;
cout << "第一副牌:";
poker1.toString();
// 通過拷貝構造函數生成第二副牌
Poker poker2(poker1);
cout << "第二副牌:";
poker2.toString();
// 清除撲克牌1
poker1.clear();
cout << "清空后,第一副牌:";
poker1.toString();
cout << "第二副牌:";
poker2.toString();
return 0;
}
- 輸出:
2.3.3 JAVA通過拷貝構造方法實現深拷貝
- JAVA拷貝構造方法與C++的拷貝構造函數相同,被複制對象的類需要實現拷貝構造方法:
—首先需要聲明帶有和本類相同類型的參數構造方法
—其次拷貝構造方法可以通過序列化實現快速複製 - 拷貝對象通過調用拷貝構造方法進行創建。
— 我們再改寫一下Poker類,實現拷貝構造方法:
/**
* 整副副撲克牌--實現拷貝構造方法
*
* @author zhuhuix
* @date 2020-06-10
*/
public class Poker implements Serializable {
private List<Card> cards;
public Poker() {
List<Card> cardList = new ArrayList<>();
// 按花色與数字組合生成52張撲克牌
for (int i = 0; i < Constant.COLORS.size(); i++) {
for (int j = 0; j < Constant.NUMBERS.size(); j++) {
cardList.add(new Card(Constant.COLORS.get(i), Constant.NUMBERS.get(j)));
}
}
// 生成大小王
for (int i = 0; i < Constant.JOKER.size(); i++) {
cardList.add(new Card("JOKER", Constant.JOKER.get(i)));
}
this.cards = cardList;
}
// 拷貝構造方法:利用序列化實現深拷貝
public Poker(Poker poker) {
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(os);
oos.writeObject(poker);
ByteArrayInputStream is = new ByteArrayInputStream(os.toByteArray());
ObjectInputStream ois = new ObjectInputStream(is);
this.cards = ((Poker) ois.readObject()).getCards();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
// 從整副撲克牌中抽走大小王
public void removeJoker() {
Iterator<Card> iterator = this.cards.iterator();
while (iterator.hasNext()) {
Card cardJoker = iterator.next();
if (cardJoker.getColor() == "JOKER") {
iterator.remove();
}
}
}
public List<Card> getCards() {
return cards;
}
public void setCards(List<Card> cards) {
this.cards = cards;
}
public Integer getCardCount() {
return this.cards.size();
}
@Override
public String toString() {
StringBuilder poker = new StringBuilder("[");
Iterator<Card> iterator = this.cards.iterator();
while (iterator.hasNext()) {
poker.append(iterator.next().toString() + ",");
}
poker.setCharAt(poker.length() - 1, ']');
return poker.toString();
}
}
- 對測試主程序進行修改:
/**
* 測試程序
*
* @author zhuhuix
* @date 2020-6-10
*/
public class PlayDemo {
public static void main(String[] args) throws CloneNotSupportedException {
// 生成一副撲克牌並洗好牌
Poker poker1 = new Poker();
System.out.println("新建:第一副牌共 "+poker1.getCardCount()+" 張:"+poker1.toString());
Poker poker2 = new Poker(poker1);
System.out.println("第一副牌拷頁生成第二副牌,共 "+poker2.getCardCount()+" 張:"+poker2.toString());
poker1.removeJoker();
System.out.println("====第一副牌抽走大小王后====");
System.out.println("第一副牌還有 "+poker1.getCardCount()+" 張:"+poker1.toString());
System.out.println("第二副牌還有 "+poker2.getCardCount()+" 張:"+poker2.toString());
Poker poker3 = new Poker(poker1);
System.out.println("第三副牌還有 "+poker3.getCardCount()+" 張:"+poker3.toString());
}
}
- 輸出結果:
–通過序列化的有手段,同樣也能實現對象的深拷貝
四、總結
- java程序進行對象拷貝時,如果對象的類中存在引用類型時,需進行深拷貝
- 對象拷貝可以通過實現Cloneable接口完成
- java編程也可仿照 C++程序的拷貝構造函數,實現拷貝構造方法進行對象的複製
- 通過序列化與反序化手段可實現對象的深拷貝
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準