在Asp.NET Core中如何優雅的管理用戶機密數據
背景
回顧
在軟件開發過程中,使用配置文件來管理某些對應用程序運行中需要使用的參數是常見的作法。在早期VB/VB.NET時代,經常使用.ini文件來進行配置管理;而在.NET FX開發中,我們則傾向於使用web.config文件,通過配置appsetting的配置節來處理;而在.NET Core開發中,我們有了新的基於json格式的appsetting.json文件。
無論採用哪種方式,其實配置管理從來都是一件看起來簡單,但影響非常深遠的基礎性工作。尤其是配置的安全性,貫穿應用程序的始終,如果沒能做好安全性問題,極有可能會給系統帶來不可控的風向。
源代碼比配置文件安全么?
有人以為把配置存放在源代碼中,可能比存放在明文的配置文件中似乎更安全,其實是“皇帝的新裝”。
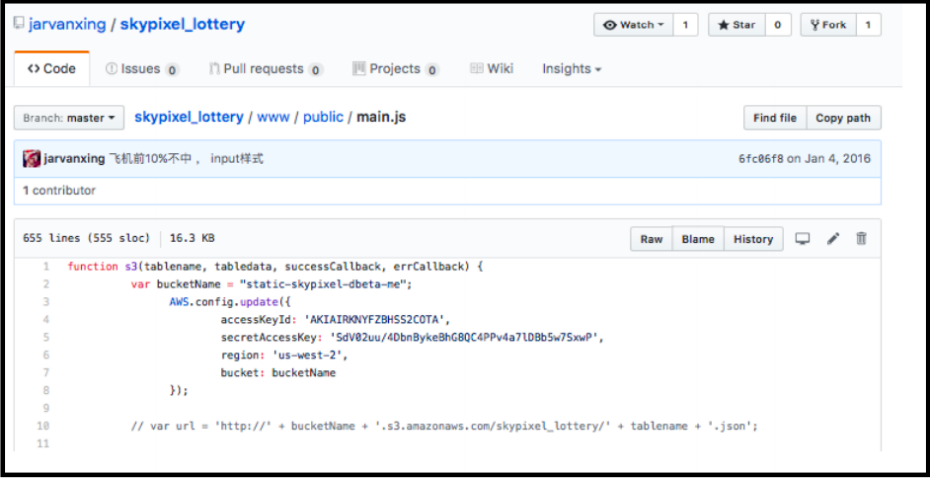
在前不久,筆者的一位朋友就跟我說了一段故事:他說一位同事在離職后,直接將曾經寫過的一段代碼上傳到github的公共倉庫,而這段代碼中包含了某些涉及到原企業的機密數據,還好被github的安全機制提前發現而及時終止了該行為,否則後果不堪設想。
於是,筆者順手查了一下由於有意或無意泄露企業機密,造成企業損失的案例,發現還真不少。例如大疆前員工通過 Github 泄露公司源代碼,被罰 20 萬、獲刑半年 這起案件,也是一個典型的案例。
該員工離職后,將包含關鍵配置信息的源代碼上傳到github的公共倉庫,被黑客利用,使得大量用戶私人數據被黑客獲取,該前員工最終被刑拘。
圖片來源: http://www.digitalmunition.com/WhyIWalkedFrom3k.pdf
大部分IT公司都會在入職前進行背景調查,而一旦有案底,可能就已經與許多IT公司無緣;即便是成為創業者,也可能面臨無法跟很多正規企業合作的問題。
小結
所以,安全性問題不容小覷,哪怕時間再忙,也不要急匆匆的就將數據庫連接字符串或其他包含敏感信息的內容輕易的記錄在源代碼或配置文件中。在這個點上,一旦出現問題,往往都是非常嚴重的問題。
如何實現
在.NET FX時代,我們可以使用對web.config文件的關鍵配置節進行加密的方式,來保護我們的敏感信息,在.NET Core中,自然也有這些東西,接下來我將簡述在開發環境和生產環境下不同的配置加密手段,希望能夠給讀者帶來啟迪。
開發環境
在開發環境下,我們可以使用visual studio 工具提供的用戶機密管理器,只需0行代碼,即可輕鬆完成關鍵配置節的處理。
機密管理器概述
根據微軟官方文檔 的描述:
ASP.NET Core 機密管理器工具提供了開發過程中在源代碼外部保存機密的另一種方法 。 若要使用機密管理器工具,請在項目文件中安裝包 Microsoft.Extensions.Configuration.SecretManager 。 如果該依賴項存在並且已還原,則可以使用
dotnet user-secrets命令來通過命令行設置機密的值。 這些機密將存儲在用戶配置文件目錄中的 JSON 文件中(詳細信息隨操作系統而異),與源代碼無關。機密管理器工具設置的機密是由使用機密的項目的
UserSecretsId屬性組織的。 因此,必須確保在項目文件中設置 UserSecretsId 屬性,如下面的代碼片段所示。 默認值是 Visual Studio 分配的 GUID,但實際字符串並不重要,只要它在計算機中是唯一的。<PropertyGroup> <UserSecretsId>UniqueIdentifyingString</UserSecretsId> </PropertyGroup>
Secret Manager工具允許開發人員在開發ASP.NET Core應用程序期間存儲和檢索敏感數據。敏感數據存儲在與應用程序源代碼不同的位置。由於Secret Manager將秘密與源代碼分開存儲,因此敏感數據不會提交到源代碼存儲庫。但機密管理器不會對存儲的敏感數據進行加密,因此不應將其視為可信存儲。敏感數據作為鍵值對存儲在JSON文件中。最好不要在開發和測試環境中使用生產機密。查看引文。
存放位置
在windows平台下,機密數據的存放位置為:
%APPDATA%\Microsoft\UserSecrets\\secrets.json
而在Linux/MacOs平台下,機密數據的存放位置為:
~/.microsoft/usersecrets/<user_secrets_id>/secrets.json
在前面的文件路徑中, “將替換UserSecretsId為 .csproj文件中指定的值。
在Windows環境下使用機密管理器
在windows下,如果使用Visual Studio2019作為主力開發環境,只需在項目右鍵單擊,選擇菜單【管理用戶機密】,即可添加用戶機密數據。
在管理用戶機密數據中,添加的配置信息和傳統的配置信息沒有任何區別。
{
“ConnectionStrings”: {
“Default”: “Server=xxx;Database=xxx;User ID=xxx;Password=xxx;”
}
}
我們同樣也可以使用IConfiguration的方式、IOptions 的方式,進行配置的訪問。
在非Windows/非Visual Studio環境下使用機密管理器
完成安裝dotnet-cli后,在控制台輸入
dotnet user-secrets init
前面的命令將在UserSecretsId .csproj 文件的PropertyGroup中添加 .csproj一個元素。 UserSecretsId是對項目是唯一的Guid值。
<PropertyGroup>
<TargetFramework>netcoreapp3.1</TargetFramework>
<UserSecretsId>79a3edd0-2092-40a2-a04d-dcb46d5ca9ed</UserSecretsId>
</PropertyGroup>
設置機密
dotnet user-secrets set "Movies:ServiceApiKey" "12345"
列出機密
dotnet user-secrets list
刪除機密
dotnet user-secrets remove "Movies:ConnectionString"
清除所有機密
dotnet user-secrets clear
生產環境
機密管理器為開發者在開發環境下提供了一種保留機密數據的方法,但在開發環境下是不建議使用的,如果想在生產環境下,對機密數據進行保存該怎麼辦?
按照微軟官方文檔的說法,推薦使用Azure Key Vault 來保護機密數據,但。。我不是貴雲的用戶(當然,買不起貴雲不是貴雲太貴,而是我個人的問題[手動狗頭])。
其次,與Azure Key Valut類似的套件,例如其他雲,差不多都有,所以都可以為我們所用。
但。。如果您如果跟我一樣,不想通過第三方依賴的形式來解決這個問題,那不如就用最簡單的辦法,例如AES加密。
使用AES加密配置節
該方法與平時使用AES對字符串進行加密和解密的方法並無區別,此處從略。
使用數據保護Api(DataProtect Api實現)
在平時開發過程中,能夠動手擼AES加密是一種非常好的習慣,而微軟官方提供的數據保護API則將這個過程進一步簡化,只需調Api即可完成相應的數據加密操作。
關於數據保護api, Savorboard 大佬曾經寫過3篇博客討論這個技術問題,大家可以參考下面的文章來獲取信息。
ASP.NET Core 數據保護(Data Protection 集群場景)【上】
ASP.NET Core 數據保護(Data Protection 集群場景)【中】
ASP.NET Core 數據保護(Data Protection 集群場景)【下】
(接下來我要貼代碼了,如果沒興趣,請出門左拐,代碼不能完整運行,查看代碼)
首先,注入配置項
public static IServiceCollection AddProtectedConfiguration(this IServiceCollection services, string directory)
{
services
.AddDataProtection()
.PersistKeysToFileSystem(new DirectoryInfo(directory))
.UseCustomCryptographicAlgorithms(new ManagedAuthenticatedEncryptorConfiguration
{
EncryptionAlgorithmType = typeof(Aes),
EncryptionAlgorithmKeySize = 256,
ValidationAlgorithmType = typeof(HMACSHA256)
});
;
return services;
}
其次,實現對配置節的加/解密。(使用AES算法的數據保護機制)
public class ProtectedConfigurationSection : IConfigurationSection
{
private readonly IDataProtectionProvider _dataProtectionProvider;
private readonly IConfigurationSection _section;
private readonly Lazy<IDataProtector> _protector;
public ProtectedConfigurationSection(
IDataProtectionProvider dataProtectionProvider,
IConfigurationSection section)
{
_dataProtectionProvider = dataProtectionProvider;
_section = section;
_protector = new Lazy<IDataProtector>(() => dataProtectionProvider.CreateProtector(section.Path));
}
public IConfigurationSection GetSection(string key)
{
return new ProtectedConfigurationSection(_dataProtectionProvider, _section.GetSection(key));
}
public IEnumerable<IConfigurationSection> GetChildren()
{
return _section.GetChildren()
.Select(x => new ProtectedConfigurationSection(_dataProtectionProvider, x));
}
public IChangeToken GetReloadToken()
{
return _section.GetReloadToken();
}
public string this[string key]
{
get => GetProtectedValue(_section[key]);
set => _section[key] = _protector.Value.Protect(value);
}
public string Key => _section.Key;
public string Path => _section.Path;
public string Value
{
get => GetProtectedValue(_section.Value);
set => _section.Value = _protector.Value.Protect(value);
}
private string GetProtectedValue(string value)
{
if (value == null)
return null;
return _protector.Value.Unprotect(value);
}
}
再次,在使用前,先將待加密的字符串轉換成BASE64純文本,然後再使用數據保護API對數據進行處理,得到處理后的字符串。
private readonly IDataProtectionProvider _dataProtectorTokenProvider;
public TokenAuthController( IDataProtectionProvider dataProtectorTokenProvider)
{
}
[Route("encrypt"), HttpGet, HttpPost]
public string Encrypt(string section, string value)
{
var protector = _dataProtectorTokenProvider.CreateProtector(section);
return protector.Protect(value);
}
再替換配置文件中的對應內容。
{
"ConnectionStrings": {
"Default": "此處是加密后的字符串"
}
}
然後我們就可以按照平時獲取IOptions 的方式來獲取了。
問題
公眾號【DotNET騷操作】號主【周傑】同學提出以下觀點:
1、在生產環境下,使用AES加密,其實依然是一種不夠安全的行為,充其量也就能忽悠下產品經理,畢竟幾條簡單的語句,就能把機密數據dump出來。
也許在這種情況下,我們應該優先考慮accessKeyId/accessSecret,盡量通過設置多級子賬號,通過授權Api的機制來管理機密數據,而不是直接暴露類似於數據庫連接字符串這樣的關鍵配置信息。另外,應該定期更換數據庫的密碼,盡量將類似的問題可能造成的風險降到最低。數據保護api也提供的類似的機制,使得開發者能夠輕鬆的管理機密數據的時效性問題。
2、配置文件放到CI/CD中,發布的時候在CI/CD中進行組裝,然後運維只是負責管理CI/CD的賬戶信息,而最高機密數據,則由其他人負責配置。
嗯,我完全同意他的第二種做法,另外考慮到由於運維同樣有可能會有意無意泄露機密數據,所以如果再給運維配備一本《刑法》,並讓他日常補習【侵犯商業秘密罪】相關條款,這個流程就更加閉環了。
結語
本文簡述了在.NET Core中,如何在開發環境下使用用戶機密管理器、在生產環境下使用AES+IDataProvider的方式來保護我們的用戶敏感數據。由於時間倉促,如有考慮不周之處,還請各位大佬批評指正。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!