回顧:上一次已經把消息的布局以及樣式做好了
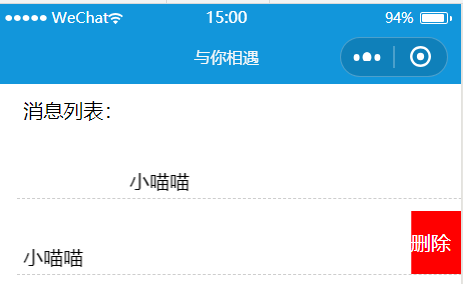
效果圖:
在removeList.js文件中,messageId就是發起這個消息的用戶了
先查看一下自定義組件的生命周期
https://developers.weixin.qq.com/miniprogram/dev/framework/custom-component/lifetimes.html
lifetimes: { attached: function() { // 在組件實例進入頁面節點樹時執行 }, detached: function() { // 在組件實例被從頁面節點樹移除時執行 }, }
直接就是在lifttimes裏面進行定義的(直接就是在methods的同級的下面加上即可了)
因為要對用戶的信息進行渲染,就可以看成是一個一個的對象,所以就可以在removeLIst.js中定義一個對象
然後遇到的問題就和之前是一樣的了,就是我們得到的數據太多了,沒必要全部都要,可以選擇性的要,只需要頭像和昵稱
(所以就可以在get前面來一個field)
lifetimes: { attached: function () { // 一進來就會進行它了 db.collection('users').doc(this.data.messageId) .field({ userPhoto : true, nickName : true }) .get().then((res)=>{ this.setData({ userMessage : res.data }); }); } }
這樣的話我們在這個頁面裏面就可以得到用戶的數據了,剩下的就是直接可以在wxml中用了
<!--components/removeList/removeList.wxml--> <movable-area class="area"> <movable-view direction="horizontal" class="view">{{ userMessage.nickName }}</movable-view> <image src="{{ userMessage.userPhoto }}" /> <view class="delete">刪除</view> </movable-area>
效果圖:
在之後設置刪除功能之前,先設置一下就是只要點擊了消息列表中用戶的頭像之後,就可以跳轉到這個用戶的詳情頁了
可以直接 在編輯個人信息的頁面 editUserInfo.wxml中COPY代碼
在設置這個跳轉頁面的url的時候,因為同時要給這個url傳遞參數的,所以這個時候就要用大括號括起來了
<!--components/removeList/removeList.wxml--> <movable-area class="area"> <movable-view direction="horizontal" class="view">{{ userMessage.nickName }}</movable-view> <navigator url="{{'/pages/detail/detail?userId=' + userMessage._id}}" open-type="navigate"> <image src="{{ userMessage.userPhoto }}" /> </navigator> <view class="delete">刪除</view> </movable-area>
即可實現,點擊頭像跳轉到個人的詳情頁面
二、下面就是對刪除功能進行設計
一開始的就是,點擊了之後,要給用戶一個提示信息,讓用戶可以選擇是取消還是確定的,這裏用的是一個wx.showModel這樣一個內置的方法
所以就要另外的給“點擊了確定”加邏輯了,就要在微信開放文檔裏面細看這個API了
https://developers.weixin.qq.com/miniprogram/dev/api/ui/interaction/wx.showModal.html
wx.showModal({
title: '提示',
content: '這是一個模態彈窗',
success (res) {
if (res.confirm) {
console.log('用戶點擊確定')
} else if (res.cancel) {
console.log('用戶點擊取消')
}
}
})
把查到的賦值給list,然後在用數組的filter進行刪除即可了
通過fileter過濾之後,就是過濾初和我們不想要的東西,然後把這些東西再次賦值為list,然後我們把前後的list打印出來會發現:
確實是過濾掉了的
由於如果要刪掉的話,就設計了removeList這個組件和message這各頁面之間的通信了,並且是子組件像父組件,用到事件來做的
https://developers.weixin.qq.com/miniprogram/dev/framework/custom-component/events.html
<!-- 當自定義組件觸發“myevent”事件時,調用“onMyEvent”方法 --> <component-tag-name bindmyevent="onMyEvent" /> <!-- 或者可以寫成 --> <component-tag-name bind:myevent="onMyEvent" />
所以在message.wxml中隊子組件remove-list設置
<remove-list wx:for="{{ userMessage }}" wx:key="{{index}}" messageId="{{ item }}" bindmyevent="onMyEvent"/>
這樣事件監聽就寫好了,但是如何在組件中觸發呢,我們回到removelist.js中
繼續查看山脈的鏈接-微信開發文檔
Component({
properties: {},
methods: {
onTap: function(){
var myEventDetail = {} // detail對象,提供給事件監聽函數
var myEventOption = {} // 觸發事件的選項
this.triggerEvent('myevent', myEventDetail, myEventOption)
}
}
})
在removelist.js中通過:
this.triggerEvent('myevent',list)
前面參數,要和在 message.wxml設置的 bindmyevent,後面的myevent對應上
第二個參數就是我們 過濾剩下的list
給message傳過去之後
onMyEvent(ev){ this.setData({ userMessage : ev.detail });
通過這樣的設置出現了一個bug,就是我們刪除第一條信息的時候,直接把第二條刪掉了,第一條被留下來了
當我們查看數據庫的時候,留下來的就是第二條信息,但是在前端显示的是第一條信息留下,第二條信息沒了
要這樣修改:
onMyEvent(ev){ this.setData({ userMessage : [] },()=>{ this.setData({ userMessage : ev.detail }); }); }
先賦值為空,之後再次調用removelist,再把過濾的數組進行賦值
也就是全部清空之後,再重新渲染的
整個邏輯:
1、在數據庫中用戶的頭像和昵稱找到,然後獲取數據
2、點擊刪除按鈕的時候,彈出提示框,如果用戶點了缺點刪除的話,之後我們先查詢
找到之後,把那個消息在message列表中過濾掉
3、然後再重新的更新,之後就觸發子父通信,把更新之後的list傳給
4、父組件拿到removelist這組件的信息
拿到就更新我們的列表,這樣的話列表就發送了變化了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?